- Hadoop Tutorial
- Hadoop - Inicio
- Hadoop - Grandes Datos Generales
- Hadoop - Grandes Soluciones de Datos
- Hadoop: Introducción
- Hadoop - Configuración Entorno
- Hadoop - HDFS Descripción General
- Hadoop - HDFS Operaciones
- Hadoop - Referencia de Comandos
- Hadoop - MapReduce
- Hadoop - Streaming
- Hadoop - Varios Nodos de Clúster
Hadoop - HDFS Descripción General
Hadoop Sistema de archivos se ha desarrollado utilizando diseño de sistema de archivos distribuidos. Se ejecuta en hardware de productos básicos. A diferencia de otros sistemas distribuidos, HDFS es muy tolerantes y diseñado utilizando hardware de bajo coste.
HDFS tiene gran cantidad de datos y proporciona un acceso más fácil. Para almacenar estos datos de gran tamaño, los archivos se almacenan en varias máquinas. Estos archivos se almacenan en forma redundante para rescatar el sistema de posibles pérdidas de datos en caso de fallo. HDFS también permite que las aplicaciones de procesamiento en paralelo.
Características de los HDFS
- Es adecuado para el almacenamiento y procesamiento distribuido.
- Hadoop proporciona una interfaz de comandos para interactuar con HDFS.
- Los servidores de namenode datanode y ayudar a los usuarios a comprobar fácilmente el estado del clúster.
- Streaming el acceso a los datos del sistema de ficheros.
- HDFS proporciona permisos de archivo y la autenticación.
HDFS Arquitectura
A continuación se muestra la arquitectura de un sistema de archivos Hadoop.
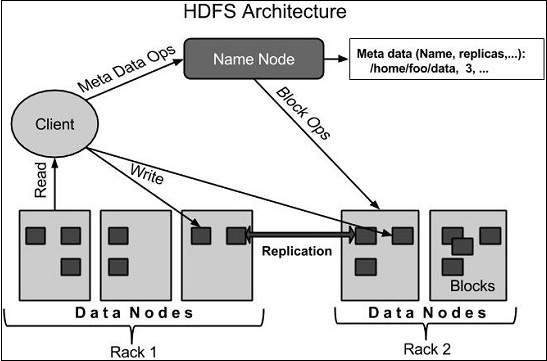
HDFS sigue el maestro-esclavo y arquitectura que tiene los siguientes elementos:
Namenode
El namenode es el hardware básico que contiene el sistema operativo GNU/Linux y el software namenode. Es un software que puede ejecutarse en hardware. El sistema que tiene la namenode actúa como el servidor maestro y no las siguientes tareas:
- Administra el espacio de nombres del sistema de archivos.
- Del cliente regula el acceso a los ficheros.
- Además, ejecuta las operaciones del sistema de archivos como el cambio de nombre, cierre y apertura de archivos y directorios.
Datanode
La datanode es un hardware de productos básicos con el sistema operativo GNU/Linux y software datanode. Para cada nodo (Commodity hardware/Sistema) de un clúster, habrá un datanode. Estos nodos gestionar el almacenamiento de datos de su sistema.
- Datanodes realizar operaciones de lectura y escritura de los sistemas de archivos, como por petición del cliente.
- Además, permiten realizar operaciones tales como creación, supresión, con lo que la replicación de acuerdo con las instrucciones del namenode.
Bloque
En general los datos de usuario se almacenan en los archivos de HDFS. El archivo en un sistema de archivos se divide en uno o más segmentos y/o almacenados en los nodos de datos. Estos segmentos se denominan como bloques. En otras palabras, la cantidad mínima de datos que HDFS puede leer o escribir se llama un bloque. El tamaño de bloque por defecto es de 64 MB, pero puede ser aumentado por la necesidad de cambiar de configuración HDFS.
Objetivos de los HDFS
Detección de fallos y recuperación : Desde los HDFS incluye un gran número de componentes de hardware, fallos de componentes es frecuente. HDFS Por lo tanto debe contar con mecanismos para una rápida y automática detección de fallos y recuperación.
Ingentes conjuntos : HDFS debe tener cientos de nodos por clúster para administrar las aplicaciones de grandes conjuntos de datos.
Hardware a una velocidad de transferencia de datos : una tarea solicitada se puede hacer de una manera eficiente, cuando el cálculo se lleva a cabo cerca de los datos. Especialmente en los casos en que grandes conjuntos de datos se trata, reduce el tráfico de red y aumenta el rendimiento.