
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
Everything about FLAIR: A Framework for NLP
FLAIR, which stands for Forward-Looking AI Reasoning, is a sophisticated framework for Natural Language Processing (NLP) that has gained prominence in recent years. FLAIR, with its tremendous features and cutting-edge approaches, transforms the way we approach NLP tasks, improving accuracy, efficiency, and variety.
In this detailed article, we delve into the complexities of FLAIR, exploring its basic components and features and demonstrating its excellent performance through real-world examples.
What is FLAIR?
FLAIR is a comprehensive framework for NLP developed by Zalando Research. It aims to provide researchers and developers with a flexible and efficient toolset for various text analysis tasks. FLAIR is distinguished by its emphasis on cutting-edge sequence labeling, text categorization, and language modeling. To offer accurate and efficient results, it blends the best characteristics of deep learning with classic machine learning techniques.
FLAIR is made up of two primary parts: the FLAIR library and the FLAIR Embeddings. The FLAIR library includes a variety of pre-configured models and utilities for common NLP tasks. FLAIR Embeddings, on the other hand, offers a library of word embeddings and contextual string embeddings trained on huge datasets.
FLAIR Model
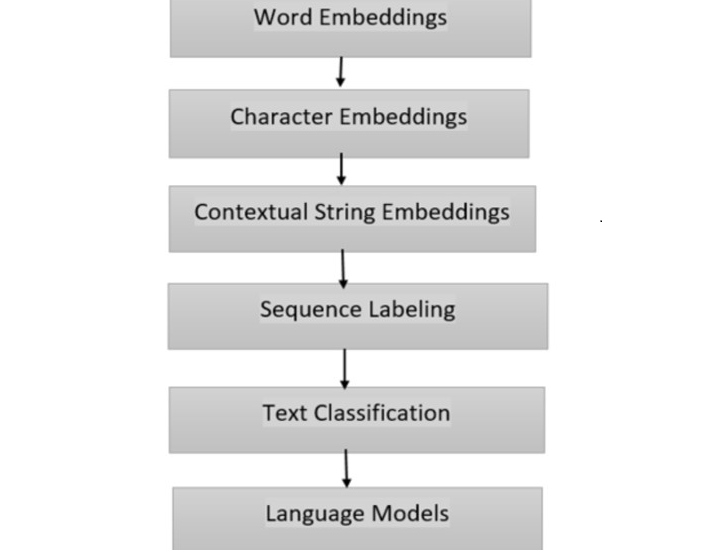
The FLAIR Model Diagram illustrates the flow of information through the different components of FLAIR, providing a visual representation of how text is processed and analyzed. The diagram showcases the following components ?
Word Embeddings ? These embeddings capture the semantic and syntactic information of individual words in a given text. They are generated using techniques such as Word2Vec and GloVe.
Character Embeddings ? FLAIR also incorporates character-level embeddings to capture the morphological information of words. This helps the model handle out-of-vocabulary words and improves its robustness.
Contextual String Embeddings ? FLAIR leverages contextual string embeddings to encode the meaning of words based on their surrounding context. This allows the model to capture word sense disambiguation and contextual information effectively.
Sequence Labeling ? FLAIR utilizes sequence labeling models, such as bidirectional LSTMs (Long Short-Term Memory), to assign labels to individual tokens in a text. This component is crucial for tasks like named entity recognition and part-of-speech tagging.
Text Classification ? FLAIR supports text classification tasks using methods like convolutional neural networks (CNNs) and self-attention mechanisms. This component enables the model to classify documents into different categories or predict sentiment.
Language Models ? FLAIR incorporates language models that capture the global context of a text. These models, such as transformers, are pre-trained on large corpora and can generate contextualized word representations.
Contextual String Embeddings for Sequence Labeling
Contextual String Embeddings in FLAIR are representations of words or tokens in a text that capture their meaning based on the surrounding context. These embeddings encode the semantic and syntactic information of individual words by considering the entire sentence or sequence of tokens they appear in. This contextual information is vital for sequence labeling tasks in NLP, such as named entity recognition (NER) and part-of-speech (POS) tagging.
Example
Let's look at an illustration of contextual string embeddings in action: "The cat sat on the mat." The context in which a word appears in this sentence affects its interpretation and meaning. For instance, the word "mat" can refer to a floor covering while the word "cat" might refer to a feline mammal.
In FLAIR, the Contextual String Embeddings model, typically based on transformer architectures like BERT or RoBERTa, processes the entire sentence at once. It takes into account the context of each word within the sentence and generates a dense vector representation, or embedding, for that word.
Here's a diagrammatic representation of how Contextual String Embeddings work for sequence labeling ?
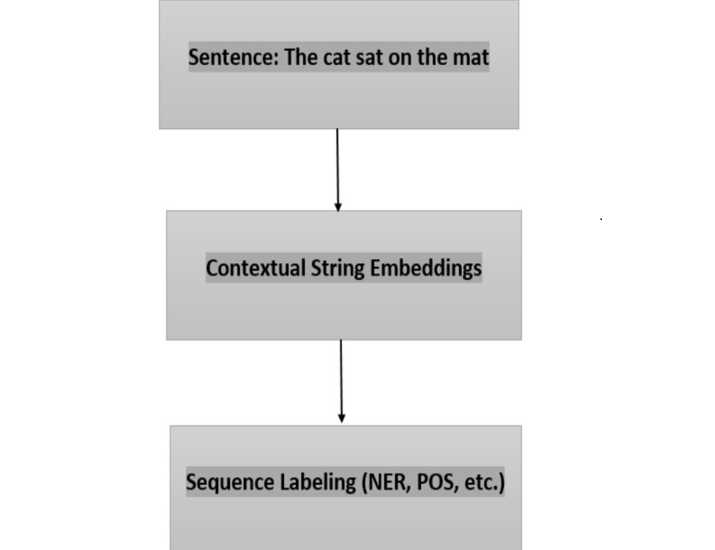
In the diagram, the input sentence "The cat sat on the mat." is fed into the Contextual String Embeddings component, which processes the sentence as a whole. The Contextual String Embeddings model generates dense vector representations for each word in the sentence, capturing their contextual meaning.
These Contextual String Embeddings are then used as input for sequence labeling tasks like Named Entity Recognition (NER) or Part-of-Speech (POS) tagging. The sequence labeling component applies specific labels to each word in the sentence based on its context and the task at hand.
For example, in a Named Entity Recognition task, the sequence labeling component can identify and classify words like "cat" as an entity of type "ANIMAL" and "mat" as an entity of type "OBJECT."
Contextual String Embeddings play a crucial role in enhancing the performance of sequence labeling tasks by leveraging the contextual information of words within a sentence. They enable the model to make more accurate predictions based on the surrounding words, resulting in improved accuracy and understanding of the text.
FLAIR's Training Process
Training FLAIR models involves a series of steps to optimize performance. The process typically starts with data preprocessing and annotation. This includes cleaning the text, tokenizing it into individual words, and labeling specific entities or categories.
Once the data is prepared, FLAIR employs deep learning techniques to train the models. This involves feeding the labeled data into the model and updating its parameters iteratively. Techniques like backpropagation and gradient descent are used to optimize the model's performance on the given task.
FLAIR's Application Areas
FLAIR finds applications in various NLP domains. Some of the key application areas where FLAIR excels are ?
Sentiment Analysis
Sentiment analysis involves determining the sentiment expressed in a piece of text, whether it's positive, negative, or neutral. FLAIR's models can accurately analyze sentiment in social media posts, customer reviews, and online discussions.
Named Entity Recognition
Named entity recognition (NER) aims to identify and classify named entities in a text, such as names of people, organizations, locations, and dates. FLAIR's sequence labeling models excel in NER tasks, delivering accurate results for information extraction.
Text Classification
Text classification involves categorizing documents into predefined classes or topics. FLAIR provides robust models for text classification, enabling tasks like spam detection, topic modeling, and document organization.
FLAIR vs. Other NLP Frameworks
FLAIR stands out among other NLP frameworks like SpaCy and NLTK due to its unique features and advantages. Here are some key points of comparison ?
Flexibility ? FLAIR offers a more flexible and modular approach compared to other frameworks, allowing researchers and developers to experiment with various components and configurations.
State-of-the-Art Results ? FLAIR consistently achieves state-of-the-art results on various NLP tasks due to its focus on advanced deep learning techniques and pre-trained models.
Ease of Use ? FLAIR provides a user-friendly interface and comprehensive API documentation, making it accessible to both beginners and experts in the field.
However, it's important to note that each framework has its strengths and weaknesses. While FLAIR excels in sequence labeling and language modeling, SpaCy and NLTK have their own unique features for other NLP tasks.
FLAIR in Action: Real-World Examples
To illustrate the remarkable capabilities of FLAIR, let's explore some practical applications where it shines ?
Named Entity Recognition (NER)
Named Entity Recognition is a fundamental NLP task that involves identifying and classifying named entities in text. FLAIR's contextual embeddings enable it to excel in NER by capturing the nuanced relationships between words and their surrounding context. The framework can accurately identify named entities such as persons, organizations, locations, and more, even in complex and ambiguous contexts.
Consider the following example sentence ?
"Apple Inc. is planning to open a new store in downtown San Francisco."
FLAIR would correctly recognize "Apple Inc." as an organization and "San Francisco" as a location, showcasing its proficiency in NER tasks.
Sentiment Analysis
Sentiment analysis involves determining the sentiment expressed in a piece of text, whether it be positive, negative, or neutral. FLAIR's contextual embeddings, combined with document pooling techniques, allow it to capture the subtle nuances of sentiment by considering the overall context and dependencies between words.
Let's take the following sentence as an example ?
"The movie was absolutely fantastic; I loved every minute of it!"
FLAIR would accurately identify the positive sentiment expressed in this sentence, showcasing its effectiveness in sentiment analysis tasks.
Conclusion
In conclusion, FLAIR is a comprehensive NLP framework that offers powerful solutions for text analysis tasks. With its advanced models, flexible architecture, and state-of-the-art performance, FLAIR has become a go-to choice for researchers and developers in the NLP community. Whether you're working on sentiment analysis, named entity recognition, or text classification, FLAIR provides the tools and resources you need to achieve accurate and efficient results.

908 Views
