
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
What are Control dependencies?
Consider the following code sequence −
mul r1, r2, r3; jz zproc; sub r4, r7, r1; : zproc:load r1, x; :
In this example, the real direction of implementation depends on the result of the multiplication. This represents that the instructions following a conditional branch are dependent on it. In a similar method, all conditional control instructions, including conditional branches, calls, skips, etc. promulgate dependencies on the logically subsequent instructions is known as control dependencies.
The term general-purpose program stands for compilers, operating systems, or non-numeric application programs. The data indicates that that general-purpose program has a high percentage of branches, up to 20-30%. In contrast, scientific/technical programs contain fewer branches; the probable frequency is as low as 5-10%.
The ratio of conditional branches to branches seems to be quite stable in different programs, remaining within the range of 75-85%. As a consequence, the expected frequency of conditional branches in general-purpose code is about 20%, whereas in the scientific program it is merely 5-10%.
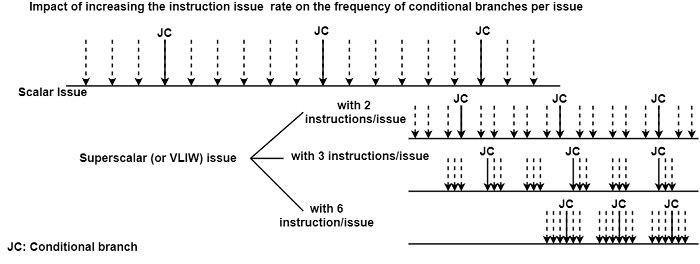
Frequent conditional branches impose a huge execution constraint on ILP-Processor. ILP-Processor can boost performance mainly by executing more and more instructions in parallel.
To achieve this, the processor must incorporate more and more EUs and is forced to raise the instruction issue rate. But the more instructions are issued in each cycle, the higher the probability of encountering a conditional control dependency in each cycle.
For example, let us consider a code sequence where every sixth instruction is a conditional branch, as shown in the figure. Let us assume that the code sequence does not contain any data or resource dependencies, so the instruction issue mechanism can issue two, three, or six instructions at will. When the issue rate will be increased from two instructions/cycle, each third, second or even every issue will contain a conditional branch, giving rise to possibly more and more severe performance degradation.
Control dependency graphs
Just as data dependencies, control dependencies can also be defined by directed graphs. Instructions transferring control dependencies are generally defined by nodes with two successor arcs, as displayed in the figure. The outgoing arcs define the true (T) and false (F) paths and are generally labeled accordingly.
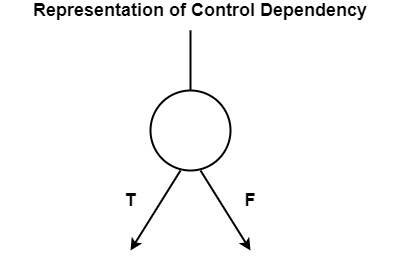
Nodes with only one outgoing arc define either an operational instruction or a sequence of conditional branch-free operational instructions (straight-line code). The general method for directed graphs representing control dependencies is Control Dependency Graph (CDG).

2K+ Views
