- Python Text Processing - Home
- Python Text Processing - Introduction
- Python Text Processing - Environment
- Python Text Processing - String Immutability
- Python Text Processing - Sorting Lines
- Python Text Processing - Counting Token in Paragraphs
- Python Text Processing - Binary ASCII Conversion
- Python Text Processing - Strings as Files
- Python Text Processing - Backward File Reading
- Python Text Processing - Filter Duplicate Words
- Python Text Processing - Extract Emails from Text
- Python Text Processing - Extract URL from Text
- Python Text Processing - Pretty Print
- Python Text Processing - State Machine
- Python Text Processing - Capitalize and Translate
- Python Text Processing - Tokenization
- Python Text Processing - Remove Stopwords
- Python Text Processing - Synonyms and Antonyms
- Python Text Processing - Translation
- Python Text Processing - Word Replacement
- Python Text Processing - Spelling Check
- Python Text Processing - WordNet Interface
- Python Text Processing - Corpora Access
- Python Text Processing - Tagging Words
- Python Text Processing - Chunks and Chinks
- Python Text Processing - Chunk Classification
- Python Text Processing - Classification
- Python Text Processing - Bigrams
- Python Text Processing - Process PDF
- Python Text Processing - Process Word Document
- Python Text Processing - Reading RSS feed
- Python Text Processing - Sentiment Analysis
- Python Text Processing - Search and Match
- Python Text Processing - Text Munging
- Python Text Processing - Text wrapping
- Python Text Processing - Frequency Distribution
- Python Text Processing - Summarization
- Python Text Processing - Stemming Algorithms
- Python Text Processing - Constrained Search
Python Text Processing Useful Resources
- Python Text Processing - Quick Guide
- Python Text Processing - Useful Resources
- Python Text Processing - Discussion
Python Text Processing - Chunks and Chinks
Chunking is the process of grouping similar words together based on the nature of the word. In the below example we define a grammar by which the chunk must be generated. The grammar suggests the sequence of the phrases like nouns and adjectives etc. which will be followed when creating the chunks. The pictorial output of chunks is shown below.
Example - Chunking
main.py
import nltk
sentence = [("The", "DT"), ("small", "JJ"), ("red", "JJ"),("flower", "NN"),
("flew", "VBD"), ("through", "IN"), ("the", "DT"), ("window", "NN")]
grammar = "NP: {<nn>?<dt>*<jj>}"
cp = nltk.RegexpParser(grammar)
result = cp.parse(sentence)
print(result)
result.draw()
Output
When we run the above program we get the following output −
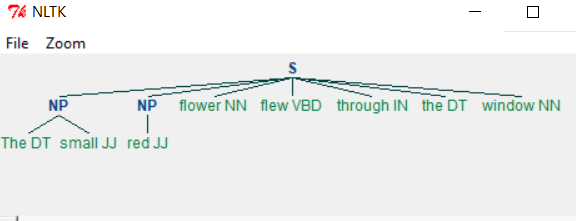
Example - Changing the Grammar
Changing the grammar, we get a different output as shown below.
main.py
import nltk
sentence = [("The", "DT"), ("small", "JJ"), ("red", "JJ"),("flower", "NN"),
("flew", "VBD"), ("through", "IN"), ("the", "DT"), ("window", "NN")]
grammar = "NP: {<nn>?<dt>*<jj>}"
chunkprofile = nltk.RegexpParser(grammar)
result = chunkprofile.parse(sentence)
print(result)
result.draw()
Output
When we run the above program we get the following output −
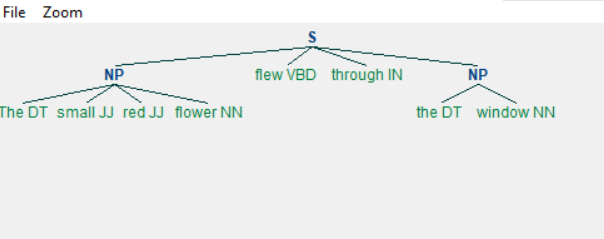
Chinking
Chinking is the process of removing a sequence of tokens from a chunk. If the sequence of tokens appears in the middle of the chunk, these tokens are removed, leaving two chunks where they were already present.
main.py
import nltk
sentence = [("The", "DT"), ("small", "JJ"), ("red", "JJ"),
("flower", "NN"), ("flew", "VBD"), ("through", "IN"),
("the", "DT"), ("window", "NN")]
grammar = r"""
NP:
{<.>+} # Chunk everything
}<jj>+{ # Chink sequences of JJ and NN
"""
chunkprofile = nltk.RegexpParser(grammar)
result = chunkprofile.parse(sentence)
print(result)
result.draw()
Output
When we run the above program, we get the following output −
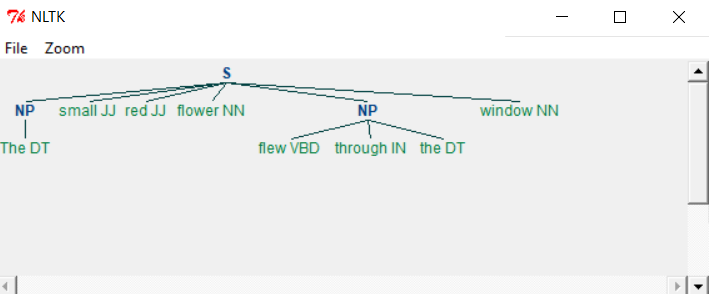
As you can see the parts meeting the criteria in grammar are left out from the Noun phrases as separate chunks. This process of extracting text not in the required chunk is called chinking.
