
 Data Structure
Data Structure Networking
Networking RDBMS
RDBMS Operating System
Operating System Java
Java MS Excel
MS Excel iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C Programming
C Programming C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP
- Selected Reading
- UPSC IAS Exams Notes
- Developer's Best Practices
- Questions and Answers
- Effective Resume Writing
- HR Interview Questions
- Computer Glossary
- Who is Who
What is Global Scheduling?
ILP-compilers have to extract acceptable instruction-level parallelism to make use of available hardware resources properly, specifically EUs. This is not a simple task for extremely parallel ILP-processors, including VLIW machines or highly superscalar processors. In specific, general-purpose programs, including operating systems or application programs, with their small fundamental block sizes and profoundly irregular parallelism, characterized using unpredictable branches make this task intensely hard or even unsolvable.
In this method, basic block schedulers cannot be predicted to extract sufficient parallelism to feed hugely parallel ILP-processors accurately. Therefore, compilers for parallelism-greedy ILP-processors have to make use of the very effective scheduling techniques, known as global scheduling.
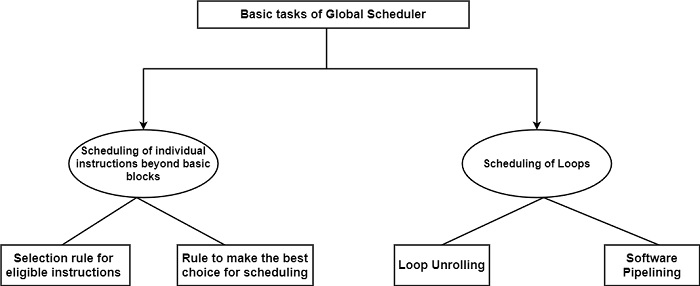
Global schedulers function beyond basic block boundaries and even throughout subsequent loop iterations, to extract as much parallelism as available. Global scheduling is fully a difficult task. First, there are two basic tasks to dispute with: scheduling individual instructions beyond basic blocks and scheduling loops as displayed in the following figure.
Beyond basic block scheduling
Basic block schedulers extract parallelism only inside the family of a basic block. In contrast, a global scheduler tries to perceive as many independent instructions in the control flow graph as available and to change them up along the graph until possible, even beyond basic block boundaries, to maintain several EUs in each cycle as working as possible. The difficult limit to transferring instruction up is proper data dependencies because false data dependencies may be removed by register renaming.
Mostly, global schedulers are not contented with the extent of parallelism achieved by only changing independent instructions before even beyond basic block boundaries. Further, a global scheduler generally tries to guess the result of unresolved conditional statements. Therefore, instruction along a guessed path will also be treated as a successor for code motions.
Individual instructions will be scheduled by most global schedulers in two phases, which is the same as what list schedulers do. First, global schedulers have to choose for each cycle the set of instructions that are acceptable for scheduling, following a chosen heuristics.
Second, further heuristics are required to select from the set of the eligible instructions. The scheduling decision can also contain a code motion, which is confined to solely one of the paths of the conditional branch is stated to be speculative. This designation emphasizes the case that these code motions are made below the assumption that the conditional branch follows the direction of the code movement and, therefore, the execution of the moved-up instruction will be beneficial.
Loop scheduling
Loops are an important source of parallelism for ILP-processors. Therefore, the consistency of the control structure can speed up computation. There are two basic approaches for scheduling loops, loop unrolling and software pipelining. The first is a straightforward, less sufficient approach distinguished from the second. Before their current use is concerned, loop unrolling is employed commonly as an aspect of more sophisticated scheduling methods, including software pipelining or trace scheduling.

2K+ Views
