
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
Workflow of MLOps
The purpose of MLOps, is to standardize and streamline the continuous delivery of high performing models in production by combining ML systems development (dev) with ML systems deployment (ops).
It aims to accelerate the process of putting machine learning models into operation, followed by their upkeep and monitoring. An ML Model must go through a number of phases before it is ready for production. These procedures guarantee that your model can appropriately scale for a wide user base. You'll run into that MLOps workflow.
Why MLOps?
Data ingestion, data preparation, model training, model tuning, model deployment, model monitoring, explainability, and many more complex processes are just a few of the complex elements that make up the machine learning lifecycle. MLOps provides you with efficiency, risk mitigation, and scalability.
Data teams can design models more quickly, deliver models of greater quality, and deploy and produce models more quickly thanks to MLOps. Additionally, it allows for massive scalability and management, allowing for the continuous integration, continuous delivery, and continuous deployment of thousands of models.
MLOps Workflow
The upper layer (pipeline) and the lower layer (driover) of the MLOps workflow are frequently separated into two fundamental levels. The driver consists of data, code, artefacts, middleware, and infrastructure, whereas the pipeline consists of developing, deploying, and monitoring. The drivers down below make the pipeline possible. You may simply prototype, test, and validate ML models with the aid of this workflow.
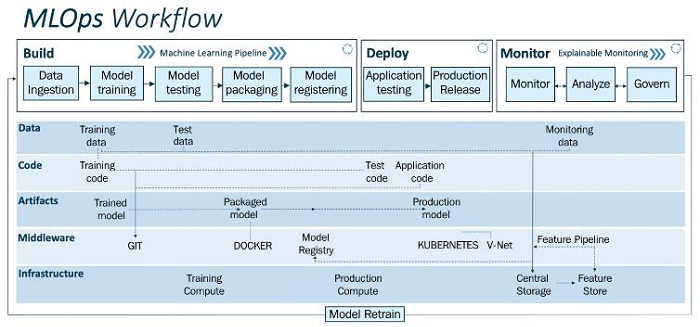
The following are the subparts of these layers ?
Pipeline
The top layer is the pipeline. It is utilised for model deployment and monitoring.
Build Module
This part is responsible for training, packaging and versioning part of the model.
Data ingestion ? It is a trigger step in the machine learning pipeline. By pulling data from diverse data sources (such as databases, data warehouses, or data lakes) and ingesting the necessary data for the model training stage, it addresses the volume, velocity, validity, and variety of data. Data validation and verification, which includes validation logic, are performed after the ingestion phase.
Model Training ? It contains of modular code or scripts that carry out all the usual ML operations, such as feature engineering and feature scaling, standardising, etc. To match the model to the dataset, hyper parameter adjustment is done while the ML model is being trained (training set). Manual completion of this phase is possible, however effective and automatic options include Grid Search or Random Search exist.
Model Testing ? Now that the model is trained and prepared, it?s performance will be evaluated on the premise of its predictive outcomes on the test data. The outputs will be within the kind of a metric score.
Model Packaging ? After the trained model has been tested in the previous step, the model can be serialized into a file or containerized (using Docker) to be exported to the production environment.
Model Registration ? The model will be registered and kept in the model registry once it has been containerized in the previous stage. A registered model is composed of one or more files that construct, represent, and execute the model. The model is trained and prepared to be deployed for the production environment at this point because the full ML pipeline has been completed.
Deploy Module
The operationalization of the ML models we created in the previous session is possible using the deploy module (build).
Testing ? Testing an ML model's performance and robustness is essential before putting it into use in production. As a result, we have the "application testing" phase where we thoroughly evaluate all the trained models for resilience and performance in a test environment that closely resembles a production environment. We deploy the models in the test environment (pre-production), which simulates the production environment, during the application testing process.
Release ? The previously evaluated models are now being used in production to offer useful functionality. Due to CI/CD pipelines, this production release gets deployed to the production environment.
Monitor Module
The deployed ML application is tracked and evaluated in the monitor phase. Predefined metrics can be used to evaluate performance.
-
Monitor ? Data integrity, model drift, and application performance are all monitored by the monitoring module, which also gathers vital information. Telemetry information can be used to track application performance.
It shows how a production system's device performance changed over time. The performance, health, and longevity of the production system can be monitored using telemetry data from the production system's accelerometer, gyroscope, humidity, magnetometer, pressure, and temperature sensors.
Analyze ? In order to increase the model's commercial relevance, model explainability approaches are used in real-time to analyse the model's fundamental properties, such as fairness, trust, bias, transparency, and error analysis.
-
Govern ? Monitoring and analysis are done to govern the deployed application to ensure that it performs at its peak for the benefit of the business (or the purpose of the ML system). We can create specific alerts and take specific measures to regulate the system after tracking and examining the production data.
We have now reached the MLOps pipeline's conclusion. All models developed, deployed, and maintained using the MLOps method are end-to-end traceable, and their lineage is recorded in order to trace the model's genesis. This includes the source code the model was developed from, the data it was used to train and test on, and the parameters it was constrained by.
Drivers
Data ? Any machine learning method can use structured or unstructured data. In ML applications, data management involves a number of procedures. Data is divided and versioned into training data, testing data, and monitoring data for the efficient operation of the ML pipeline.
Code ? The MLOps pipeline is powered by three key modules of code: training code, testing code, and application code. To ensure the MLOps pipeline functions properly, these scripts or pieces of code are run utilising the CI/CD and data pipelines.
Artifacts ? The MLOps pipeline produces artefacts including data, serialized models, code snippets, system logs, and details about the metrics used for training and testing ML models. All of these artefacts are necessary for the MLOps pipeline to operate well.
Middleware ? Computer software known as middleware provides functions to software programme that go beyond those provided by operating systems. Multiple apps can be used to automate and coordinate activities for the MLOps pipeline thanks to middleware services.
Infrastructure? The MLOps pipeline needs critical compute and storage resources in order to develop, test, and deploy the ML models. We can train, deploy, and monitor our ML models thanks to computational resources.

602 Views
