- NLP - Home
- NLP - Introduction
- NLP - Linguistic Resources
- NLP - Word Level Analysis
- NLP - Syntactic Analysis
- NLP - Semantic Analysis
- NLP - Word Sense Disambiguation
- NLP - Discourse Processing
- NLP - Part of Speech (PoS) Tagging
- NLP - Inception
- NLP - Information Retrieval
- NLP - Applications of NLP
- NLP - Python
- Natural Language Processing Resources
- NLP - Quick Guide
- NLP - Useful Resources
- NLP - Discussion
Natural Language Processing - Python
In this chapter, we will learn about language processing using Python.
The following features make Python different from other languages −
Python is interpreted − We do not need to compile our Python program before executing it because the interpreter processes Python at runtime.
Interactive − We can directly interact with the interpreter to write our Python programs.
Object-oriented − Python is object-oriented in nature and it makes this language easier to write programs because with the help of this technique of programming it encapsulates code within objects.
Beginner can easily learn − Python is also called beginners language because it is very easy to understand, and it supports the development of a wide range of applications.
Prerequisites
The latest version of Python 3 released is Python 3.7.1 is available for Windows, Mac OS and most of the flavors of Linux OS.
For windows, we can go to the link www.python.org/downloads/windows/ to download and install Python.
For MAC OS, we can use the link www.python.org/downloads/mac-osx/.
In case of Linux, different flavors of Linux use different package managers for installation of new packages.
For example, to install Python 3 on Ubuntu Linux, we can use the following command from terminal −
$sudo apt-get install python3-minimal
To study more about Python programming, read Python 3 basic tutorial Python 3
Getting Started with NLTK
We will be using Python library NLTK (Natural Language Toolkit) for doing text analysis in English Language. The Natural language toolkit (NLTK) is a collection of Python libraries designed especially for identifying and tag parts of speech found in the text of natural language like English.
Installing NLTK
Before starting to use NLTK, we need to install it. With the help of following command, we can install it in our Python environment −
pip install nltk
If we are using Anaconda, then a Conda package for NLTK can be built by using the following command −
conda install -c anaconda nltk
Downloading NLTKs Data
After installing NLTK, another important task is to download its preset text repositories so that it can be easily used. However, before that we need to import NLTK the way we import any other Python module. The following command will help us in importing NLTK −
import nltk
Now, download NLTK data with the help of the following command −
nltk.download()
It will take some time to install all available packages of NLTK.
Other Necessary Packages
Some other Python packages like gensim and pattern are also very necessary for text analysis as well as building natural language processing applications by using NLTK. the packages can be installed as shown below −
gensim
gensim is a robust semantic modeling library which can be used for many applications. We can install it by following command −
pip install gensim
pattern
It can be used to make gensim package work properly. The following command helps in installing pattern −
pip install pattern
Tokenization
Tokenization may be defined as the Process of breaking the given text, into smaller units called tokens. Words, numbers or punctuation marks can be tokens. It may also be called word segmentation.
Example
Input − Bed and chair are types of furniture.

We have different packages for tokenization provided by NLTK. We can use these packages based on our requirements. The packages and the details of their installation are as follows −
sent_tokenize package
This package can be used to divide the input text into sentences. We can import it by using the following command −
from nltk.tokenize import sent_tokenize
word_tokenize package
This package can be used to divide the input text into words. We can import it by using the following command −
from nltk.tokenize import word_tokenize
WordPunctTokenizer package
This package can be used to divide the input text into words and punctuation marks. We can import it by using the following command −
from nltk.tokenize import WordPuncttokenizer
Stemming
Due to grammatical reasons, language includes lots of variations. Variations in the sense that the language, English as well as other languages too, have different forms of a word. For example, the words like democracy, democratic, and democratization. For machine learning projects, it is very important for machines to understand that these different words, like above, have the same base form. That is why it is very useful to extract the base forms of the words while analyzing the text.
Stemming is a heuristic process that helps in extracting the base forms of the words by chopping of their ends.
The different packages for stemming provided by NLTK module are as follows −
PorterStemmer package
Porters algorithm is used by this stemming package to extract the base form of the words. With the help of the following command, we can import this package −
from nltk.stem.porter import PorterStemmer
For example, write would be the output of the word writing given as the input to this stemmer.
LancasterStemmer package
Lancasters algorithm is used by this stemming package to extract the base form of the words. With the help of following command, we can import this package −
from nltk.stem.lancaster import LancasterStemmer
For example, writ would be the output of the word writing given as the input to this stemmer.
SnowballStemmer package
Snowballs algorithm is used by this stemming package to extract the base form of the words. With the help of following command, we can import this package −
from nltk.stem.snowball import SnowballStemmer
For example, write would be the output of the word writing given as the input to this stemmer.
Lemmatization
It is another way to extract the base form of words, normally aiming to remove inflectional endings by using vocabulary and morphological analysis. After lemmatization, the base form of any word is called lemma.
NLTK module provides the following package for lemmatization −
WordNetLemmatizer package
This package will extract the base form of the word depending upon whether it is used as a noun or as a verb. The following command can be used to import this package −
from nltk.stem import WordNetLemmatizer
Counting POS TagsChunking
The identification of parts of speech (POS) and short phrases can be done with the help of chunking. It is one of the important processes in natural language processing. As we are aware about the process of tokenization for the creation of tokens, chunking actually is to do the labeling of those tokens. In other words, we can say that we can get the structure of the sentence with the help of chunking process.
Example
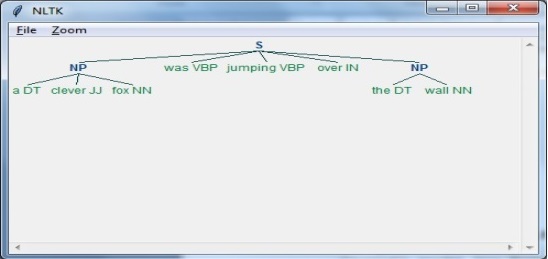
In the following example, we will implement Noun-Phrase chunking, a category of chunking which will find the noun phrase chunks in the sentence, by using NLTK Python module.
Consider the following steps to implement noun-phrase chunking −
Step 1: Chunk grammar definition
In this step, we need to define the grammar for chunking. It would consist of the rules, which we need to follow.
Step 2: Chunk parser creation
Next, we need to create a chunk parser. It would parse the grammar and give the output.
Step 3: The Output
In this step, we will get the output in a tree format.
Running the NLP Script
Start by importing the the NLTK package −
import nltk
Now, we need to define the sentence.
Here,
DT is the determinant
VBP is the verb
JJ is the adjective
IN is the preposition
NN is the noun
sentence = [("a", "DT"),("clever","JJ"),("fox","NN"),("was","VBP"),
("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]
Next, the grammar should be given in the form of regular expression.
grammar = "NP:{<DT>?<JJ>*<NN>}"
Now, we need to define a parser for parsing the grammar.
parser_chunking = nltk.RegexpParser(grammar)
Now, the parser will parse the sentence as follows −
parser_chunking.parse(sentence)
Next, the output will be in the variable as follows:-
Output = parser_chunking.parse(sentence)
Now, the following code will help you draw your output in the form of a tree.
output.draw()