- Natural Language Toolkit - Home
- Natural Language Toolkit - Introduction
- Natural Language Toolkit - Getting Started
- Natural Language Toolkit - Tokenizing Text
- Training Tokenizer & Filtering Stopwords
- Looking up words in Wordnet
- Stemming & Lemmatization
- Natural Language Toolkit - Word Replacement
- Synonym & Antonym Replacement
- Corpus Readers and Custom Corpora
- Basics of Part-of-Speech (POS) Tagging
- Natural Language Toolkit - Unigram Tagger
- Natural Language Toolkit - Combining Taggers
- Natural Language Toolkit - More NLTK Taggers
- Natural Language Toolkit - Parsing
- Chunking & Information Extraction
- Natural Language Toolkit - Transforming Chunks
- Natural Language Toolkit - Transforming Trees
- Natural Language Toolkit - Text Classification
- Natural Language Toolkit Resources
- Natural Language Toolkit - Quick Guide
- Natural Language Toolkit - Useful Resources
- Natural Language Toolkit - Discussion
Natural Language Toolkit - Unigram Tagger
What is Unigram Tagger?
As the name implies, unigram tagger is a tagger that only uses a single word as its context for determining the POS(Part-of-Speech) tag. In simple words, Unigram Tagger is a context-based tagger whose context is a single word, i.e., Unigram.
How does it work?
NLTK provides a module named UnigramTagger for this purpose. But before getting deep dive into its working, let us understand the hierarchy with the help of following diagram −
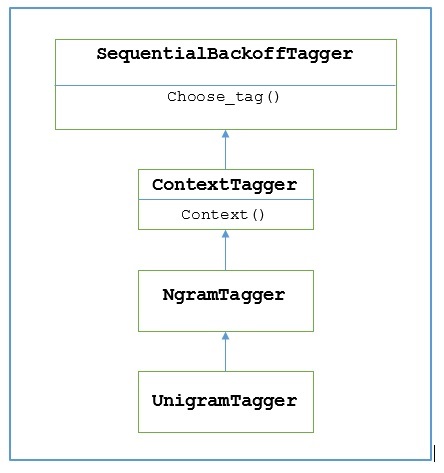
From the above diagram, it is understood that UnigramTagger is inherited from NgramTagger which is a subclass of ContextTagger, which inherits from SequentialBackoffTagger.
The working of UnigramTagger is explained with the help of following steps −
As we have seen, UnigramTagger inherits from ContextTagger, it implements a context() method. This context() method takes the same three arguments as choose_tag() method.
The result of context() method will be the word token which is further used to create the model. Once the model is created, the word token is also used to look up the best tag.
In this way, UnigramTagger will build a context model from the list of tagged sentences.
Training a Unigram Tagger
NLTKs UnigramTagger can be trained by providing a list of tagged sentences at the time of initialization. In the example below, we are going to use the tagged sentences of the treebank corpus. We will be using first 2500 sentences from that corpus.
Example
First import the UniframTagger module from nltk −
from nltk.tag import UnigramTagger
Next, import the corpus you want to use. Here we are using treebank corpus −
from nltk.corpus import treebank
Now, take the sentences for training purpose. We are taking first 2500 sentences for training purpose and will tag them −
train_sentences = treebank.tagged_sents()[:2500]
Next, apply UnigramTagger on the sentences used for training purpose −
Uni_tagger = UnigramTagger(train_sentences)
Take some sentences, either equal to or less taken for training purpose i.e. 2500, for testing purpose. Here we are taking first 1500 for testing purpose −
test_sentences = treebank.tagged_sents()[1500:] Uni_tagger.evaluate(test_sents)
Output
0.8942306156033808
Here, we got around 89 percent accuracy for a tagger that uses single word lookup to determine the POS tag.
Complete implementation example
from nltk.tag import UnigramTagger from nltk.corpus import treebank train_sentences = treebank.tagged_sents()[:2500] Uni_tagger = UnigramTagger(train_sentences) test_sentences = treebank.tagged_sents()[1500:] Uni_tagger.evaluate(test_sentences)
Output
0.8942306156033808
Overriding the context model
From the above diagram showing hierarchy for UnigramTagger, we know all the taggers that inherit from ContextTagger, instead of training their own, can take a pre-built model. This pre-built model is simply a Python dictionary mapping of a context key to a tag. And for UnigramTagger, context keys are individual words while for other NgramTagger subclasses, it will be tuples.
We can override this context model by passing another simple model to the UnigramTagger class instead of passing training set. Let us understand it with the help of an easy example below −
Example
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
Override_tagger = UnigramTagger(model = {Vinken : NN})
Override_tagger.tag(treebank.sents()[0])
Output
[
('Pierre', None),
('Vinken', 'NN'),
(',', None),
('61', None),
('years', None),
('old', None),
(',', None),
('will', None),
('join', None),
('the', None),
('board', None),
('as', None),
('a', None),
('nonexecutive', None),
('director', None),
('Nov.', None),
('29', None),
('.', None)
]
As our model contains Vinken as the only context key, you can observe from the output above that only this word got tag and every other word has None as a tag.
Setting a minimum frequency threshold
For deciding which tag is most likely for a given context, the ContextTagger class uses frequency of occurrence. It will do it by default even if the context word and tag occur only once, but we can set a minimum frequency threshold by passing a cutoff value to the UnigramTagger class. In the example below, we are passing the cutoff value in previous recipe in which we trained a UnigramTagger −
Example
from nltk.tag import UnigramTagger from nltk.corpus import treebank train_sentences = treebank.tagged_sents()[:2500] Uni_tagger = UnigramTagger(train_sentences, cutoff = 4) test_sentences = treebank.tagged_sents()[1500:] Uni_tagger.evaluate(test_sentences)
Output
0.7357651629613641