- Ingeniería de Software Tutorial
- Software - Inicio
- Software - Visión General
- Software - Ciclo de Vida de Desarrollo
- Software - Gestión del Proyecto
- Software - Requisitos
- Software - Básicas de Diseño
- Herramientas de Análisis y de Diseño
- Software - Estrategias de Diseño
- Software - Diseño de UI
- Software - Diseño Complejidad
- Software - Implementación
- Software - Visión General de Pruebas
- Software - Mantenimiento
- Software - CASE Herramientas
Herramientas de Análisis y de Diseño
El análisis y el diseño del Software incluye todas las actividades, que ayudan a transformar los requisitos requeridos en implementación. Los requisitos especifican la previsión operativa o no operativa del software. La especificación de requisitos se da en documentos con un lenguaje humano comprensible, con el que el ordenador no tiene ninguna relación.
El análisis y el diseño de Software es la fase intermedia, que ayuda a los requisitos legibles por humanos a ser transformados en códigos reales.
Veamos algunas herramientas de análisis y de diseño usadas por Ingenieros de software:
Diagrama de flujo de datos
Un Diagrama de flujo de datos (DFD), es una representación gráfica de los flujos de datos en un sistema de información. Es capaz de representar flujos de datos entrantes y salientes y datos almacenados. El DFD no menciona nada sobre la manera en que los datos floyen por el sistema.
Hay una gran diferencia entre el DFD y el Diagrama de flujo. El segundo representa el flujo de control en módulos de programación. Y el primero representa el flujo de información en el sistema en varios niveles. El DFD no contiene ningún elemento de control o de secuencia.
Tipos de DFD
Los Diagramas de flujo de datos son o físicos o lógicos
DFD lógico - Este tipo de DFD se concentra en el proceso y en el flujo de datos del sistema. Por ejemplo en los sistemas de software de Banking, se centar en cómo se mueven los datos entre distintas entidades.
DFD físico - Este tipo de DFD muestra cómo se implementa el flujo de datos en el sistema. Es más específico y cercano a la implementación.
Componentes del DFD
El DFD puede representar el origen, el destino, el almacenaje y el flujo de datos usando los siguientes componentes-

Snippet - Son el origen y destino de la información de datos. Se representan con rectángulos y sus respectivos nombres.
Proceso - Actividades y acciones sobre los datos son representadas con un círculo o con rectángulos redondeados.
Almacenamiento de datos - Hay dos tipos de almacenamiento de datos - puede representarse con un rectángulo sin sus lados cortos o con uno abierto por un lado, es decir con un lado menos.
Flujo de datos - El movimiento de los datos se muestra a través de flechas puntiagudas. El movimiento se muestra desde la base de la flecha que representa el origen y va hacia la cabeza de la flecha que representa su destino.
Niveles de DFD
Nivel 0 - El mayor nivel de abstracción del DFD se conoce como Nivel 0 DFD, el cual representa la totalidad de información del sistema en un diagrama ocultando todos los detalles subyacentes. Los Niveles 0 de DFD son también conocidos como nivel de contexto de DFD.
Nivel 1 - El nivel 0 DFD se desglosa en un Nivel 1 DFD más específico. El Nivel 1 DFD representa los módulos básicos del sistema así como el flujo de información entre los distintos módulos. El Nivel 1 DFD también alude a los procesos básicos y a las fuentes de información.
Nivel 2 - En este nivel el DFD muestra cómo fluyen los datos en los módulos mencionados en el Nivel 1.
El mayor nivel de DFD se puede transformar en niveles específicos de DFD más bajos pero con un entendimiento más preciso, a menos que el deaseado nivel de especificación se consiga.
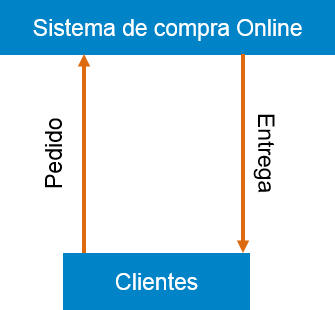
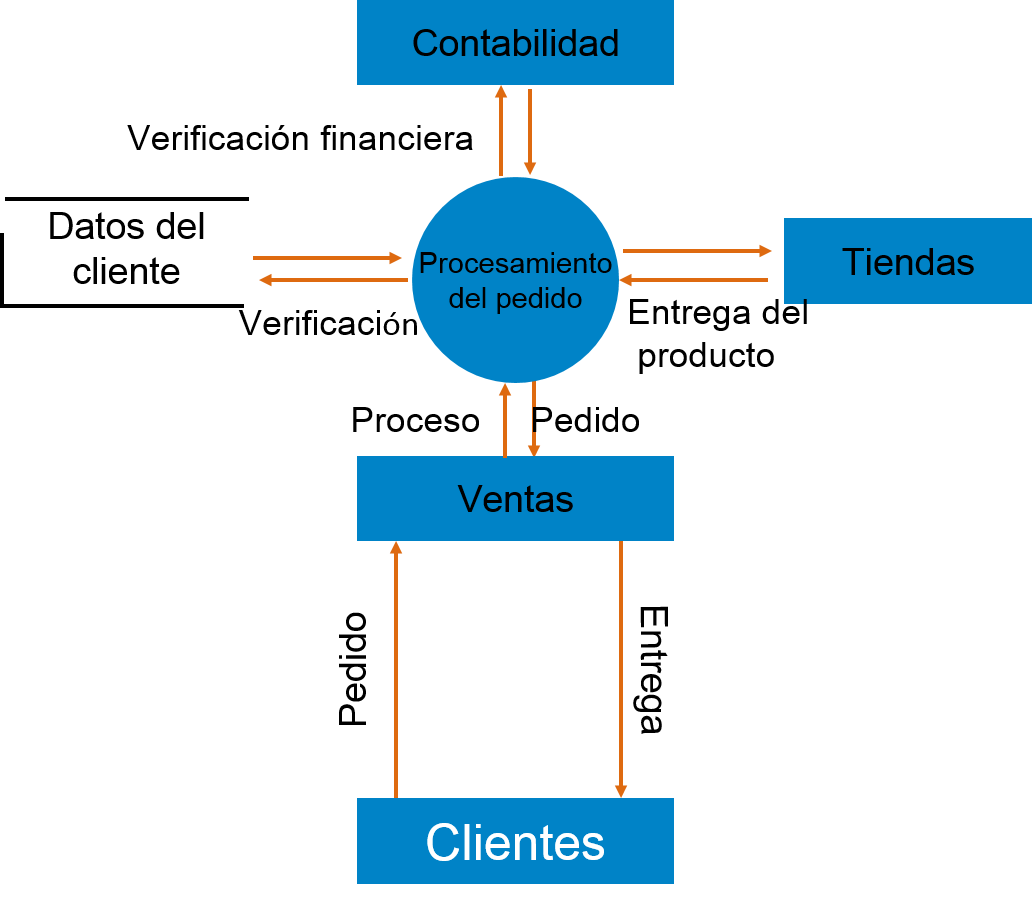
Esquema gráfico
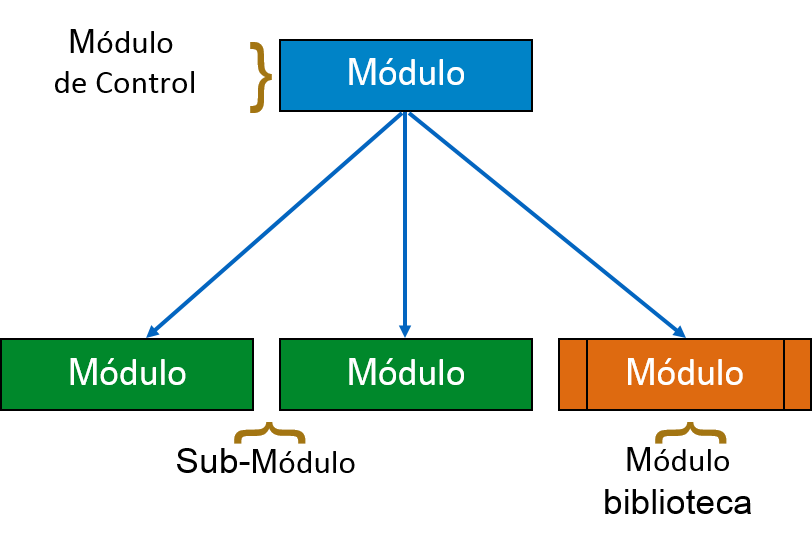
Un Esquema gráfico es un esquema derivado del Diagrama de flujo de datos. Representa el sistema con mucho más detalles que el DFD. Desglosa la totalidad del sistema en módulos funcionales más bajos, describe funciones y sub-funciones de cada módulo del sistema de una forma más exhaustiva y detallada que el DFD.
El esquema gráfico representa la estructura jerárquica de los módulos. En cada capa se lleva a cabo una tasca específica.
A continuación se exponen los símbolos usados para formar esquemas gráficos -
Módulo - Puede representar proceso, subrutina o tarea. El módulo de control se divide en más de un sub-módulo. Los módulos de la biblioteca son reutilizables y no comparables con ningún módulo.
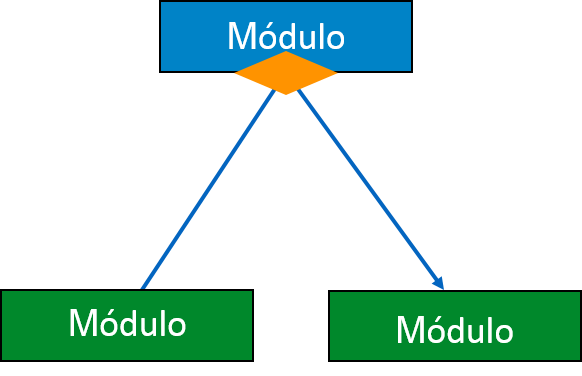
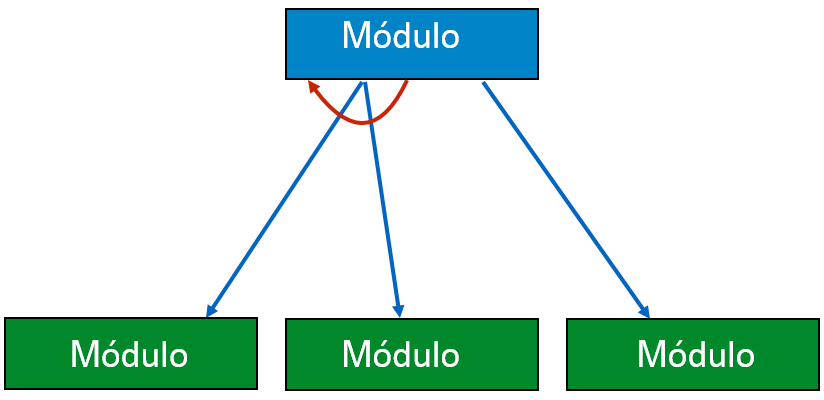
Condición - Se representa con un pequeño diamante en la base del módulo. Muestra que el módulo de control puede seleccionar cualquiera de las subrutinas en base a algunas condiciones.
Salto - Se trata de una flecha apuntando dentro del módulo para mostrar que el control saltará hacia el centro del sub-módulo.
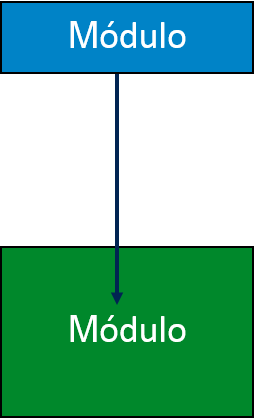
Curva - Un flecha curvada representa que hay una curva en el módulo. Todos los sub-módulos cubiertos por una curva repiten la ejecución del módulo.
Flujo de datos - Es representado con una flecha señalando un círculo vacío.
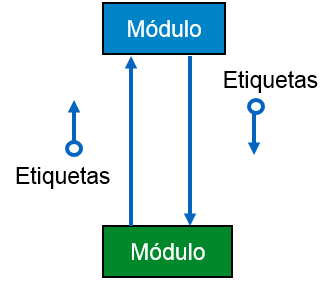
Flujo de control - Es representado con una flecha señalando un círculo relleno con color o diseños.
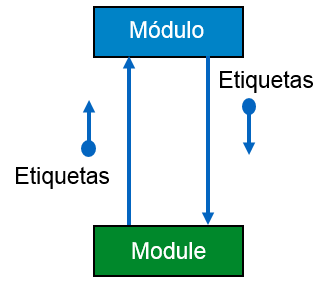
Diagrama HIPO
El Diagrama HIPO (Hierarchical Input Process Output) es una combinación de dos métodos organizados para analizar el sistema y proveer técnicas de documentación. El modelo HIPO fue desarrolado por la empresa IBM en el año 1970.
El Diagrama HIPO representa la jerarquía de los módulos en el sistema de Software. Los analistas de Software usan el Diagrama HIPO para obtener una visión en profundidad de las funciones del sistema. Descompone las funciones en sub funciones de manera jerárquica. Representa las funciones que ha hecho el sistema.
Los Diagramas HIPO son buenos para propósitos relacionados con la documentación. Su representación gráfica facilita a diseñadores y Directivos a entender de manera visual la estructura del sistema.
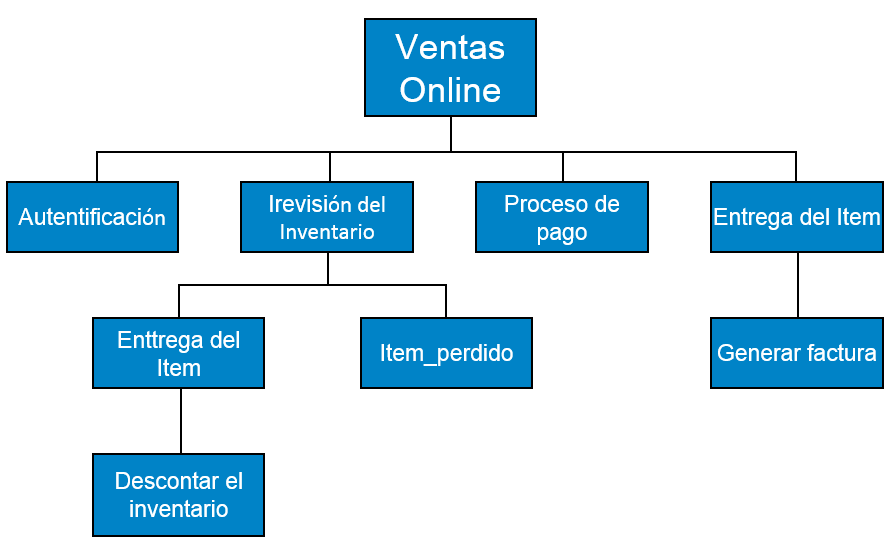
En contraste con el Diagrama IPO (Input Process Output), que representa el flujo de control y datos que se da en un módulo, el HIPO no aporta información sobre el flujo de datos ni del flujo de control.
Ejemplo
La dos partes de un Diagrama HIPO, la presentación jerárquica y el esquema IPO, son usadas para estructurar el diseño del programa de Software así como de su documentación.
'Structured English'
La mayor parte de los programadores no tienen un conocimiento total en lo que se refiere al software y solo confían en las instrucciones a seguir dictadas por sus jefes. Es responsabilidad de los altos Directivos de Software de proveeer información exhaustiva a los programadores para poder desarrolar códigos de forma rápida y acurada.
Otro tipo de metodologías que usan gráficos o diagramas, a veces pueden ser interpretadas de distinta forma por diferentes personas.
Por eso, tanto analistas como diseñadores de software intervienen en la problemática con herramientas como 'Structured English'. Esto es básicamente la descrpción de lo que se requiere para el código y cómo decodificarlo. 'Structured English' ayuda al programador a escribir códigos sin errores.
Otro tipo de metodologías que usan gráficos o diagramas, a veces pueden ser interpretadas de distinta forma por diferentes personas. En este tipo de casos, tanto 'Structured English' como 'Pseudo-Code' intentan resolver esta falta de entendimiento.
Structured English usa palabras normales en inglés en paradigmas de programación estructurada.No es el código más reciente pero es un tipo de descripcion que se requiere para codificar y saber cómo hacerlo. Las siguientes son algunas muestras de programación estructurada
IF-THEN-ELSE, DO-WHILE-UNTIL
Los analistas de software usan el mismo nombre para la variable y los datos, los cuales se almacenan en un Diccionario de Datos, haciendo más simple la escritura y el entendimiento de códigos.
Ejemplo
Cojamos el ejemplo de una autentificación de un cliente en el marco de una compra de producto online. El procedimiento para autentificar al cliente se puede escribir en Structured English como:
Enter Customer_Name SEEK Customer_Name in Customer_Name_DB file IF Customer_Name found THEN Call procedure USER_PASSWORD_AUTHENTICATE() ELSE PRINT error message Call procedure NEW_CUSTOMER_REQUEST() ENDIF
El tipo de lenguaje usado en inglés de una manera estructurada es como el inglés hablado en el día a día de forma oral. Este tipo de lenguaje no se puede implementar directamente como un lenguaje software. Structured English es independiente del lenguaje de programación.
Pseudo-Código
El Pseudo-Código se escribe de manera más cercana al lenguaje de programación. Se puede considerar como un lenguaje de programación popular, lleno de comentarios y de descripciones.
El Pseudo-Código ignora declaraciones variables pero se escriben usando construcciones reales de lenguage de programación, como el caso de C, Fortran, Pascal etc.
El Pseudo-Código contiene más detalles de programación que Structured English. Nos provee con una metodología para llevar a cabo la tarea, como si el ordenador estuviera ejecutando el código.
Ejemplo
Programa para imprimir Fibonacci a números n.
void function Fibonacci
Get value of n;
Set value of a to 1;
Set value of b to 1;
Initialize I to 0
for (i=0; i< n; i++)
{
if a greater than b
{
Increase b by a;
Print b;
}
else if b greater than a
{
increase a by b;
print a;
}
}
Tablas de decisión
Una tabla de decisión representa las condiciones y las respectivas para dirigirlas, en un formato tabular estructurado.
Es una poderosa herramienta para eliminar fallos y prevenir errores. Ayuda a agrupar información similar en la misma tabla y después combinando tablas obtiene convenientes y fáciles tomas de decisiones.
Creando Tablas de decisión
Para crear Tablas de decisión, el desarrollador de software debe seguir 4 pasos básicos:
Identificar todas las condiciones possibles para ser direccionadas
Determinar las acciones para todas las condiciones identificadas
Crear el máximo número possible de normas
Definir acciones a realizar para cada norma
Las Tablas de decisión deben ser verificadas por los consumidores finales para poder ser posteriormente simplificadas eliminando acciones y normas duplicadas.
Ejemplo
Veamos un simple ejemplo de un problema que nos ocurre día a día con nuestra conexión de Internet. Empezamos identificando todos los problemas que pueden surgir mientras iniciamos Internet y sus posibles soluciones.
Haremos un listado de todos los posibles problemas en una columna denominada 'condiciones' y otra sobre acciones esperadas en una columna llamada 'acciones'.
| Condiciones/Acciones | Normas | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Condiciones | Se muestra conectado | N | N | N | N | Y | Y | Y | Y |
| Los recursos de red funcionan | N | N | Y | Y | N | N | Y | Y | |
| Abre el sitio Web | Y | N | Y | N | Y | N | Y | N | |
| Acciones | Comprueba el cable de conexión a Internet | X | |||||||
| Examina el router | X | X | X | X | |||||
| Reinicia el navegador Web | X | ||||||||
| Contacta con el Servicio de atención al cliente | X | X | X | X | X | X | |||
| No realice ninguna acción /td> | |||||||||
Modelo entidad-relación
El Modelo o diagrama entidad-relación (a veces denominado por sus siglas en inglés, E-R "Entity relationship", o del español DER "Diagrama de Entidad Relación") es un tipo de modelo de base de datos basado en la noción de entidaddes mundiales reales y su relación entre ellas. Podemos trazar un mapa del escenario mundial real en en el modelo ER de base de datos. Este modelo crea un set de entidades con sus respectivos atributos, y un set de limitaciones y su relación entre ellas.
El modelo ER se usa frecuentemente para el diseño conceptual de Bases de datos. El modelo ER se puede representar de la siguienta manera :
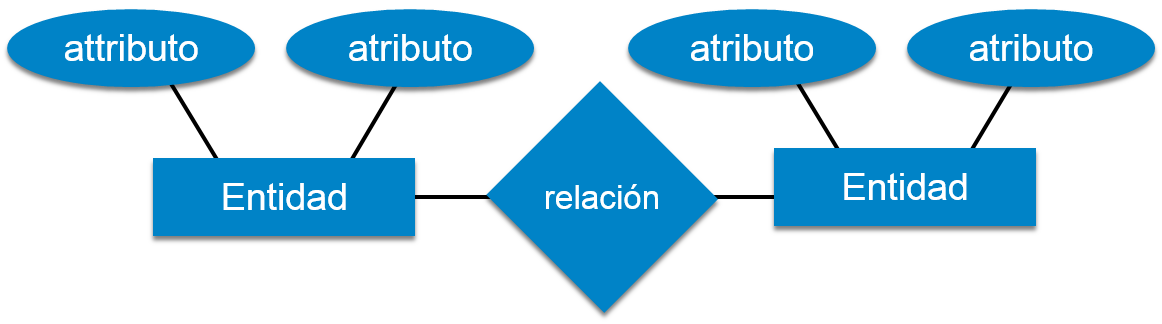
Entidad - Una entidad en modelo ER Model es un ser del mundo real, que tiene algunas propiedades llamadas atributos. Cada atributo se define por sus correspondientes sets de valores llamadosdominio.
Por ejemplo, considere una Base de datos de una escuela. En este caso, un estudiante seria una entidad. El estudiante tiene varios atributos como nombre, identidad, edad, clase, etc.
Relación - La asociación lógica entre entidades se denominarelación. La relaciones son esquematizadas con las entidades de varias maneras. Esquematizar la cardinalidad define el número de asociaciones entre dos entidades.
Esquematizar cardinalidad:
- uno a uno
- uno a varios
- varios a uno
- varios a varios
Diccionario de datos
El Diccionario de datos es la colección central de información sobre los datos. Almacena el significado y el origen de los datos, su relación con otros datos, su formato de uso etc. El diccionario de datos tiene rigurosas definiciones de todos los nombres para facilitar al Usuario y a los diseñadores de software.
El Diccionario de datos es frecuentemente mencionado como Repositorio Metadato (son datos que describen otros datos). Fue creado junto con el modelo de programa software DFD (Diagrama de flujo de datos) y se espera que se actualice cuando el DFD se cambie o sea actualizado.
Requisitos del Diccionario de datos
Los datos son mencionados a través del Diccionario de datos mientras se diseña e implementa el Software. El Diccionario de datos elimina posibles ambigüedades. Ayuda a mantenenr sincronizado el trabajo de los programadores y de los diseñadores mientras se usa el mismo objeto de referencia en todo el programa.
Los Diccionarios de datos aportan una vía de documentación para el completo sistema de Base de datos en un lugar. La validación del DFD se lleva a cabo usando Diccionarios de datos.
Contenidos
El diccionario de datos debe contener información sobre los siguientes
- Flujo de datos
- Estructura de los datos
- Elementos de los datos
- Almacenajes de datos
- Procesamiento de datos
El flujo de datos se describe por su significado en el DFD como se ha mencionado anteriormente, y representado de manera algebraica.
| = | Compuesto por |
|---|---|
| {} | Repetición |
| () | Opcional |
| + | y |
| [ / ] | O |
Ejemplo
Domicilio = Número + (calle / barrio) + Ciudad + estado
Identificación del Curso = Número del curso + Nombre del curso + Nivel del curso + Grado del curso
Elementos de los datos
Los elementos que conforman los datos son el nombre y la descripción de los mismos y de los elementos de control, el almacenaje interno y externo de datos, etc. con los siguientes detalles:
- Nombre principal
- Nombre secundario (Alias)
- Caso de uso (Cómo y donde usar)
- Descripción del contenido (anotación, etc. )
- Información adicional (valores actuales, límites, etc.)
Almacenamiento de datos
Almacena la información desde donde entran y salen los datos al y del sistema. El almacenamiento de datos puede incluir -
- Archivos
- Internos al software.
- Externos al software pero en la misma máquina.
- Externos al software y al sistema, ubicados en una máquina distinta.
- Tablas
- Acuerdo sobre nomenclatura
- Propiedad de Indexación
Procesamiento de datos
Hay dos tipos de procesamiento de datos:
- Lógico: Tal y como el usuario lo ve
- Físico: Tal y como el software lo ve