- Beautiful Soup - Home
- Beautiful Soup - Overview
- Beautiful Soup - Web Scraping
- Beautiful Soup - Installation
- Beautiful Soup - Souping the Page
- Beautiful Soup - Kinds of objects
- Beautiful Soup - Inspect Data Source
- Beautiful Soup - Scrape HTML Content
- Beautiful Soup - Navigating by Tags
- Beautiful Soup - Find Elements by ID
- Beautiful Soup - Find Elements by Class
- Beautiful Soup - Find Elements by Attribute
- Beautiful Soup - Searching the Tree
- Beautiful Soup - Modifying the Tree
- Beautiful Soup - Parsing a Section of a Document
- Beautiful Soup - Find all Children of an Element
- Beautiful Soup - Find Element using CSS Selectors
- Beautiful Soup - Find all Comments
- Beautiful Soup - Scraping List from HTML
- Beautiful Soup - Scraping Paragraphs from HTML
- BeautifulSoup - Scraping Link from HTML
- Beautiful Soup - Get all HTML Tags
- Beautiful Soup - Get Text Inside Tag
- Beautiful Soup - Find all Headings
- Beautiful Soup - Extract Title Tag
- Beautiful Soup - Extract Email IDs
- Beautiful Soup - Scrape Nested Tags
- Beautiful Soup - Parsing Tables
- Beautiful Soup - Selecting nth Child
- Beautiful Soup - Search by text inside a Tag
- Beautiful Soup - Remove HTML Tags
- Beautiful Soup - Remove all Styles
- Beautiful Soup - Remove all Scripts
- Beautiful Soup - Remove Empty Tags
- Beautiful Soup - Remove Child Elements
- Beautiful Soup - find vs find_all
- Beautiful Soup - Specifying the Parser
- Beautiful Soup - Comparing Objects
- Beautiful Soup - Copying Objects
- Beautiful Soup - Get Tag Position
- Beautiful Soup - Encoding
- Beautiful Soup - Output Formatting
- Beautiful Soup - Pretty Printing
- Beautiful Soup - NavigableString Class
- Beautiful Soup - Convert Object to String
- Beautiful Soup - Convert HTML to Text
- Beautiful Soup - Parsing XML
- Beautiful Soup - Error Handling
- Beautiful Soup - Trouble Shooting
- Beautiful Soup - Porting Old Code
Beautiful Soup - Functions Reference
- Beautiful Soup - contents Property
- Beautiful Soup - children Property
- Beautiful Soup - string Property
- Beautiful Soup - strings Property
- Beautiful Soup - stripped_strings Property
- Beautiful Soup - descendants Property
- Beautiful Soup - parent Property
- Beautiful Soup - parents Property
- Beautiful Soup - next_sibling Property
- Beautiful Soup - previous_sibling Property
- Beautiful Soup - next_siblings Property
- Beautiful Soup - previous_siblings Property
- Beautiful Soup - next_element Property
- Beautiful Soup - previous_element Property
- Beautiful Soup - next_elements Property
- Beautiful Soup - previous_elements Property
- Beautiful Soup - find Method
- Beautiful Soup - find_all Method
- Beautiful Soup - find_parents Method
- Beautiful Soup - find_parent Method
- Beautiful Soup - find_next_siblings Method
- Beautiful Soup - find_next_sibling Method
- Beautiful Soup - find_previous_siblings Method
- Beautiful Soup - find_previous_sibling Method
- Beautiful Soup - find_all_next Method
- Beautiful Soup - find_next Method
- Beautiful Soup - find_all_previous Method
- Beautiful Soup - find_previous Method
- Beautiful Soup - select Method
- Beautiful Soup - append Method
- Beautiful Soup - extend Method
- Beautiful Soup - NavigableString Method
- Beautiful Soup - new_tag Method
- Beautiful Soup - insert Method
- Beautiful Soup - insert_before Method
- Beautiful Soup - insert_after Method
- Beautiful Soup - clear Method
- Beautiful Soup - extract Method
- Beautiful Soup - decompose Method
- Beautiful Soup - replace_with Method
- Beautiful Soup - wrap Method
- Beautiful Soup - unwrap Method
- Beautiful Soup - smooth Method
- Beautiful Soup - prettify Method
- Beautiful Soup - encode Method
- Beautiful Soup - decode Method
- Beautiful Soup - get_text Method
- Beautiful Soup - diagnose Method
Beautiful Soup Useful Resources
Beautiful Soup - Inspect Data Source
In order to scrape a web page with BeautifulSoup and Python, your first step for any web scraping project should be to explore the website that you want to scrape. So, first visit the website to understand the site structure before you start extracting the information that's relevant for you.
Let us visit TutorialsPoint's Python Tutorial home page. Open https://www.tutorialspoint.com/python/index.htm in your browser.
Use Developer tools can help you understand the structure of a website. All modern browsers come with developer tools installed.
If using Chrome browser, open the Developer Tools from the top-right menu button (⋮) and selecting More Tools → Developer Tools.
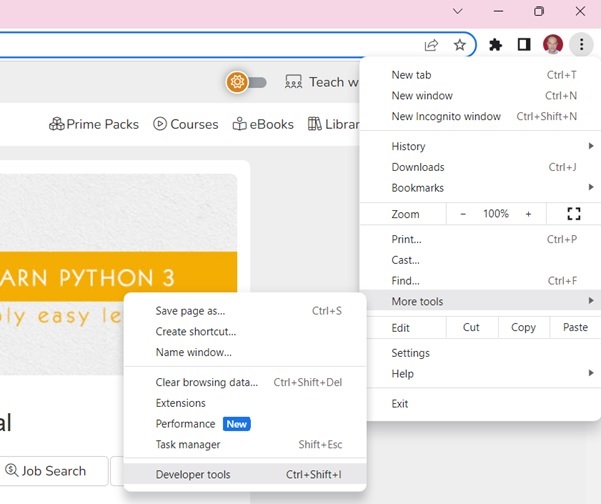
With Developer tools, you can explore the site's document object model (DOM) to better understand your source. Select the Elements tab in developer tools. You'll see a structure with clickable HTML elements.
The Tutorial page shows the table of contents in the left sidebar. Right click on any chapter and choose Inspect option.
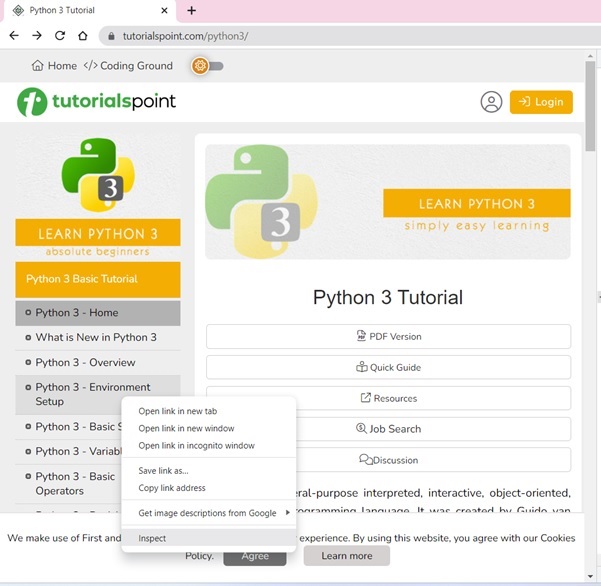
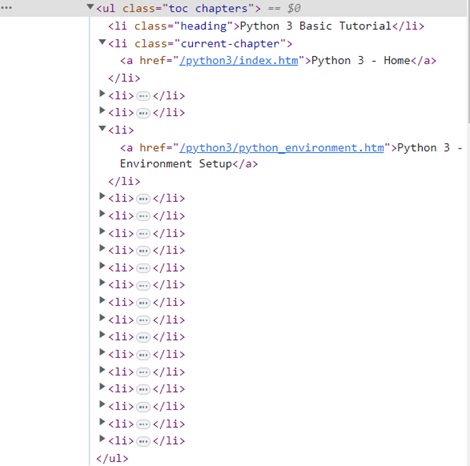
For the Elements tab, locate the tag that corresponds to the TOC list, as shown in the figure below −
Right click on the HTML element, copy the HTML element, and paste it in any editor.
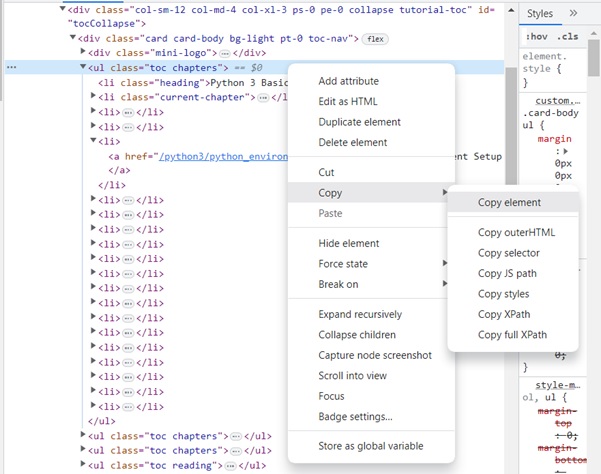
The HTML script of the <ul>..</ul> element is now obtained.
<ul class="toc chapters"> <li class="heading">Python 3 Basic Tutorial</li> <li class="current-chapter"><a href="/python3/index.htm">Python 3 - Home</a></li> <li><a href="/python3/python3_whatisnew.htm">What is New in Python 3</a></li> <li><a href="/python3/python_overview.htm">Python 3 - Overview</a></li> <li><a href="/python3/python_environment.htm">Python 3 - Environment Setup</a></li> <li><a href="/python3/python_basic_syntax.htm">Python 3 - Basic Syntax</a></li> <li><a href="/python3/python_variable_types.htm">Python 3 - Variable Types</a></li> <li><a href="/python3/python_basic_operators.htm">Python 3 - Basic Operators</a></li> <li><a href="/python3/python_decision_making.htm">Python 3 - Decision Making</a></li> <li><a href="/python3/python_loops.htm">Python 3 - Loops</a></li> <li><a href="/python3/python_numbers.htm">Python 3 - Numbers</a></li> <li><a href="/python3/python_strings.htm">Python 3 - Strings</a></li> <li><a href="/python3/python_lists.htm">Python 3 - Lists</a></li> <li><a href="/python3/python_tuples.htm">Python 3 - Tuples</a></li> <li><a href="/python3/python_dictionary.htm">Python 3 - Dictionary</a></li> <li><a href="/python3/python_date_time.htm">Python 3 - Date & Time</a></li> <li><a href="/python3/python_functions.htm">Python 3 - Functions</a></li> <li><a href="/python3/python_modules.htm">Python 3 - Modules</a></li> <li><a href="/python3/python_files_io.htm">Python 3 - Files I/O</a></li> <li><a href="/python3/python_exceptions.htm">Python 3 - Exceptions</a></li> </ul>
We can now load this script in a BeautifulSoup object to parse the document tree.