- Home
- Introduction
- Getting Started
- CPU and GPU
- CNTK - Sequence Classification
- CNTK - Logistic Regression Model
- CNTK - Neural Network (NN) Concepts
- CNTK - Creating First Neural Network
- CNTK - Training the Neural Network
- CNTK - In-Memory and Large Datasets
- CNTK - Measuring Performance
- Neural Network Classification
- Neural Network Binary Classification
- CNTK - Neural Network Regression
- CNTK - Classification Model
- CNTK - Regression Model
- CNTK - Out-of-Memory Datasets
- CNTK - Monitoring the Model
- CNTK - Convolutional Neural Network
- CNTK - Recurrent Neural Network
- Microsoft Cognitive Toolkit Resources
- Microsoft Cognitive Toolkit - Quick Guide
- Microsoft Cognitive Toolkit - Resources
- Microsoft Cognitive Toolkit - Discussion
CNTK - Measuring Performance
This chapter will explain how to measure the model performance in CNKT.
Strategy to validate model performance
After building a ML model, we used to train it using a set of data samples. Because of this training our ML model learns and derive some general rules. The performance of ML model matters when we feed new samples, i.e., different samples than provided at the time of training, to the model. The model behaves differently in that case. It may be worse at making a good prediction on those new samples.
But the model must work well for new samples as well because in production environment we will get different input than we used sample data for training purpose. Thats the reason, we should validate the ML model by using a set of samples different from the samples we used for training purpose. Here, we are going to discuss two different techniques for creating a dataset for validating a NN.
Hold-out dataset
It is one of the easiest methods for creating a dataset to validate a NN. As name implies, in this method we will be holding back one set of samples from training (say 20%) and using it to test the performance of our ML model. Following diagram shows the ratio between training and validation samples −
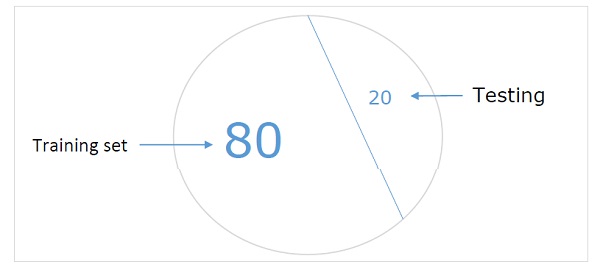
Hold-out dataset model ensures that we have enough data to train our ML model and at the same time we will have a reasonable number of samples to get good measurement of models performance.
In order to include in the training set and test set, its a good practice to choose random samples from the main dataset. It ensures an even distribution between training and test set.
Following is an example in which we are producing own hold-out dataset by using train_test_split function from the scikit-learn library.
Example
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
# Here above test_size = 0.2 represents that we provided 20% of the data as test data.
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
classifier_knn = KNeighborsClassifier(n_neighbors=3)
classifier_knn.fit(X_train, y_train)
y_pred = classifier_knn.predict(X_test)
# Providing sample data and the model will make prediction out of that data
sample = [[5, 5, 3, 2], [2, 4, 3, 5]]
preds = classifier_knn.predict(sample)
pred_species = [iris.target_names[p] for p in preds] print("Predictions:", pred_species)
Output
Predictions: ['versicolor', 'virginica']
While using CNTK, we need to randomise the order of our dataset each time we train our model because −
Deep learning algorithms are highly influenced by the random-number generators.
The order in which we provide the samples to NN during training greatly affects its performance.
The major downside of using the hold-out dataset technique is that it is unreliable because sometimes we get very good results but sometimes, we get bad results.
K-fold cross validation
To make our ML model more reliable, there is a technique called K-fold cross validation. In nature K-fold cross validation technique is same as the previous technique, but it repeats it several times-usually about 5 to 10 times. Following diagram represents its concept −
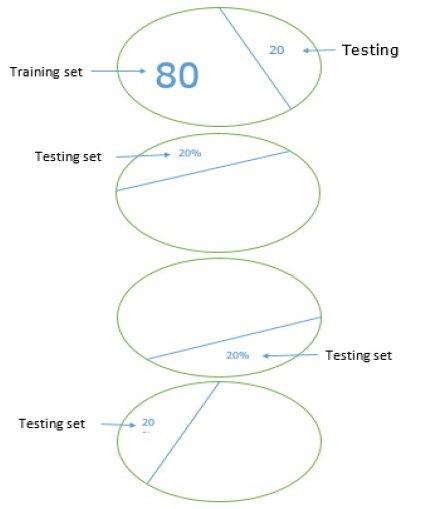
Working of K-fold cross validation
The working of K-fold cross validation can be understood with the help of following steps −
Step 1 − Like in Hand-out dataset technique, in K-fold cross validation technique, first we need to split the dataset into a training and test set. Ideally, the ratio is 80-20, i.e. 80% of training set and 20% of test set.
Step 2 − Next, we need to train our model using the training set.
Step 3 −At last, we will be using the test set to measure the performance of our model. The only difference between Hold-out dataset technique and k-cross validation technique is that the above process gets repeated usually for 5 to 10 times and at the end the average is calculated over all the performance metrics. That average would be the final performance metrics.
Let us see an example with a small dataset −
Example
from numpy import array
from sklearn.model_selection import KFold
data = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0])
kfold = KFold(5, True, 1)
for train, test in kfold.split(data):
print('train: %s, test: %s' % (data[train],(data[test]))
Output
train: [0.1 0.2 0.4 0.5 0.6 0.7 0.8 0.9], test: [0.3 1. ] train: [0.1 0.2 0.3 0.4 0.6 0.8 0.9 1. ], test: [0.5 0.7] train: [0.2 0.3 0.5 0.6 0.7 0.8 0.9 1. ], test: [0.1 0.4] train: [0.1 0.3 0.4 0.5 0.6 0.7 0.9 1. ], test: [0.2 0.8] train: [0.1 0.2 0.3 0.4 0.5 0.7 0.8 1. ], test: [0.6 0.9]
As we see, because of using a more realistic training and test scenario, k-fold cross validation technique gives us a much more stable performance measurement but, on the downside, it takes a lot of time when validating deep learning models.
CNTK does not support for k-cross validation, hence we need to write our own script to do so.
Detecting underfitting and overfitting
Whether, we use Hand-out dataset or k-fold cross-validation technique, we will discover that the output for the metrics will be different for dataset used for training and the dataset used for validation.
Detecting overfitting
The phenomenon called overfitting is a situation where our ML model, models the training data exceptionally well, but fails to perform well on the testing data, i.e. was not able to predict test data.
It happens when a ML model learns a specific pattern and noise from the training data to such an extent, that it negatively impacts that models ability to generalise from the training data to new, i.e. unseen data. Here, noise is the irrelevant information or randomness in a dataset.
Following are the two ways with the help of which we can detect weather our model is overfit or not −
The overfit model will perform well on the same samples we used for training, but it will perform very bad on the new samples, i.e. samples different from training.
The model is overfit during validation if the metric on the test set is lower than the same metric, we use on our training set.
Detecting underfitting
Another situation that can arise in our ML is underfitting. This is a situation where, our ML model didnt model the training data well and fails to predict useful output. When we start training the first epoch, our model will be underfitting, but will become less underfit as training progress.
One of the ways to detect, whether our model is underfit or not is to look at the metrics for training set and test set. Our model will be underfit if the metric on the test set is higher than the metric on the training set.
