- LightGBM - Home
- LightGBM - Overview
- LightGBM - Architecture
- LightGBM - Installation
- LightGBM - Core Parameters
- LightGBM - Boosting Algorithms
- LightGBM - Tree Growth Strategy
- LightGBM - Dataset Structure
- LightGBM - Binary Classification
- LightGBM - Regression
- LightGBM - Ranking
- LightGBM - Implementation in Python
- LightGBM - Parameter Tuning
- LightGBM - Plotting Functionality
- LightGBM - Early Stopping Training
- LightGBM - Feature Interaction Constraints
- LightGBM vs Other Boosting Algorithms
- LightGBM Useful Resources
- LightGBM - Quick Guide
- LightGBM - Useful Resources
- LightGBM - Discussion
LightGBM - Architecture
LightGBM divides the tree leaf−wise, whereas other boosting algorithms build it level−wise. It chooses the leaf to split that it believes will result in the largest decrease in loss function. leaf−wise generates splits based on their contribution to the global loss rather than the loss over a specific branch, therefore it sometimes learns lower-error trees "faster" than level−wise.
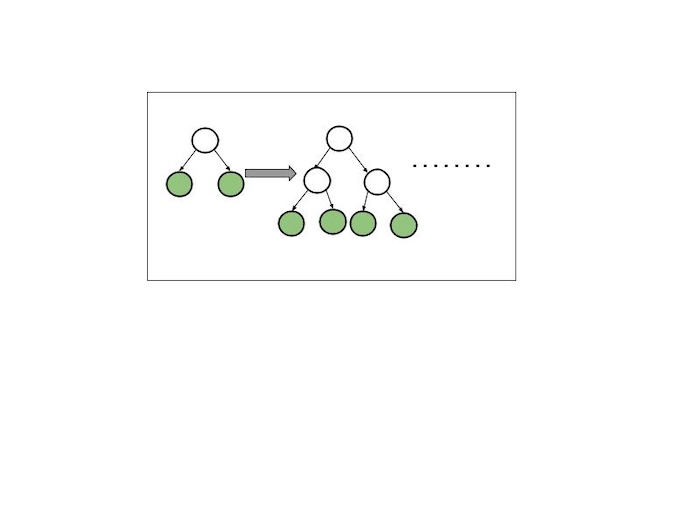
The diagram below shows the split order of a hypothetical binary leaf−wise tree to a hypothetical binary level−wise tree. It is interesting that the leaf−wise tree can have multiple orderings, whereas the level−wise tree always has the same order.
Leaf−wise Tree Growth
A leaf-wise tree grows by adding branches to the leaf (the end of a branch) that can remove the majority of errors. Consider it similar to developing a tree in a way that focuses on the areas where the model makes the most errors, adding branches just as needed.
This approach makes the tree deeper and more specific in the most important sections, which generally produces a more accurate model, but it can also result in a more complex tree.

Level−wise Tree Growth
A level−wise tree grows by spreading evenly new branches (leaves) over all levels. Consider a tree that grows one layer of branches at a time. It starts by adding branches at level 1, then progresses to level 2, and so on.
This maintains and reduces the tree, but it may not always be the best option because it does not focus on areas which need more detail.
Key Components of LightGBM Architecture
The architecture of LightGBM was created to optimize performance, memory efficiency, and model consistency. Here is a quick overview −
Leaf-Wise Tree Growth: LightGBM grows trees by extending the most important sections first, resulting in deeper, more accurate trees with overall trees.
Histogram-Based Learning: It speeds up training by categorizing data into bins (buckets), which reduce the time and memory needed to find the best splits.
Gradient-based One-Side Sampling (GOSS): GOSS chooses only the most important data points to speed up training while maintaining accuracy.
Exclusive Feature Bundling (EFB): EFB combines rarely seen features to save memory and speed up computations which makes it useful for data with a large number of features.
Parallel and GPU Processing: LightGBM can train models faster by using many CPU cores or GPUs, mainly for large datasets.
LightGBM's design uses leaf-wise tree growth, histogram-based learning, GOSS, and EFB methods to maximize performance and memory usage while maintaining high accuracy. Its parallel and GPU processing power make it perfect for efficiently completing large-scale machine learning tasks.
