- LightGBM - Home
- LightGBM - Overview
- LightGBM - Architecture
- LightGBM - Installation
- LightGBM - Core Parameters
- LightGBM - Boosting Algorithms
- LightGBM - Tree Growth Strategy
- LightGBM - Dataset Structure
- LightGBM - Binary Classification
- LightGBM - Regression
- LightGBM - Ranking
- LightGBM - Implementation in Python
- LightGBM - Parameter Tuning
- LightGBM - Plotting Functionality
- LightGBM - Early Stopping Training
- LightGBM - Feature Interaction Constraints
- LightGBM vs Other Boosting Algorithms
- LightGBM Useful Resources
- LightGBM - Quick Guide
- LightGBM - Useful Resources
- LightGBM - Discussion
LightGBM - vs Other Boosting Algorithms
LightGBM also works well with categorical datasets, as it handles categorical features using the splitting or grouping method. We converted all categorical characteristics to category data types to interface with categorical features in LightGBM. Once completed the categorical data will be handled automatically by removing the need to manage it manually.
LightGBM uses the GOSS method to sample data while training the decision tree. This method sets the variance of each data sample and arranges them in descending order. Data samples with low variance are already doing well thus they will be given less weightage when sampling the dataset.
So in this chapter we are going to focus on difference between the boosting algorithms and compare them with LightGBM.
Which Boosting Algorithm to you should Use?
Now, the question is simple: which of these machine learning algorithms should you choose if they all perform well, are fast, and deliver higher precision?!!
The answer to these questions cannot be a single boosting strategy, because each one is the greatest fit for the type of problem you will be working on.
For example, if you believe your dataset needs regularization, you can definitely use XGBoost. CatBoost and LightGBM are good options for dealing with categorical data. If you need more community support for the method, explore algorithms like XGBoost or Gradient Boosting, which were developed years ago.
Comparison Between Boosting Algorithms
After fitting the data to the model, all of the strategies provide relatively similar results. LightGBM looks to perform poorly when compared to other algorithms but XGBoost performs well in this case.
To show how each algorithm performed on identical data we can show the graph of their y_test and y_pred values.
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# Example data
y_test = np.linspace(0, 100, 100)
# Predictions with some noise
y_pred1 = y_test + np.random.normal(0, 10, 100)
y_pred2 = y_test + np.random.normal(0, 8, 100)
y_pred3 = y_test + np.random.normal(0, 6, 100)
y_pred4 = y_test + np.random.normal(0, 4, 100)
y_pred5 = y_test + np.random.normal(0, 2, 100)
fig, ax = plt.subplots(figsize=(11, 5))
# Plot each model's predictions
sns.lineplot(x=y_test, y=y_pred1, label='GradientBoosting', ax=ax)
sns.lineplot(x=y_test, y=y_pred2, label='XGBoost', ax=ax)
sns.lineplot(x=y_test, y=y_pred3, label='AdaBoost', ax=ax)
sns.lineplot(x=y_test, y=y_pred4, label='CatBoost', ax=ax)
sns.lineplot(x=y_test, y=y_pred5, label='LightGBM', ax=ax)
# Set labels
ax.set_xlabel('y_test', color='g')
ax.set_ylabel('y_pred', color='g')
# Display the plot
plt.show()
Output
Here is the result of the above code −
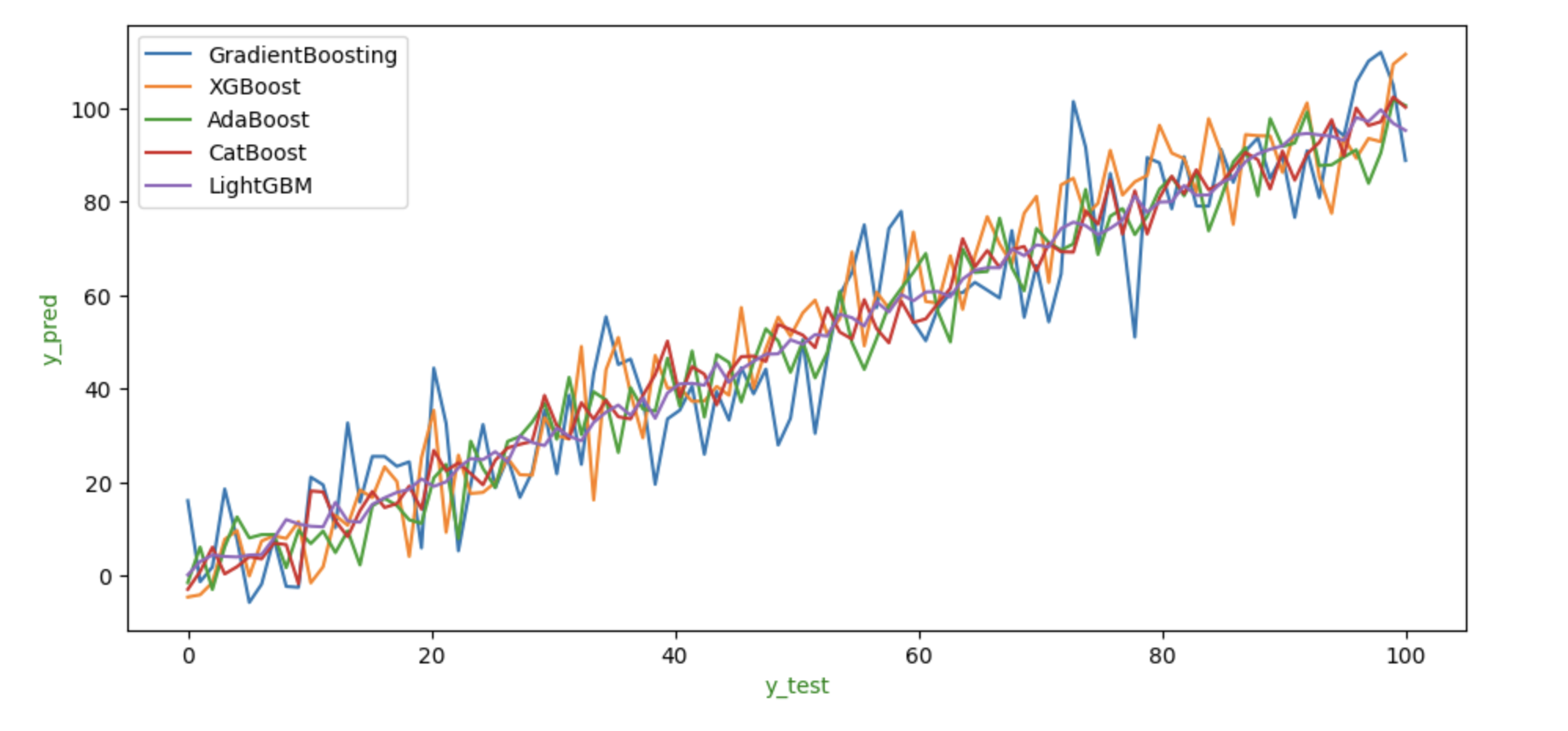
The image above shows the y_test and y_pred values expected by each method. We can see that LightGBM and CatBoost perform poorly when compared to other algorithms as they predict y_pred values that are much higher or lower than the other methods. As seen in the graph, XGBoost and GradientBoosting perform well all other algorithms on this data, with predictions that appear to be an average of all of them.
Difference between Different Boosting Algorithms
Here is the tabular difference between different boosting algorithms −
| Feature | Gradient Boosting | LightGBM | XGBoost | CatBoost | AdaBoost |
|---|---|---|---|---|---|
| Year Introduced | Not specific | 2017 | 2014 | 2017 | 1995 |
| Handling Categorical Data | Needs extra steps like one-hot encoding | Needs extra steps | No special steps needed | Automatically handles it | No special steps needed |
| Speed/Scalability | Medium | Fast | Fast | Medium | Fast |
| Memory Usage | Medium | Low | Medium | High | Low |
| Regularization (Prevents Overfitting) | No | Yes | Yes | Yes | No |
| Parallel Processing (Runs Multiple Tasks at Once) | No | Yes | Yes | Yes | No |
| GPU Support (Can Use Graphics Card) | No | Yes | Yes | Yes | No |
| Feature Importance (Shows Which Features Matter) | Yes | Yes | Yes | Yes | Yes |
