
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
What is Basic block scheduling?
Basic block scheduling is the clean but least effective code scheduling technique. Therefore, only instructions inside a basic block are acceptable for reordering. As a result, the feasible speed-up is definite by both true data and control dependencies. Basic block schedulers are typically used for slightly and moderately parallel ILP-Processors, such as pipelined and early superscalar processors.
Most basic block schedulers for ILP-processors belong to the class of list schedulers, like the ones developed for the MIPS processors, Sparc processors, RS/6000, HP Precision Architecture, and DEC α 21064 (Kerns and Eggers, 1993, Gibbons and Muchnick, 1986).
List schedulers can be used in many contexts, including in operational research for scheduling tasks for assembly lines, in computing for scheduling tasks for multiprocessors, for scheduling microcode for horizontally microprogrammed machines, or as in this case, for scheduling instructions for ILP-processors.
List scheduler for basic block scheduling
A list scheduler is list-based and schedules items in steps. In each step, it first generates a list of items that are acceptable for the next schedule by using a selection rule and then uses a second rule to create the best option for the next schedule as displayed in the figure. In each step, one or more elements are scheduled.
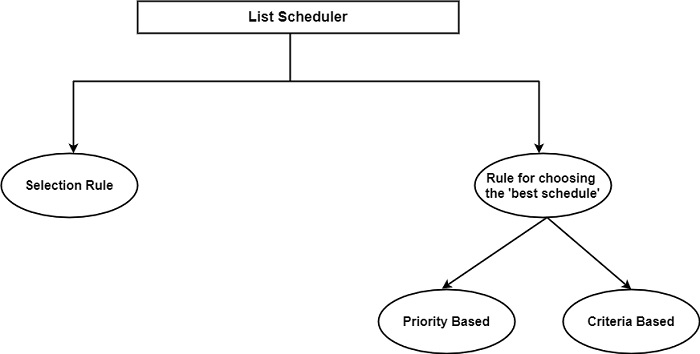
As far as List schedulers for basic block scheduling are concerned, the scheduled elements are instructions. Because the various scheduled instructions per step are concerned, code schedulers for both pipelined and superscalar processors deliver one scheduled instruction at a time.
The selection rule selects the set of eligible instructions for scheduling. Eligible instructions are dependency-free, that is, they have no predecessors in the DDG and the hardware needed resources are available.
The rule for choosing the ‘best schedule’ can view for the instruction most likely to generate interlocks with the follow-on instructions. This rule is generally a matter of heuristics.
Most schedulers execute these heuristics by seeking the critical execution path in the DDG and selecting a specific node related to the critical path for scheduling. But, ‘critical path’ can be interpreted in various methods and can be selected based on either preference or criteria.
A priority-based scheduler computes a priority value for each eligible instruction as per the chosen heuristics. In the method of basic blocklist schedulers for pipelined and superscalar processors, the ‘priority value’ of an eligible node is generally implicit as the length of the path consistent from the node under application to the end of the basic block.
After computing all priority values, the best choice is made by selecting the node with the largest priority value. A tie-breaking rule is required for the case when more than one node has the similar highest priority value.
In contrast, criteria-based schedulers use a set of selected criteria in a given order for the items to be scheduled. A ‘best choice’ is built by discovering the first item meets the highest available ranking criterion. The scheduler also has to give an additional criterion or rule for tie-breaking.

3K+ Views
