- Lucene - Home
- Lucene - Overview
- Lucene - Environment Setup
- Lucene - First Application
- Lucene - Indexing Classes
- Lucene - Searching Classes
- Lucene - Indexing Process
- Lucene - Search Operation
- Lucene - Sorting
Lucene - Indexing Operations
- Lucene - Indexing Operations
- Lucene - Add Document
- Lucene - Update Document
- Lucene - Delete Document
- Lucene - Field Options
Lucene - Query Programming
- Lucene - Query Programming
- Lucene - TermQuery
- Lucene - TermRangeQuery
- Lucene - PrefixQuery
- Lucene - BooleanQuery
- Lucene - PhraseQuery
- Lucene - WildCardQuery
- Lucene - FuzzyQuery
- Lucene - MatchAllDocsQuery
- Lucene - MatchNoDocsQuery
- Lucene - RegexpQuery
Lucene - Analysis
- Lucene - Analysis
- Lucene - WhitespaceAnalyzer
- Lucene - SimpleAnalyzer
- Lucene - StopAnalyzer
- Lucene - StandardAnalyzer
- Lucene - KeywordAnalyzer
- Lucene - CustomAnalyzer
- Lucene - EnglishAnalyzer
- Lucene - FrenchAnalyzer
- Lucene - SpanishAnalyzer
Lucene - Resources
Lucene - Quick Guide
Lucene - Overview
Lucene is a simple yet powerful Java-based Search library. It can be used in any application to add search capability to it. Lucene is an open-source project. It is scalable. This high-performance library is used to index and search virtually any kind of text. Lucene library provides the core operations which are required by any search application like Indexing and Searching.
How Search Application works?
A Search application performs all or a few of the following operations −
| Step | Title | Description |
|---|---|---|
| 1 | Acquire Raw Content |
The first step of any search application is to collect the target contents on which search application is to be conducted. |
| 2 | Build the document |
The next step is to build the document(s) from the raw content, which the search application can understand and interpret easily. |
| 3 | Analyze the document |
Before the indexing process starts, the document is to be analyzed as to which part of the text is a candidate to be indexed. This process is where the document is analyzed. |
| 4 | Indexing the document |
Once documents are built and analyzed, the next step is to index them so that this document can be retrieved based on certain keys instead of the entire content of the document. Indexing process is similar to indexes at the end of a book where common words are shown with their page numbers so that these words can be tracked quickly instead of searching the complete book. |
| 5 | User Interface for Search |
Once a database of indexes is ready then the application can make any search. To facilitate a user to make a search, the application must provide a user a mean or a user interface where a user can enter text and start the search process. |
| 6 | Build Query |
Once a user makes a request to search a text, the application should prepare a Query object using that text which can be used to inquire index database to get the relevant details. |
| 7 | Search Query |
Using a query object, the index database is then checked to get the relevant details and the content documents. |
| 8 | Render Results |
Once the result is received, the application should decide on how to show the results to the user using User Interface. How much information is to be shown at first look and so on. |
Apart from these basic operations, a search application can also provide administration user interface and help administrators of the application to control the level of search based on the user profiles. Analytics of search results is another important and advanced aspect of any search application.
Lucene's Role in Search Application
Lucene plays role in steps 2 to step 7 mentioned above and provides classes to do the required operations. In a nutshell, Lucene is the heart of any search application and provides vital operations pertaining to indexing and searching. Acquiring contents and displaying the results is left for the application part to handle.
In the next chapter, we will perform a simple Search application using Lucene Search library.
Lucene - Environment
This chapter will guide you on how to prepare a development environment to start your work with Lucene. It will also teach you how to set up JDK on your machine before you set up Apache Lucene −
Setup Java Development Kit (JDK)
You can download the latest version of SDK from Oracle's Java site − Java SE Downloads. You will find instructions for installing JDK in downloaded files, follow the given instructions to install and configure the setup. Finally set PATH and JAVA_HOME environment variables to refer to the directory that contains java and javac, typically java_install_dir/bin and java_install_dir respectively.
If you are running Windows and have installed the JDK in C:\jdk-24, you would have to put the following line in your C:\autoexec.bat file.
set PATH=C:\jdk-24;%PATH% set JAVA_HOME=C:\jdk-24
Alternatively, on Windows NT/2000/XP, you will have to right-click on My Computer, select Properties → Advanced → Environment Variables. Then, you will have to update the PATH value and click the OK button.
On Unix (Solaris, Linux, etc.), if the SDK is installed in /usr/local/jdk-24 and you use the C shell, you will have to put the following into your .cshrc file.
setenv PATH /usr/local/jdk-24/bin:$PATH setenv JAVA_HOME /usr/local/jdk-24
Alternatively, if you use an Integrated Development Environment (IDE) like Borland JBuilder, Eclipse, IntelliJ IDEA, or Sun ONE Studio, you will have to compile and run a simple program to confirm that the IDE knows where you have installed Java. Otherwise, you will have to carry out a proper setup as given in the document of the IDE.
Popular Java Editors
To write your Java programs, you need a text editor. There are many sophisticated IDEs available in the market. But for now, you can consider one of the following −
Notepad − On Windows machine, you can use any simple text editor like Notepad (Recommended for this tutorial), TextPad.
Netbeans − It is a Java IDE that is open-source and free, which can be downloaded from www.netbeans.org/index.html.
Eclipse − It is also a Java IDE developed by the eclipse open-source community and can be downloaded from www.eclipse.org.
Step 3 - Setup Lucene Framework Libraries
If the startup is successful, then you can proceed to set up your Lucene framework. Following are the simple steps to download and install the framework on your machine.
https://downloads.apache.org/lucene/java/10.2.2/
Make a choice whether you want to install Lucene on Windows, or Unix and then proceed to the next step to download the .zip file for windows and .tz file for Unix.
Download the suitable version of Lucene framework binaries from https://downloads.apache.org/lucene/java/10.2.2/.
At the time of writing this tutorial, I downloaded lucene-10.2.2.tgz on my Windows machine and extracted to C:\lucene.
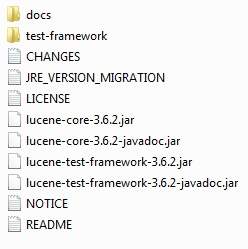
You will find all the Lucene libraries in the directory C:\lucene\modules. Make sure you set your CLASSPATH variable on this directory properly otherwise, you will face problem while running your application. If you are using Eclipse, then it is not required to set CLASSPATH because all the setting will be done through Eclipse.
Once you are done with this last step, you are ready to proceed for your first Example which you will see in the next chapter.
Lucene - First Application
In this chapter, we will learn the actual programming with Lucene Framework. Before you start writing your first example using Lucene framework, you have to make sure that you have set up your Lucene environment properly as explained in Lucene - Environment Setup tutorial. It is recommended you have the working knowledge of Eclipse IDE.
Let us now proceed by writing a simple Search Application which will print the number of search results found. We'll also see the list of indexes created during this process.
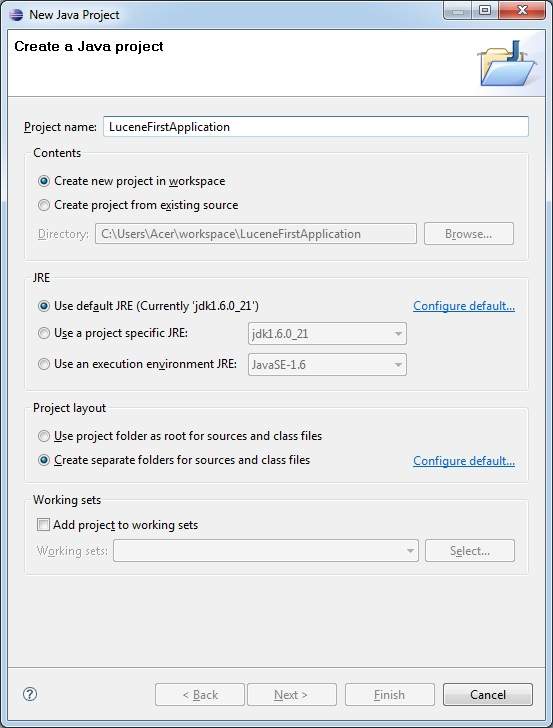
Step 1 - Create Java Project
The first step is to create a simple Java Project using Eclipse IDE. Follow the option File > New -> Project and finally select Java Project wizard from the wizard list. Now name your project as LuceneFirstApplication using the wizard window as follows −
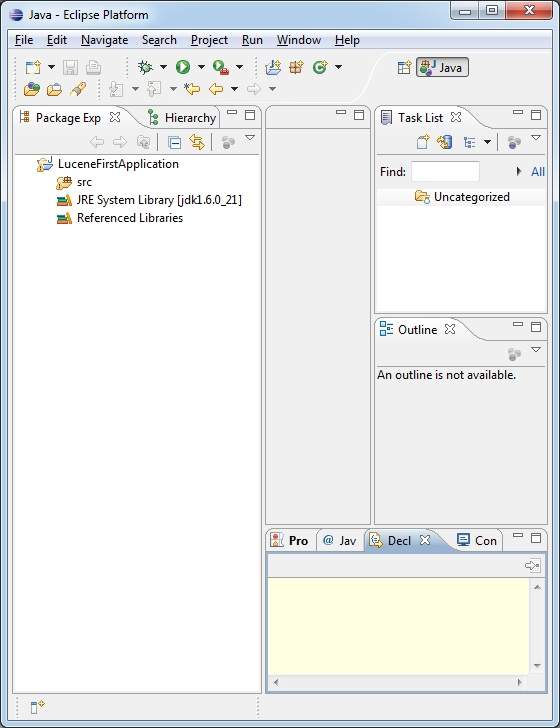
Once your project is created successfully, you will have following content in your Project Explorer −
Step 2 - Add Required Libraries
Let us now add Lucene core Framework library in our project. To do this, right click on your project name LuceneFirstApplication and then follow the following option available in context menu: Build Path -> Configure Build Path to display the Java Build Path window as follows −
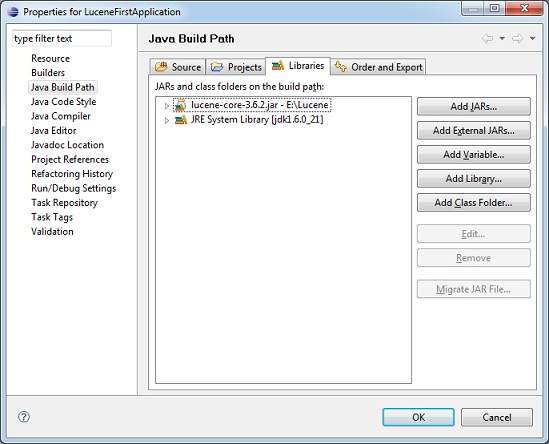
Now use Add External JARs button available under Libraries tab to add the following core JAR from the Lucene installation directory −
- lucene-core-10.2.2.jar
Step 3 - Create Source Files
Let us now create actual source files under the LuceneFirstApplication project. First we need to create a package called com.tutorialspoint.lucene. To do this, right-click on src in package explorer section and follow the option : New -> Package.
Next we will create LuceneTester.java and other java classes under the com.tutorialspoint.lucene package.
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
TextFileFilter.java
This class is used as a .txt file filter.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}
Indexer.java
This class is used to index the raw data so that we can make it searchable using the Lucene library.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
import java.io.FileReader;
import java.io.IOException;
import java.nio.file.Paths;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
public class Indexer {
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory = FSDirectory.open(Paths.get(indexDirectoryPath));
StandardAnalyzer analyzer = new StandardAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(analyzer);
writer = new IndexWriter(indexDirectory, config);
}
public void close() throws CorruptIndexException, IOException {
writer.close();
}
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new TextField(LuceneConstants.CONTENTS, new FileReader(file));
//index file name
Field fileNameField = new StringField(LuceneConstants.FILE_NAME,
file.getName(),Field.Store.YES);
//index file path
Field filePathField = new StringField(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),Field.Store.YES);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}
private void indexFile(File file) throws IOException {
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}
public int createIndex(String dataDirPath, FileFilter filter)
throws IOException {
//get all files in the data directory
File[] files = new File(dataDirPath).listFiles();
for (File file : files) {
if(!file.isDirectory()
&& !file.isHidden()
&& file.exists()
&& file.canRead()
&& filter.accept(file)
){
indexFile(file);
}
}
return writer.getDocStats().numDocs;
}
}
Searcher.java
This class is used to search the indexes created by the Indexer to search the requested content.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.nio.file.Paths;
import java.text.ParseException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.QueryBuilder;
public class Searcher {
IndexSearcher indexSearcher;
QueryBuilder queryBuilder;
Query query;
public Searcher(String indexDirectoryPath)
throws IOException {
DirectoryReader indexDirectory = DirectoryReader.open(FSDirectory.open(Paths.get(indexDirectoryPath)));
indexSearcher = new IndexSearcher(indexDirectory);
StandardAnalyzer analyzer = new StandardAnalyzer();
queryBuilder = new QueryBuilder(analyzer);
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryBuilder.createPhraseQuery(LuceneConstants.CONTENTS, searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.storedFields().document(scoreDoc.doc);
}
}
LuceneTester.java
This class is used to test the indexing and search capability of lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.text.ParseException;
import org.apache.lucene.document.Document;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "D:\\lucene\\Index";
String dataDir = "D:\\lucene\\Data";
Indexer indexer;
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.createIndex();
tester.search("Mohan");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void createIndex() throws IOException {
indexer = new Indexer(indexDir);
int numIndexed;
long startTime = System.currentTimeMillis();
numIndexed = indexer.createIndex(dataDir, new TextFileFilter());
long endTime = System.currentTimeMillis();
indexer.close();
System.out.println(numIndexed+" File indexed, time taken: "
+(endTime-startTime)+" ms");
}
private void search(String searchQuery) throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
TopDocs hits = searcher.search(searchQuery);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime));
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "
+ doc.get(LuceneConstants.FILE_PATH));
}
}
}
Step 4 - Data & Index directory creation
We have used 10 text files from record1.txt to record10.txt containing names and other details of the students and put them in the directory D:\Lucene\Data. Test Data. An index directory path should be created as D:\Lucene\Index. After running this program, you can see the list of index files created in that folder.
Step 5 - Running the program
Once you are done with the creation of the source, the raw data, the data directory and the index directory, you are ready for compiling and running of your program. To do this, keep the LuceneTester.Java file tab active and use either the Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If the application runs successfully, it will print the following message in Eclipse IDE's console −
Output
Sept 08, 2025 5:39:24 PM org.apache.lucene.internal.vectorization.VectorizationProvider lookup WARNING: Java vector incubator module is not readable. For optimal vector performance, pass '--add-modules jdk.incubator.vector' to enable Vector API. Indexing D:\lucene\Data\record1.txt Indexing D:\lucene\Data\record10.txt Indexing D:\lucene\Data\record2.txt Indexing D:\lucene\Data\record3.txt Indexing D:\lucene\Data\record4.txt Indexing D:\lucene\Data\record5.txt Indexing D:\lucene\Data\record6.txt Indexing D:\lucene\Data\record7.txt Indexing D:\lucene\Data\record8.txt Indexing D:\lucene\Data\record9.txt 10 File indexed, time taken: 88 ms 1 hits documents found. Time :22 File: D:\lucene\Data\record4.txt
Once you've run the program successfully, you will have the following content in your index directory −
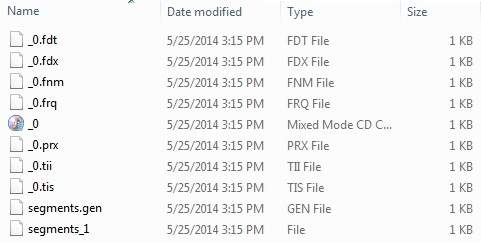
Lucene - Indexing Classes
Indexing process is one of the core functionalities provided by Lucene. The following diagram illustrates the indexing process and the use of classes. IndexWriter is the most important and the core component of the indexing process.
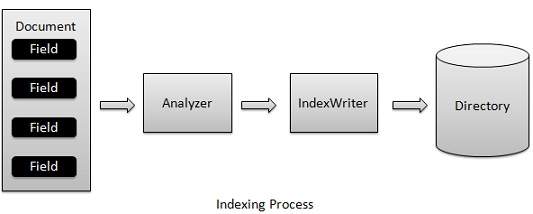
We add Document(s) containing Field(s) to IndexWriter which analyzes the Document(s) using the Analyzer and then creates/open/edit indexes as required and store/update them in a Directory. IndexWriter is used to update or create indexes. It is not used to read indexes.
Indexing Classes
Following is a list of commonly-used classes during the indexing process.
| S.No. | Class & Description |
|---|---|
| 1 |
IndexWriter
This class acts as a core component which creates/updates indexes during the indexing process. |
| 2 |
Directory
This class represents the storage location of the indexes. |
| 3 |
Analyzer
This class is responsible to analyze a document and get the tokens/words from the text which is to be indexed. Without analysis done, IndexWriter cannot create index. |
| 4 |
Document
This class represents a virtual document with Fields where the Field is an object which can contain the physical document's contents, its meta data and so on. The Analyzer can understand a Document only. |
| 5 |
Field
This is the lowest unit or the starting point of the indexing process. It represents the key value pair relationship where a key is used to identify the value to be indexed. Let us assume a field used to represent contents of a document will have key as "contents" and the value may contain the part or all of the text or numeric content of the document. Lucene can index only text or numeric content only. |
| 6 |
TokenStream
TokenStream is an output of the analysis process and it comprises of a series of tokens. It is an abstract class. |
Lucene - Searching Classes
The process of Searching is again one of the core functionalities provided by Lucene. Its flow is similar to that of the indexing process. Basic search of Lucene can be made using the following classes which can also be termed as foundation classes for all search related operations.
Searching Classes
Following is a list of commonly-used classes during searching process.
| S.No. | Class & Description |
|---|---|
| 1 |
IndexSearcher
This class act as a core component which reads/searches indexes created after the indexing process. It takes directory instance pointing to the location containing the indexes. |
| 2 |
Term
This class is the lowest unit of searching. It is similar to Field in indexing process. |
| 3 |
Query
Query is an abstract class and contains various utility methods and is the parent of all types of queries that Lucene uses during search process. |
| 4 |
TermQuery
TermQuery is the most commonly-used query object and is the foundation of many complex queries that Lucene can make use of. |
| 5 |
TopDocs
TopDocs points to the top N search results which matches the search criteria. It is a simple container of pointers to point to documents which are the output of a search result. |
Lucene - Indexing Process
Indexing process is one of the core functionality provided by Lucene. Following diagram illustrates the indexing process and use of classes. IndexWriter is the most important and core component of the indexing process.
We add Document(s) containing Field(s) to IndexWriter which analyzes the Document(s) using the Analyzer and then creates/open/edit indexes as required and store/update them in a Directory. IndexWriter is used to update or create indexes. It is not used to read indexes.
Now we'll show you a step by step process to get a kick start in understanding of indexing process using a basic example.
Create a document
Create a method to get a lucene document from a text file.
Create various types of fields which are key value pairs containing keys as names and values as contents to be indexed.
Set field to be analyzed or not. In our case, only contents is to be analyzed as it can contain data such as a, am, are, an etc. which are not required in search operations.
Add the newly created fields to the document object and return it to the caller method.
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new TextField(LuceneConstants.CONTENTS, new FileReader(file));
//index file name
Field fileNameField = new StringField(LuceneConstants.FILE_NAME,
file.getName(),Field.Store.YES);
//index file path
Field filePathField = new StringField(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),Field.Store.YES);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}
Create a IndexWriter
IndexWriter class acts as a core component which creates/updates indexes during indexing process. Follow these steps to create a IndexWriter −
Step 1 − Create object of IndexWriter.
Step 2 − Create a Lucene directory which should point to location where indexes are to be stored.
Step 3 − Initialize the IndexWriter object created with the index directory, a standard analyzer and other required/optional parameters.
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory = FSDirectory.open(Paths.get(indexDirectoryPath));
StandardAnalyzer analyzer = new StandardAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(analyzer);
writer = new IndexWriter(indexDirectory, config);
}
Start Indexing Process
The following program shows how to start an indexing process −
private void indexFile(File file) throws IOException {
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}
Example Application
To test the indexing process, we need to create a Lucene application test.
| Step | Description |
|---|---|
| 1 | Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene - First Application chapter. You can also use the project created in Lucene - First Application chapter as such for this chapter to understand the indexing process. |
| 2 | Create LuceneConstants.java,TextFileFilter.java and Indexer.java as explained in the Lucene - First Application chapter. Keep the rest of the files unchanged. |
| 3 | Create LuceneTester.java as mentioned below. |
| 4 | Clean and build the application to make sure the business logic is working as per the requirements. |
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
TextFileFilter.java
This class is used as a .txt file filter.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}
Indexer.java
This class is used to index the raw data so that we can make it searchable using the Lucene library.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
import java.io.FileReader;
import java.io.IOException;
import java.nio.file.Paths;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
public class Indexer {
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory = FSDirectory.open(Paths.get(indexDirectoryPath));
StandardAnalyzer analyzer = new StandardAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(analyzer);
writer = new IndexWriter(indexDirectory, config);
}
public void close() throws CorruptIndexException, IOException {
writer.close();
}
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new TextField(LuceneConstants.CONTENTS, new FileReader(file));
//index file name
Field fileNameField = new StringField(LuceneConstants.FILE_NAME,
file.getName(),Field.Store.YES);
//index file path
Field filePathField = new StringField(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),Field.Store.YES);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}
private void indexFile(File file) throws IOException {
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}
public int createIndex(String dataDirPath, FileFilter filter)
throws IOException {
//get all files in the data directory
File[] files = new File(dataDirPath).listFiles();
for (File file : files) {
if(!file.isDirectory()
&& !file.isHidden()
&& file.exists()
&& file.canRead()
&& filter.accept(file)
){
indexFile(file);
}
}
return writer.getDocStats().numDocs;
}
}
LuceneTester.java
This class is used to test the indexing capability of the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
public class LuceneTester {
String indexDir = "D:\\Lucene\\Index";
String dataDir = "D:\\Lucene\\Data";
Indexer indexer;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.createIndex();
} catch (IOException e) {
e.printStackTrace();
}
}
private void createIndex() throws IOException {
indexer = new Indexer(indexDir);
int numIndexed;
long startTime = System.currentTimeMillis();
numIndexed = indexer.createIndex(dataDir, new TextFileFilter());
long endTime = System.currentTimeMillis();
indexer.close();
System.out.println(numIndexed+" File indexed, time taken: "
+(endTime-startTime)+" ms");
}
}
Data & Index Directory Creation
We have used 10 text files from record1.txt to record10.txt containing names and other details of the students and put them in the directory D:\Lucene\Data. Test Data. An index directory path should be created as D:\Lucene\Index. After running this program, you can see the list of index files created in that folder.
Running the Program
Once you are done with the creation of the source, the raw data, the data directory and the index directory, you can proceed by compiling and running your program. To do this, keep the LuceneTester.Java file tab active and use either the Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If your application runs successfully, it will print the following message in Eclipse IDE's console −
Output
Indexing D:\Lucene\Data\record1.txt Indexing D:\Lucene\Data\record10.txt Indexing D:\Lucene\Data\record2.txt Indexing D:\Lucene\Data\record3.txt Indexing D:\Lucene\Data\record4.txt Indexing D:\Lucene\Data\record5.txt Indexing D:\Lucene\Data\record6.txt Indexing D:\Lucene\Data\record7.txt Indexing D:\Lucene\Data\record8.txt Indexing D:\Lucene\Data\record9.txt 10 File indexed, time taken: 109 ms
Once you've run the program successfully, you will have the following content in your index directory −
Lucene - Search Operation
The process of searching is one of the core functionalities provided by Lucene. Following diagram illustrates the process and its use. IndexSearcher is one of the core components of the searching process.
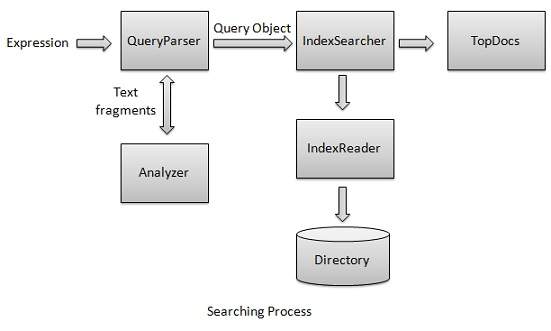
We first create Directory(s) containing indexes and then pass it to IndexSearcher which opens the Directory using IndexReader. Then we create a Query with a Term and make a search using IndexSearcher by passing the Query to the searcher. IndexSearcher returns a TopDocs object which contains the search details along with document ID(s) of the Document which is the result of the search operation.
We will now show you a step-wise approach and help you understand the indexing process using a basic example.
Create a QueryBuilder
QueryBuilder class is used to build a query using the user entered input into Lucene understandable format query. Follow these steps to create a QueryBuilder −
Step 1 − Create object of QueryBuilder.
Step 2 − Initialize the QueryBuilder object created with a standard analyzer.
QueryBuilder queryBuilder;
public Searcher(String indexDirectoryPath) throws IOException {
StandardAnalyzer analyzer = new StandardAnalyzer();
queryBuilder = new QueryBuilder(analyzer);
}
Create a IndexSearcher
IndexSearcher class acts as a core component which searcher indexes created during indexing process. Follow these steps to create a IndexSearcher −
Step 1 − Create object of IndexSearcher.
Step 2 − Create a Lucene directory which should point to location where indexes are to be stored.
Step 3 − Initialize the IndexSearcher object created with the index directory.
IndexSearcher indexSearcher;
public Searcher(String indexDirectoryPath) throws IOException {
DirectoryReader indexDirectory = DirectoryReader.open(FSDirectory.open(Paths.get(indexDirectoryPath)));
indexSearcher = new IndexSearcher(indexDirectory);
}
Make search
Follow these steps to make search −
Step 1 − Create a Query object by parsing the search expression through QueryBuilder.
Step 2 − Make search by calling the IndexSearcher.search() method.
Query query;
public TopDocs search( String searchQuery) throws IOException, ParseException {
query = queryBuilder.createPhraseQuery(LuceneConstants.CONTENTS, searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
Get the Document
The following program shows how to get the document.
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.storedFields().document(scoreDoc.doc);
}
Example Application
Let us create a test Lucene application to test searching process.
| Step | Description |
|---|---|
| 1 | Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene - First Application chapter. You can also use the project created in Lucene - First Application chapter as such for this chapter to understand the searching process. |
| 2 | Create LuceneConstants.java,TextFileFilter.java and Searcher.java as explained in the Lucene - First Application chapter. Keep the rest of the files unchanged. |
| 3 | Create LuceneTester.java as mentioned below. |
| 4 | Clean and Build the application to make sure business logic is working as per the requirements. |
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
TextFileFilter.java
This class is used as a .txt file filter.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}
Searcher.java
This class is used to read the indexes made on raw data and searches data using the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.nio.file.Paths;
import java.text.ParseException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.QueryBuilder;
public class Searcher {
IndexSearcher indexSearcher;
QueryBuilder queryBuilder;
Query query;
public Searcher(String indexDirectoryPath)
throws IOException {
DirectoryReader indexDirectory = DirectoryReader.open(FSDirectory.open(Paths.get(indexDirectoryPath)));
indexSearcher = new IndexSearcher(indexDirectory);
StandardAnalyzer analyzer = new StandardAnalyzer();
queryBuilder = new QueryBuilder(analyzer);
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryBuilder.createPhraseQuery(LuceneConstants.CONTENTS, searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.storedFields().document(scoreDoc.doc);
}
}
LuceneTester.java
This class is used to test the searching capability of the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "D:\\Lucene\\Index";
String dataDir = "D:\\Lucene\\Data";
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.search("Mohan");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void search(String searchQuery) throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
TopDocs hits = searcher.search(searchQuery);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) +" ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
}
}
Data & Index Directory Creation
We have used 10 text files named record1.txt to record10.txt containing names and other details of the students and put them in the directory D:\Lucene\Data. Test Data. An index directory path should be created as D:\Lucene\Index. After running the indexing program in the chapter Lucene - Indexing Process, you can see the list of index files created in that folder.
Running the Program
Once you are done with the creation of the source, the raw data, the data directory, the index directory and the indexes, you can proceed by compiling and running your program. To do this, keep LuceneTester.Java file tab active and use either the Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTesterapplication. If your application runs successfully, it will print the following message in Eclipse IDE's console −
Output
1 hits documents found. Time :30 ms File: D:\lucene\Data\record4.txt
Lucene - Sorting
Lucene gives the search results by default sorted by relevance and which can be manipulated as required.
Sorting by Relevance is the default sorting mode used by Lucene. Lucene provides results by the most relevant hit at the top.
Steps to sort Search results
Step 1: Create Index for the item to be sorted.
Add SortedDocValuesField for the field to be sorted.
//index file name Field fileNameField = new Field(LuceneConstants.FILE_NAME, file.getName(),type); //sort file name Field sortedFileNameField = new SortedDocValuesField(LuceneConstants.FILE_NAME, new BytesRef(file.getName())); // add fields document.add(fileNameField); document.add(sortedFileNameField);
Step 2: Create SortField and Sort Objects
Create Sort Object for the field to be searched.
// Sort by a string field SortField fileNameSort = new SortField(LuceneConstants.FILE_NAME, SortField.Type.STRING); Sort sort = new Sort(fileNameSort);
Step 3: Search using Sort Object
// sort and return search results return indexSearcher.search(query, LuceneConstants.MAX_SEARCH, sort);
Example Application
To test sorting by relevance, let us create a test Lucene application.
| Step | Description |
|---|---|
| 1 | Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene - First Application chapter. You can also use the project created in Lucene - First Application chapter as such for this chapter to understand the searching process. |
| 2 | Create LuceneConstants.java,TextFileFilter.java, Indexer.java and Searcher.java as explained in the Lucene - First Application chapter. Keep the rest of the files unchanged. |
| 3 | Create LuceneTester.java as mentioned below. |
| 4 | Clean and Build the application to make sure business logic is working as per the requirements. |
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
TextFileFilter.java
This class is used as a .txt file filter.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}
Indexer.java
This class is used to create index using lucene library.
package com.tutorialspoint.lucene;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileFilter;
import java.io.FileReader;
import java.io.IOException;
import java.nio.file.Paths;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.FieldType;
import org.apache.lucene.document.SortedDocValuesField;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.DocValuesType;
import org.apache.lucene.index.IndexOptions;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.BytesRef;
public class Indexer {
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory = FSDirectory.open(Paths.get(indexDirectoryPath));
StandardAnalyzer analyzer = new StandardAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(analyzer);
writer = new IndexWriter(indexDirectory, config);
}
public void close() throws CorruptIndexException, IOException {
writer.close();
}
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new TextField(LuceneConstants.CONTENTS,
new FileReader(file));
FieldType type = new FieldType();
type.setStored(true);
type.setTokenized(false);
type.setIndexOptions(IndexOptions.DOCS);
type.setOmitNorms(true);
//index file name
Field fileNameField = new Field(LuceneConstants.FILE_NAME,
file.getName(),type);
//sort file name
Field sortedFileNameField = new SortedDocValuesField(LuceneConstants.FILE_NAME, new BytesRef(file.getName()));
//index file path
Field filePathField = new Field(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),type);
document.add(contentField);
document.add(fileNameField);
document.add(sortedFileNameField);
document.add(filePathField);
return document;
}
private void indexFile(File file) throws IOException {
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}
public int createIndex(String dataDirPath, FileFilter filter)
throws IOException {
//get all files in the data directory
File[] files = new File(dataDirPath).listFiles();
for (File file : files) {
if(!file.isDirectory()
&& !file.isHidden()
&& file.exists()
&& file.canRead()
&& filter.accept(file)
){
indexFile(file);
}
}
return writer.getDocStats().numDocs;
}
}
Searcher.java
This class is used to read the indexes made on raw data and searches data using the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.nio.file.Paths;
import java.text.ParseException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.Sort;
import org.apache.lucene.search.SortField;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.QueryBuilder;
public class Searcher {
IndexSearcher indexSearcher;
QueryBuilder queryBuilder;
Query query;
public Searcher(String indexDirectoryPath)
throws IOException {
DirectoryReader indexDirectory = DirectoryReader.open(FSDirectory.open(Paths.get(indexDirectoryPath)));
indexSearcher = new IndexSearcher(indexDirectory);
StandardAnalyzer analyzer = new StandardAnalyzer();
queryBuilder = new QueryBuilder(analyzer);
}
public TopDocs search(Query query) throws IOException, ParseException {
// Sort by a string field
SortField fileNameSort = new SortField(LuceneConstants.FILE_NAME, SortField.Type.STRING);
Sort sort = new Sort(fileNameSort);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH, sort);
}
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.storedFields().document(scoreDoc.doc);
}
}
LuceneTester.java
This class is used to test the searching capability of the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.text.ParseException;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.search.WildcardQuery;
public class LuceneTester {
String indexDir = "D:\\lucene\\Index";
String dataDir = "D:\\lucene\\Data";
Indxer indexer;
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.createIndex();
tester.searchUsingWildCardQuery("record1*");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void createIndex() throws IOException {
indexer = new Indexer(indexDir);
int numIndexed;
long startTime = System.currentTimeMillis();
numIndexed = indexer.createIndex(dataDir, new TextFileFilter());
long endTime = System.currentTimeMillis();
indexer.close();
System.out.println(numIndexed+" File indexed, time taken: "
+(endTime-startTime)+" ms");
}
private void searchUsingWildCardQuery(String searchQuery)
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term = new Term(LuceneConstants.FILE_NAME, searchQuery);
//create the term query object
Query query = new WildcardQuery(term);
//do the search
TopDocs hits = searcher.search(query);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
}
}
Data & Index Directory Creation
We have used 10 text files from record1.txt to record10.txt containing names and other details of the students and put them in the directory D:\Lucene\Data. Test Data. An index directory path should be created as D:\Lucene\Index. Before running this program, delete any list of index files present in that folder.
Running the Program
Once you are done with the creation of the source, the raw data, the data directory, the index directory and the indexes, you can compile and run your program. To do this, Keep the LuceneTester.Java file tab active and use either the Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If your application runs successfully, it will print the following message in Eclipse IDE's console −
Indexing D:\lucene\Data\record1.txt Indexing D:\lucene\Data\record10.txt Indexing D:\lucene\Data\record2.txt Indexing D:\lucene\Data\record3.txt Indexing D:\lucene\Data\record4.txt Indexing D:\lucene\Data\record5.txt Indexing D:\lucene\Data\record6.txt Indexing D:\lucene\Data\record7.txt Indexing D:\lucene\Data\record8.txt Indexing D:\lucene\Data\record9.txt 10 File indexed, time taken: 63 ms 2 hits documents found. Time :69ms File: D:\lucene\Data\record1.txt File: D:\lucene\Data\record10.txt
Lucene - Indexing Operations
In this chapter, we'll discuss the four major operations of indexing. These operations are useful at various times and are used throughout of a software search application.
Indexing Operations
Following is a list of commonly-used operations during indexing process.
| S.No. | Operation & Description |
|---|---|
| 1 |
Add Document
This operation is used in the initial stage of the indexing process to create the indexes on the newly available content. |
| 2 |
Update Document
This operation is used to update indexes to reflect the changes in the updated contents. It is similar to recreating the index. |
| 3 |
Delete Document
This operation is used to update indexes to exclude the documents which are not required to be indexed/searched. |
| 4 |
Field Options
Field options specify a way or control the ways in which the contents of a field are to be made searchable. |
Lucene - Add Document Operation
Add document is one of the core operations of the indexing process.
We add Document(s) containing Field(s) to IndexWriter where IndexWriter is used to update or create indexes.
We will now show you a step-wise approach and help you understand how to add a document using a basic example.
Add a document to an index
Follow these steps to add a document to an index −
Step 1 − Create a method to get a Lucene document from a text file.
Step 2 − Create various fields which are key value pairs containing keys as names and values as contents to be indexed.
Step 3 − Set field to be analyzed or not. In our case, only the content is to be analyzed as it can contain data such as a, am, are, an etc. which are not required in search operations.
Step 4 − Add the newly-created fields to the document object and return it to the caller method.
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new TextField(LuceneConstants.CONTENTS, new FileReader(file));
//index file name
Field fileNameField = new StringField(LuceneConstants.FILE_NAME,
file.getName(),Field.Store.YES);
//index file path
Field filePathField = new StringField(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),Field.Store.YES);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}
Create a IndexWriter
IndexWriter class acts as a core component which creates/updates indexes during the indexing process.
Follow these steps to create a IndexWriter −
Step 1 − Create object of IndexWriter.
Step 2 − Create a Lucene directory which should point to location where indexes are to be stored.
Initialize the IndexWriter object created with the index directory, a standard analyzer having version information and other required/optional parameters.
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory = FSDirectory.open(Paths.get(indexDirectoryPath));
StandardAnalyzer analyzer = new StandardAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(analyzer);
writer = new IndexWriter(indexDirectory, config);
}
Add Document and Start Indexing Process
Following two are the ways to add the document.
addDocument(Document) − Adds the document using the default analyzer (specified when the index writer is created.)
addDocument(Document,Analyzer) − Adds the document using the provided analyzer.
private void indexFile(File file) throws IOException {
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}
Example Application
To test the indexing process, we need to create Lucene application test.
| Step | Description |
|---|---|
| 1 | Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene - First Application chapter. To understand the indexing process, you can also use the project created in Lucene - First Application chapter as such for this chapter. |
| 2 | Create LuceneConstants.java,TextFileFilter.java and Indexer.java as explained in the Lucene - First Application chapter. Keep the rest of the files unchanged. |
| 3 | Create LuceneTester.java as mentioned below. |
| 4 | Clean and Build the application to make sure business logic is working as per the requirements. |
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
TextFileFilter.java
This class is used as a .txt file filter.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}
Indexer.java
This class is used to index the raw data so that we can make it searchable using the Lucene library.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
import java.io.FileReader;
import java.io.IOException;
import java.nio.file.Paths;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
public class Indexer {
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory = FSDirectory.open(Paths.get(indexDirectoryPath));
StandardAnalyzer analyzer = new StandardAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(analyzer);
writer = new IndexWriter(indexDirectory, config);
}
public void close() throws CorruptIndexException, IOException {
writer.close();
}
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new TextField(LuceneConstants.CONTENTS, new FileReader(file));
//index file name
Field fileNameField = new StringField(LuceneConstants.FILE_NAME,
file.getName(),Field.Store.YES);
//index file path
Field filePathField = new StringField(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),Field.Store.YES);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}
private void indexFile(File file) throws IOException {
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}
public int createIndex(String dataDirPath, FileFilter filter)
throws IOException {
//get all files in the data directory
File[] files = new File(dataDirPath).listFiles();
for (File file : files) {
if(!file.isDirectory()
&& !file.isHidden()
&& file.exists()
&& file.canRead()
&& filter.accept(file)
){
indexFile(file);
}
}
return writer.getDocStats().numDocs;
}
}
LuceneTester.java
This class is used to test the indexing capability of the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
public class LuceneTester {
String indexDir = "D:\\Lucene\\Index";
String dataDir = "D:\\Lucene\\Data";
Indexer indexer;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.createIndex();
} catch (IOException e) {
e.printStackTrace();
}
}
private void createIndex() throws IOException {
indexer = new Indexer(indexDir);
int numIndexed;
long startTime = System.currentTimeMillis();
numIndexed = indexer.createIndex(dataDir, new TextFileFilter());
long endTime = System.currentTimeMillis();
indexer.close();
System.out.println(numIndexed+" File indexed, time taken: "
+(endTime-startTime)+" ms");
}
}
Data & Index Directory Creation
We have used 10 text files from record1.txt to record10.txt containing names and other details of the students and put them in the directory D:\Lucene\Data. Test Data. An index directory path should be created as D:\Lucene\Index. After running this program, you can see the list of index files created in that folder.
Running the Program
Once you are done with the creation of the source, creating the raw data, data directory and index directory, you are ready for this step which is compiling and running your program. To do this, keep LuceneTester.Java file tab active and use either Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If your application runs successfully, it will print the following message in Eclipse IDE's console −
Indexing D:\lucene\Data\record1.txt Indexing D:\lucene\Data\record10.txt Indexing D:\lucene\Data\record2.txt Indexing D:\lucene\Data\record3.txt Indexing D:\lucene\Data\record4.txt Indexing D:\lucene\Data\record5.txt Indexing D:\lucene\Data\record6.txt Indexing D:\lucene\Data\record7.txt Indexing D:\lucene\Data\record8.txt Indexing D:\lucene\Data\record9.txt 10 File indexed, time taken: 88 ms
Once you've run the program successfully, you will have following content in your index directory −
Lucene - Update Document Operation
Update document is another important operation as part of indexing process. This operation is used when already indexed contents are updated and indexes become invalid. This operation is also known as re-indexing.
We update Document(s) containing Field(s) to IndexWriter where IndexWriter is used to update indexes.
We will now show you a step-wise approach and help you understand how to update document using a basic example.
Update a Document to an Index
Follow this step to update a document to an index −
Step 1 − Create a method to update a Lucene document from an updated text file.
private void updateDocument(File file) throws IOException {
Document document = new Document();
String contents = "Updated Contents : ";
try(BufferedReader reader = new BufferedReader(new FileReader(file))) {
String line;
while((line = reader.readLine()) != null) {
contents += line;
}
}
//update indexes for file contents
writer.updateDocument(new Term
(LuceneConstants.CONTENTS,
contents),document);
}
Create an IndexWriter
Follow these steps to create an IndexWriter −
Step 1 − IndexWriter class acts as a core component which creates/updates indexes during the indexing process.
Step 2 − Create object of IndexWriter.
Step 3 − Create a Lucene directory which should point to location where indexes are to be stored.
Step 4 − Initialize the IndexWriter object created with the index directory, a standard analyzer having version information and other required/optional parameters.
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory = FSDirectory.open(Paths.get(indexDirectoryPath));
StandardAnalyzer analyzer = new StandardAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(analyzer);
writer = new IndexWriter(indexDirectory, config);
}
Update document and start reindexing process
Following are the two ways to update the document.
updateDocument(Term, Document) − Delete the document containing the term and add the document using the default analyzer (specified when index writer is created).
updateDocument(Term, Document,Analyzer) − Delete the document containing the term and add the document using the provided analyzer.
private void indexFile(File file) throws IOException {
System.out.println("Updating index for "+file.getCanonicalPath());
updateDocument(file);
}
Example Application
To test the indexing process, let us create a Lucene application test.
| Step | Description |
|---|---|
| 1 | Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene - First Application chapter. You can also use the project created in Lucene - First Application chapter as such for this chapter to understand the indexing process. |
| 2 | Create LuceneConstants.java,TextFileFilter.java and Indexer.java as explained in the Lucene - First Application chapter. Keep the rest of the files unchanged. |
| 3 | Create LuceneTester.java as mentioned below. |
| 4 | Clean and Build the application to make sure business logic is working as per the requirements. |
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
TextFileFilter.java
This class is used as a .txt file filter.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}
Indexer.java
This class is used to index the raw data so that we can make it searchable using the Lucene library.
package com.tutorialspoint.lucene;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileFilter;
import java.io.FileReader;
import java.io.IOException;
import java.nio.file.Paths;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
public class Indexer {
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory = FSDirectory.open(Paths.get(indexDirectoryPath));
StandardAnalyzer analyzer = new StandardAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(analyzer);
writer = new IndexWriter(indexDirectory, config);
}
public void close() throws CorruptIndexException, IOException {
writer.close();
}
private void indexFile(File file) throws IOException {
System.out.println("Updating index for "+file.getCanonicalPath());
updateDocument(file);
}
private void updateDocument(File file) throws IOException {
Document document = new Document();
String contents = "Updated Contents : ";
try(BufferedReader reader = new BufferedReader(new FileReader(file))) {
String line;
while((line = reader.readLine()) != null) {
contents += line;
}
}
//update indexes for file contents
writer.updateDocument(new Term
(LuceneConstants.CONTENTS,
contents),document);
}
public int createIndex(String dataDirPath, FileFilter filter)
throws IOException {
//get all files in the data directory
File[] files = new File(dataDirPath).listFiles();
for (File file : files) {
if(!file.isDirectory()
&& !file.isHidden()
&& file.exists()
&& file.canRead()
&& filter.accept(file)
){
indexFile(file);
}
}
return writer.getDocStats().numDocs;
}
}
LuceneTester.java
This class is used to test the indexing capability of the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
public class LuceneTester {
String indexDir = "D:\\Lucene\\Index";
String dataDir = "D:\\Lucene\\Data";
Indexer indexer;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.createIndex();
} catch (IOException e) {
e.printStackTrace();
}
}
private void createIndex() throws IOException {
indexer = new Indexer(indexDir);
int numIndexed;
long startTime = System.currentTimeMillis();
numIndexed = indexer.createIndex(dataDir, new TextFileFilter());
long endTime = System.currentTimeMillis();
indexer.close();
}
}
Data & Index Directory Creation
Here, we have used 10 text files from record1.txt to record10.txt containing names and other details of the students and put them in the directory D:\Lucene\Data. Test Data. An index directory path should be created as D:\Lucene\Index. After running this program, you can see the list of index files created in that folder.
Running the Program
Once you are done with the creation of the source, the raw data, the data directory and the index directory, you can proceed with the compiling and running of your program. To do this, keep the LuceneTester.Java file tab active and use either the Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If your application runs successfully, it will print the following message in Eclipse IDE's console −
Output
Updating index for D:\lucene\Data\record1.txt Updating index for D:\lucene\Data\record10.txt Updating index for D:\lucene\Data\record2.txt Updating index for D:\lucene\Data\record3.txt Updating index for D:\lucene\Data\record4.txt Updating index for D:\lucene\Data\record5.txt Updating index for D:\lucene\Data\record6.txt Updating index for D:\lucene\Data\record7.txt Updating index for D:\lucene\Data\record8.txt Updating index for D:\lucene\Data\record9.txt 10 File indexed, time taken: 50 ms
Once you've run the above program successfully, you will have the following content in your index directory −
Lucene - Delete Document Operation
Delete document is another important operation of the indexing process. This operation is used when already indexed contents are updated and indexes become invalid or indexes become very large in size, then in order to reduce the size and update the index, delete operations are carried out.
We delete Document(s) containing Field(s) to IndexWriter where IndexWriter is used to update indexes.
We will now show you a step-wise approach and make you understand how to delete a document using a basic example.
Delete a document from an index
Follow these steps to delete a document from an index −
Step 1 − Create a method to delete a Lucene document of an obsolete text file.
private void deleteDocument(File file) throws IOException {
//delete indexes for a file
writer.deleteDocument(new Term(LuceneConstants.FILE_NAME,file.getName()));
writer.commit();
}
Create an IndexWriter
IndexWriter class acts as a core component which creates/updates indexes during the indexing process.
Follow these steps to create an IndexWriter −
Step 1 − Create object of IndexWriter.
Step 2 − Create a Lucene directory which should point to a location where indexes are to be stored.
Step 3 − Initialize the IndexWriter object created with the index directory, a standard analyzer having the version information and other required/optional parameters.
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory = FSDirectory.open(Paths.get(indexDirectoryPath));
StandardAnalyzer analyzer = new StandardAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(analyzer);
writer = new IndexWriter(indexDirectory, config);
}
Delete Document and Start Reindexing Process
Following are the ways to delete the document.
deleteDocuments(Term) − Delete all the documents containing the term.
deleteDocuments(Term[]) − Delete all the documents containing any of the terms in the array.
deleteDocuments(Query) − Delete all the documents matching the query.
deleteDocuments(Query[]) − Delete all the documents matching the query in the array.
deleteAll() − Delete all the documents.
private void indexFile(File file) throws IOException {
System.out.println("Deleting index for "+file.getCanonicalPath());
deleteDocument(file);
}
Example Application
To test the indexing process, let us create a Lucene application test.
| Step | Description |
|---|---|
| 1 | Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene - First Application chapter. You can also use the project created in Lucene - First Application chapter as such for this chapter to understand the indexing process. |
| 2 | Create LuceneConstants.java,TextFileFilter.java and Indexer.java as explained in the Lucene - First Application chapter. Keep the rest of the files unchanged. |
| 3 | Create LuceneTester.java as mentioned below. |
| 4 | Clean and Build the application to make sure business logic is working as per the requirements. |
LuceneConstants.java
This class provides various constants that can be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
TextFileFilter.java
This class is used as a .txt file filter.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}
Indexer.java
This class is used to index the raw data thereby, making it searchable using the Lucene library.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
import java.io.IOException;
import java.nio.file.Paths;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
public class Indexer {
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory = FSDirectory.open(Paths.get(indexDirectoryPath));
StandardAnalyzer analyzer = new StandardAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(analyzer);
writer = new IndexWriter(indexDirectory, config);
}
public void close() throws CorruptIndexException, IOException {
writer.close();
}
private void deleteDocument(File file) throws IOException {
//delete indexes for a file
writer.deleteDocuments(
new Term(LuceneConstants.FILE_NAME,file.getName()));
writer.commit();
}
private void indexFile(File file) throws IOException {
System.out.println("Deleting index: "+file.getCanonicalPath());
deleteDocument(file);
}
public int createIndex(String dataDirPath, FileFilter filter)
throws IOException {
//get all files in the data directory
File[] files = new File(dataDirPath).listFiles();
for (File file : files) {
if(!file.isDirectory()
&& !file.isHidden()
&& file.exists()
&& file.canRead()
&& filter.accept(file)
){
indexFile(file);
}
}
return writer.getDocStats().numDocs;
}
}
LuceneTester.java
This class is used to test the indexing capability of the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
public class LuceneTester {
String indexDir = "D:\\Lucene\\Index";
String dataDir = "D:\\Lucene\\Data";
Indexer indexer;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.createIndex();
} catch (IOException e) {
e.printStackTrace();
}
}
private void createIndex() throws IOException {
indexer = new Indexer(indexDir);
int numIndexed;
long startTime = System.currentTimeMillis();
numIndexed = indexer.createIndex(dataDir, new TextFileFilter());
long endTime = System.currentTimeMillis();
indexer.close();
}
}
Data & Index Directory Creation
Weve used 10 text files from record1.txt to record10.txt containing names and other details of the students and put them in the directory D:\Lucene\Data. Test Data. An index directory path should be created as D:\Lucene\Index. After running this program, you can see the list of index files created in that folder.
Running the Program
Once you are done with the creation of the source, the raw data, the data directory and the index directory, you can compile and run your program. To do this, keep the LuceneTester.Java file tab active and use either the Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If your application runs successfully, it will print the following message in Eclipse IDE's console −
Output
Deleting index: D:\lucene\Data\record1.txt Deleting index: D:\lucene\Data\record10.txt Deleting index: D:\lucene\Data\record2.txt Deleting index: D:\lucene\Data\record3.txt Deleting index: D:\lucene\Data\record4.txt Deleting index: D:\lucene\Data\record5.txt Deleting index: D:\lucene\Data\record6.txt Deleting index: D:\lucene\Data\record7.txt Deleting index: D:\lucene\Data\record8.txt Deleting index: D:\lucene\Data\record9.txt 10 File indexed, time taken: 325 ms
Once you've run the program successfully, you will have following content in your index directory −
Lucene - Field Options/ Field Type
Field is the most important unit of the indexing process. It is the actual object containing the contents to be indexed. When we add a field, Lucene provides numerous controls on the field using the Field Options which state how much a field is to be searchable.
We add Document(s) containing Field(s) to IndexWriter where IndexWriter is used to update or create indexes.
We will now show you a step-wise approach and help you understand the various Field Options using a basic example.
Various Field Options using FieldType Object
Following are the various field options −
FieldType.setTokenized(true) − In this, we first analyze, then do indexing. This is used for normal text indexing. Analyzer will break the field's value into stream of tokens and each token is searchable separately.
FieldType.setTokenized(false) − In this, we do not analyze but do indexing. This is used for complete text indexing. For example, person's names, URL etc.
FieldType.omitNorms(true) − This is a variant of FieldType.setTokenized(true). The Analyzer will break the field's value into stream of tokens and each token is searchable separately. However, the NORMs are not stored in the indexes. NORMS are used to boost searching and this often ends up consuming a lot of memory.
FieldType.omitNorms(false) − This is variant of FieldType.setTokenized(false). Indexing is done but NORMS are not stored in the indexes.
FieldType.setIndexOptions(IndexOptions.NONE) − Field value is not searchable.
Use of Field Options
Following are the different ways in which the Field Options can be used −
To create a method to get a Lucene document from a text file.
To create various types of fields which are key value pairs containing keys as names and values as contents to be indexed.
To set field to be analyzed or not. In our case, only content is to be analyzed as it can contain data such as a, am, are, an, etc. which are not required in search operations.
To add the newly-created fields to the document object and return it to the caller method.
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new TextField(LuceneConstants.CONTENTS,
new FileReader(file));
FieldType type = new FieldType();
type.setStored(true);
type.setTokenized(false);
type.setIndexOptions(IndexOptions.DOCS);
type.setOmitNorms(true);
//index file name
Field fileNameField = new Field(LuceneConstants.FILE_NAME,
file.getName(),type);
//index file path
Field filePathField = new Field(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),type);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}
Example Application
To test the indexing process, we need to create a Lucene application test.
| Step | Description |
|---|---|
| 1 | Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene - First Application chapter. You can also use the project created in Lucene - First Application chapter as such for this chapter to understand the indexing process. |
| 2 | Create LuceneConstants.java,TextFileFilter.java and Indexer.java as explained in the Lucene - First Application chapter. Keep the rest of the files unchanged. |
| 3 | Create LuceneTester.java as mentioned below. |
| 4 | Clean and Build the application to make sure the business logic is working as per the requirements. |
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
TextFileFilter.java
This class is used as a .txt file filter.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}
Indexer.java
This class is used to index the raw data so that we can make it searchable using the Lucene library.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
import java.io.FileReader;
import java.io.IOException;
import java.nio.file.Paths;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.FieldType;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexOptions;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
public class Indexer {
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory = FSDirectory.open(Paths.get(indexDirectoryPath));
StandardAnalyzer analyzer = new StandardAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(analyzer);
writer = new IndexWriter(indexDirectory, config);
}
public void close() throws CorruptIndexException, IOException {
writer.close();
}
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new TextField(LuceneConstants.CONTENTS,
new FileReader(file));
FieldType type = new FieldType();
type.setStored(true);
type.setTokenized(false);
type.setIndexOptions(IndexOptions.DOCS);
type.setOmitNorms(true);
//index file name
Field fileNameField = new Field(LuceneConstants.FILE_NAME,
file.getName(),type);
//index file path
Field filePathField = new Field(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),type);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}
private void indexFile(File file) throws IOException {
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}
public int createIndex(String dataDirPath, FileFilter filter)
throws IOException {
//get all files in the data directory
File[] files = new File(dataDirPath).listFiles();
for (File file : files) {
if(!file.isDirectory()
&& !file.isHidden()
&& file.exists()
&& file.canRead()
&& filter.accept(file)
){
indexFile(file);
}
}
return writer.getDocStats().numDocs;
}
}
LuceneTester.java
This class is used to test the indexing capability of the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
public class LuceneTester {
String indexDir = "D:\\Lucene\\Index";
String dataDir = "D:\\Lucene\\Data";
Indexer indexer;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.createIndex();
} catch (IOException e) {
e.printStackTrace();
}
}
private void createIndex() throws IOException {
indexer = new Indexer(indexDir);
int numIndexed;
long startTime = System.currentTimeMillis();
numIndexed = indexer.createIndex(dataDir, new TextFileFilter());
long endTime = System.currentTimeMillis();
indexer.close();
System.out.println(numIndexed+" File indexed, time taken: "
+(endTime-startTime)+" ms");
}
}
Data & Index Directory Creation
We have used 10 text files from record1.txt to record10.txt containing names and other details of the students and put them in the directory D:\Lucene\Data. Test Data. An index directory path should be created as D:\Lucene\Index. After running this program, you can see the list of index files created in that folder.
Running the Program
Once you are done with the creation of the source, the raw data, the data directory and the index directory, you can compile and run your program. To do this, keep the LuceneTester.Java file tab active and use either the Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If your application runs successfully, it will print the following message in Eclipse IDE's console −
Indexing D:\lucene\Data\record1.txt Indexing D:\lucene\Data\record10.txt Indexing D:\lucene\Data\record2.txt Indexing D:\lucene\Data\record3.txt Indexing D:\lucene\Data\record4.txt Indexing D:\lucene\Data\record5.txt Indexing D:\lucene\Data\record6.txt Indexing D:\lucene\Data\record7.txt Indexing D:\lucene\Data\record8.txt Indexing D:\lucene\Data\record9.txt 10 File indexed, time taken: 60 ms
Once you've run the program successfully, you will have following content in your index directory −
Lucene - Query Programming
We have seen in previous chapter Lucene - Search Operation, Lucene uses IndexSearcher to make searches and it uses the Query object created by QueryParser as the input. In this chapter, we are going to discuss various types of Query objects and the different ways to create them programmatically. Creating different types of Query object gives control on the kind of search to be made.
Consider a case of Advanced Search, provided by many applications where users are given multiple options to confine the search results. By Query programming, we can achieve the same very easily.
Query Types
Following is the list of Query types that we'll discuss in due course.
| S.No. | Class & Description |
|---|---|
| 1 |
TermQuery
This class acts as a core component which creates/updates indexes during the indexing process. |
| 2 |
TermRangeQuery
TermRangeQuery is used when a range of textual terms are to be searched. |
| 3 |
PrefixQuery
PrefixQuery is used to match documents whose index starts with a specified string. |
| 4 |
BooleanQuery
BooleanQuery is used to search documents which are result of multiple queries using AND, OR or NOT operators. |
| 5 |
PhraseQuery
Phrase query is used to search documents which contain a particular sequence of terms. |
| 6 |
WildCardQuery
WildcardQuery is used to search documents using wildcards like '*' for any character sequence,? matching a single character. |
| 7 |
FuzzyQuery
FuzzyQuery is used to search documents using fuzzy implementation that is an approximate search based on the edit distance algorithm. |
| 8 |
MatchAllDocsQuery
MatchAllDocsQuery as the name suggests matches all the documents. |
| 9 |
MatchNoDocsQuery
MatchAllDocsQuery as the name suggests matches no document. |
| 10 |
RegexpQuery
RegexpQuery provides a fast regular expression based query. |
Lucene - TermQuery
TermQuery is the most commonly-used query object and is the foundation of many complex queries that Lucene can make use of. It is used to retrieve documents based on the key which is case sensitive.
Class Declaration
Following is the declaration for org.apache.lucene.search.TermQuery class −
public class TermQuery extends Query
| S.No. | Constructor & Description |
|---|---|
| 1 |
TermQuery(Term t) Constructs a query for the term t. |
| 2 |
TermQuery(Term t, TermStates states) Expert: constructs a TermQuery that will use the provided docFreq instead of looking up the docFreq against the searcher. |
| S.No. | Method & Description |
|---|---|
| 1 |
Weight createWeight(IndexSearcher searcher, ScoreMode scoreMode, float boost) Expert: Constructs an appropriate Weight implementation for this query. |
| 2 |
boolean equals(Object other) Returns true iff other is equal to this. |
| 3 |
Term getTerm() Returns the term of this query. |
| 4 |
TermStates getTermStates() Returns the TermStates passed to the constructor, or null if it was not passed. |
| 5 |
int hashCode() Override and implement query hash code properly in a subclass. |
| 6 |
String toString(String field) Prints a user-readable version of this query. |
| 7 |
void visit(QueryVisitor visitor) Recurse through the query tree, visiting any child queries. |
Methods Inherited
This class inherits methods from the following classes −
- org.apache.lucene.search.Query
- java.lang.Object
Usage of TermQuery
private void searchUsingTermQuery(
String searchQuery)throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term = new Term(LuceneConstants.FILE_NAME, searchQuery);
//create the term query object
Query query = new TermQuery(term);
//do the search
TopDocs hits = searcher.search(query);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
Example Application
To test search using TermQuery, let us create a test Lucene application.
| Step | Description |
|---|---|
| 1 | Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene - First Application chapter. You can also use the project created in Lucene - First Application chapter as such for this chapter to understand the searching process. |
| 2 | Create LuceneConstants.java and Searcher.java as explained in the Lucene - First Application chapter. Keep the rest of the files unchanged. |
| 3 | Create LuceneTester.java as mentioned below. |
| 4 | Clean and Build the application to make sure business logic is working as per the requirements. |
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
Searcher.java
This class is used to read the indexes made on raw data and searches data using the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.nio.file.Paths;
import java.text.ParseException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.QueryBuilder;
public class Searcher {
IndexSearcher indexSearcher;
QueryBuilder queryBuilder;
Query query;
public Searcher(String indexDirectoryPath)
throws IOException {
DirectoryReader indexDirectory = DirectoryReader.open(FSDirectory.open(Paths.get(indexDirectoryPath)));
indexSearcher = new IndexSearcher(indexDirectory);
StandardAnalyzer analyzer = new StandardAnalyzer();
queryBuilder = new QueryBuilder(analyzer);
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryBuilder.createPhraseQuery(LuceneConstants.CONTENTS, searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public TopDocs search(Query query) throws IOException, ParseException {
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc) throws CorruptIndexException, IOException {
return indexSearcher.storedFields().document(scoreDoc.doc);
}
}
LuceneTester.java
This class is used to test the searching capability of the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.text.ParseException;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "D:\\Lucene\\Index";
String dataDir = "D:\\Lucene\\Data";
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.searchUsingTermQuery("record4.txt");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void searchUsingTermQuery(
String searchQuery)throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term = new Term(LuceneConstants.FILE_NAME, searchQuery);
//create the term query object
Query query = new TermQuery(term);
//do the search
TopDocs hits = searcher.search(query);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
}
}
Data & Index Directory Creation
I've used 10 text files from record1.txt to record10.txt containing names and other details of the students and put them in the directory D:\Lucene\Data. Test Data. An index directory path should be created as D:\Lucene\Index. After running the indexing program in the chapter Lucene - Indexing Process, you can see the list of index files created in that folder.
Running the Program
Once you are done with the creation of the source, the raw data, the data directory, the index directory and the indexes, you can proceed by compiling and running your program. To do this, keep the LuceneTester.Java file tab active and use either the Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If your application runs successfully, it will print the following message in Eclipse IDE's console −
Output
1 documents found. Time :13 ms File: D:\Lucene\Data\record4.txt
Lucene - TermRangeQuery
TermRangeQuery is used when a range of textual terms are to be searched.
Class Declaration
Following is the declaration for org.apache.lucene.search.TermRangeQuery class −
public class TermRangeQuery extends AutomatonQuery
| S.No. | Constructor & Description |
|---|---|
| 1 |
TermRangeQuery(String field, BytesRef lowerTerm, BytesRef upperTerm, boolean includeLower, boolean includeUpper) Constructs a query selecting all terms greater/equal than lowerTerm but less/equal than upperTerm. |
| 2 |
TermRangeQuery(String field, BytesRef lowerTerm, BytesRef upperTerm, boolean includeLower, boolean includeUpper, MultiTermQuery.RewriteMethod rewriteMethod) Constructs a query selecting all terms greater/equal than lowerTerm but less/equal than upperTerm. |
| S.No. | Method & Description |
|---|---|
| 1 |
boolean equals(Object obj) Override and implement query instance equivalence properly in a subclass. |
| 2 |
BytesRef getLowerTerm() Returns the lower value of this range query. |
| 3 |
BytesRef getUpperTerm() Returns the upper value of this range query. |
| 4 |
int hashCode() Override and implement query hash code properly in a subclass. |
| 5 |
boolean includesLower() Returns true if the lower endpoint is inclusive. |
| 6 |
boolean includesUpper() Returns true if the upper endpoint is inclusive. |
| 7 |
static TermRangeQuery newStringRange(String field, String lowerTerm, String upperTerm, boolean includeLower, boolean includeUpper) Factory that creates a new TermRangeQuery using Strings for term text. |
| 8 |
static TermRangeQuery newStringRange(String field, String lowerTerm, String upperTerm, boolean includeLower, boolean includeUpper, MultiTermQuery.RewriteMethod rewriteMethod) Factory that creates a new TermRangeQuery using Strings for term text. |
| 9 |
static Automaton toAutomaton(BytesRef lowerTerm, BytesRef upperTerm, boolean includeLower, boolean includeUpper)
|
| 10 |
String toString(String field) Prints a user-readable version of this query. |
Methods Inherited
This class inherits methods from the following classes −
- org.apache.lucene.search.AutomatonQuery
- org.apache.lucene.search.MultiTermQuery
- org.apache.lucene.search.Query
- java.lang.Object
Usage of TermRangeQuery
private void searchUsingTermRangeQuery(String searchQueryMin,
String searchQueryMax)throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create the term query object
Query query = TermRangeQuery.newStringRange(LuceneConstants.FILE_NAME,
searchQueryMin,searchQueryMax,true,false);
//do the search
TopDocs hits = searcher.search(query);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
Example Application
To test search using TermRangeQuery, let us create a test Lucene application.
| Step | Description |
|---|---|
| 1 | Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene - First Application chapter. You can also use the project created in Lucene - First Application chapter as such for this chapter to understand the searching process. |
| 2 | Create LuceneConstants.java and Searcher.java as explained in the Lucene - First Application chapter. Keep the rest of the files unchanged. |
| 3 | Create LuceneTester.java as mentioned below. |
| 4 | Clean and Build the application to make sure business logic is working as per the requirements. |
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
Searcher.java
This class is used to read the indexes made on raw data and searches data using the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.nio.file.Paths;
import java.text.ParseException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.QueryBuilder;
public class Searcher {
IndexSearcher indexSearcher;
QueryBuilder queryBuilder;
Query query;
public Searcher(String indexDirectoryPath)
throws IOException {
DirectoryReader indexDirectory = DirectoryReader.open(FSDirectory.open(Paths.get(indexDirectoryPath)));
indexSearcher = new IndexSearcher(indexDirectory);
StandardAnalyzer analyzer = new StandardAnalyzer();
queryBuilder = new QueryBuilder(analyzer);
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryBuilder.createPhraseQuery(LuceneConstants.CONTENTS, searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public TopDocs search(Query query) throws IOException, ParseException {
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc) throws CorruptIndexException, IOException {
return indexSearcher.storedFields().document(scoreDoc.doc);
}
}
LuceneTester.java
This class is used to test the searching capability of the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.text.ParseException;
import org.apache.lucene.document.Document;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermRangeQuery;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "D:\\Lucene\\Index";
String dataDir = "D:\\Lucene\\Data";
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.searchUsingTermRangeQuery("record2.txt","record6.txt");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void searchUsingTermRangeQuery(String searchQueryMin,
String searchQueryMax)throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create the term query object
Query query = TermRangeQuery.newStringRange(LuceneConstants.FILE_NAME,
searchQueryMin,searchQueryMax,true,false);
//do the search
TopDocs hits = searcher.search(query);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
}
}
Data & Index Directory Creation
I've used 10 text files from record1.txt to record10.txt containing names and other details of the students and put them in the directory D:\Lucene\Data. Test Data. An index directory path should be created as D:\Lucene\Index. After running the indexing program in the chapter Lucene - Indexing Process, you can see the list of index files created in that folder.
Running the Program
Once you are done with the creation of the source, the raw data, the data directory, the index directory and the indexes, you can proceed by compiling and running your program. To do this, keep the LuceneTester.Java file tab active and use either the Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If your application runs successfully, it will print the following message in Eclipse IDE's console −
Output
4 hits documents found. Time :75ms File: D:\lucene\Data\record2.txt File: D:\lucene\Data\record3.txt File: D:\lucene\Data\record4.txt File: D:\lucene\Data\record5.txt
Lucene - PrefixQuery
PrefixQuery class is used to match documents whose index start with a specified string.
Class Declaration
Following is the declaration for org.apache.lucene.search.PrefixQuery class −
public class PrefixQuery extends AutomatonQuery
| S.No. | Constructor & Description |
|---|---|
| 1 |
PrefixQuery(Term prefix) Constructs a query for terms starting with prefix. |
| 2 |
PrefixQuery(Term prefix, MultiTermQuery.RewriteMethod rewriteMethod) Constructs a query for terms starting with prefix using a defined RewriteMethod |
| S.No. | Method & Description |
|---|---|
| 1 |
boolean equals(Object obj) Override and implement query instance equivalence properly in a subclass. |
| 2 |
Term getPrefix() Returns the prefix of this query. |
| 3 |
int hashCode() Override and implement query hash code properly in a subclass. |
| 4 |
static Automaton toAutomaton(BytesRef prefix) Build an automaton accepting all terms with the specified prefix. |
| 5 |
String toString(String field) Prints a user-readable version of this query. |
Methods Inherited
This class inherits methods from the following classes −
- org.apache.lucene.search.AutomatonQuery
- org.apache.lucene.search.MultiTermQuery
- org.apache.lucene.search.Query
- java.lang.Object
Usage of PrefixQuery
private void searchUsingPrefixQuery(String searchQuery)
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term = new Term(LuceneConstants.FILE_NAME, searchQuery);
//create the term query object
Query query = new PrefixQuery(term);
//do the search
TopDocs hits = searcher.search(query);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
}
Example Application
To test search using PrefixQuery, let us create a test Lucene application.
| Step | Description |
|---|---|
| 1 | Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene - First Application chapter. You can also use the project created in Lucene - First Application chapter as such for this chapter to understand the searching process. |
| 2 | Create LuceneConstants.java and Searcher.java as explained in the Lucene - First Application chapter. Keep the rest of the files unchanged. |
| 3 | Create LuceneTester.java as mentioned below. |
| 4 | Clean and Build the application to make sure business logic is working as per the requirements. |
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
Searcher.java
This class is used to read the indexes made on raw data and searches data using the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.nio.file.Paths;
import java.text.ParseException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.QueryBuilder;
public class Searcher {
IndexSearcher indexSearcher;
QueryBuilder queryBuilder;
Query query;
public Searcher(String indexDirectoryPath)
throws IOException {
DirectoryReader indexDirectory = DirectoryReader.open(FSDirectory.open(Paths.get(indexDirectoryPath)));
indexSearcher = new IndexSearcher(indexDirectory);
StandardAnalyzer analyzer = new StandardAnalyzer();
queryBuilder = new QueryBuilder(analyzer);
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryBuilder.createPhraseQuery(LuceneConstants.CONTENTS, searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public TopDocs search(Query query) throws IOException, ParseException {
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc) throws CorruptIndexException, IOException {
return indexSearcher.storedFields().document(scoreDoc.doc);
}
}
LuceneTester.java
This class is used to test the searching capability of the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.text.ParseException;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.PrefixQuery;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "D:\\Lucene\\Index";
String dataDir = "D:\\Lucene\\Data";
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.searchUsingPrefixQuery("record1");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void searchUsingPrefixQuery(String searchQuery)
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term = new Term(LuceneConstants.FILE_NAME, searchQuery);
//create the term query object
Query query = new PrefixQuery(term);
//do the search
TopDocs hits = searcher.search(query);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
}
}
Data & Index Directory Creation
I've used 10 text files from record1.txt to record10.txt containing names and other details of the students and put them in the directory D:\Lucene\Data. Test Data. An index directory path should be created as D:\Lucene\Index. After running the indexing program in the chapter Lucene - Indexing Process, you can see the list of index files created in that folder.
Running the Program
Once you are done with the creation of the source, the raw data, the data directory, the index directory and the indexes, you can proceed by compiling and running your program. To do this, keep the LuceneTester.Java file tab active and use either the Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If your application runs successfully, it will print the following message in Eclipse IDE's console −
Output
2 hits documents found. Time :87ms File: D:\lucene\Data\record1.txt File: D:\lucene\Data\record10.txt
Lucene - BooleanQuery
BooleanQuery class is used to search documents which are a result of multiple queries using AND, OR or NOT operators.
Class Declaration
Following is the declaration for org.apache.lucene.search.BooleanQuery class −
public class BooleanQuery
extends Query
implements Iterable<BooleanClause>
| S.No. | Method & Description |
|---|---|
| 1 |
List<BooleanClause> clauses() Return a list of the clauses of this BooleanQuery. |
| 2 |
Weight createWeight(IndexSearcher searcher, ScoreMode scoreMode, float boost) Expert: Constructs an appropriate Weight implementation for this query. |
| 3 |
boolean equals(Object o) Compares the specified object with this boolean query for equality. |
| 4 |
Collection<Query> getClauses(BooleanClause.Occur occur) Return the collection of queries for the given BooleanClause.Occur. |
| 5 |
int getMinimumNumberShouldMatch() Gets the minimum number of the optional BooleanClauses which must be satisfied. |
| 6 |
int hashCode() Override and implement query hash code properly in a subclass. |
| 7 |
final Iterator<BooleanClause> iterator() Returns an iterator on the clauses in this query. |
| 8 |
Query rewrite(IndexSearcher indexSearcher) Expert: called to re-write queries into primitive queries. |
| 9 |
String toString(String field) Prints a user-readable version of this query. |
| 10 |
void visit(QueryVisitor visitor) Recurse through the query tree, visiting any child queries. |
Methods Inherited
This class inherits methods from the following classes −
- org.apache.lucene.search.Query
- java.lang.Object
Usage of BooleanQuery
private void searchUsingBooleanQuery(String searchQuery1,
String searchQuery2) throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term1 = new Term(LuceneConstants.FILE_NAME, searchQuery1);
//create the term query object
Query query1 = new TermQuery(term1);
Term term2 = new Term(LuceneConstants.FILE_NAME, searchQuery2);
//create the term query object
Query query2 = new PrefixQuery(term2);
BooleanQuery query = new BooleanQuery.Builder()
.add(query1,BooleanClause.Occur.MUST_NOT)
.add(query2,BooleanClause.Occur.MUST)
.build();
TopDocs hits = searcher.search(query);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
}
Example Application
To test search using BooleanQuery, let us create a test Lucene application.
| Step | Description |
|---|---|
| 1 | Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene - First Application chapter. You can also use the project created in Lucene - First Application chapter as such for this chapter to understand the searching process. |
| 2 | Create LuceneConstants.java and Searcher.java as explained in the Lucene - First Application chapter. Keep the rest of the files unchanged. |
| 3 | Create LuceneTester.java as mentioned below. |
| 4 | Clean and Build the application to make sure business logic is working as per the requirements. |
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
Searcher.java
This class is used to read the indexes made on raw data and searches data using the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.nio.file.Paths;
import java.text.ParseException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.QueryBuilder;
public class Searcher {
IndexSearcher indexSearcher;
QueryBuilder queryBuilder;
Query query;
public Searcher(String indexDirectoryPath)
throws IOException {
DirectoryReader indexDirectory = DirectoryReader.open(FSDirectory.open(Paths.get(indexDirectoryPath)));
indexSearcher = new IndexSearcher(indexDirectory);
StandardAnalyzer analyzer = new StandardAnalyzer();
queryBuilder = new QueryBuilder(analyzer);
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryBuilder.createPhraseQuery(LuceneConstants.CONTENTS, searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public TopDocs search(Query query) throws IOException, ParseException {
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc) throws CorruptIndexException, IOException {
return indexSearcher.storedFields().document(scoreDoc.doc);
}
}
LuceneTester.java
This class is used to test the searching capability of the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.text.ParseException;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.BooleanClause;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.PrefixQuery;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "D:\\Lucene\\Index";
String dataDir = "D:\\Lucene\\Data";
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.searchUsingBooleanQuery("record1.txt","record1");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void searchUsingBooleanQuery(String searchQuery1,
String searchQuery2)throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term1 = new Term(LuceneConstants.FILE_NAME, searchQuery1);
//create the term query object
Query query1 = new TermQuery(term1);
Term term2 = new Term(LuceneConstants.FILE_NAME, searchQuery2);
//create the term query object
Query query2 = new PrefixQuery(term2);
BooleanQuery query = new BooleanQuery.Builder()
.add(query1,BooleanClause.Occur.MUST_NOT)
.add(query2,BooleanClause.Occur.MUST)
.build();
TopDocs hits = searcher.search(query);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
}
}
Data & Index Directory Creation
I've used 10 text files from record1.txt to record10.txt containing names and other details of the students and put them in the directory D:\Lucene\Data. Test Data. An index directory path should be created as D:\Lucene\Index. After running the indexing program in the chapter Lucene - Indexing Process, you can see the list of index files created in that folder.
Running the Program
Once you are done with the creation of the source, the raw data, the data directory, the index directory and the indexes, you can proceed by compiling and running your program. To do this, keep the LuceneTester.Java file tab active and use either the Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If your application runs successfully, it will print the following message in Eclipse IDE's console −
Output
1 hits documents found. Time :96ms File: D:\lucene\Data\record10.txt
Lucene - PhraseQuery
PhraseQuery class is used to search documents which contain a particular sequence of terms.
Class Declaration
Following is the declaration for org.apache.lucene.search.PhraseQuery class −
public class PhraseQuery extends Query
| S.No. | Constructor & Description |
|---|---|
| 1 |
PhraseQuery(int slop, String field, String... terms) Create a phrase query which will match documents that contain the given list of terms at consecutive positions in field, and at a maximum edit distance of slop. |
| 2 |
PhraseQuery(int slop, String field, BytesRef... terms) Create a phrase query which will match documents that contain the given list of terms at consecutive positions in field, and at a maximum edit distance of slop. |
| 3 |
PhraseQuery(String field, String... terms) Create a phrase query which will match documents that contain the given list of terms at consecutive positions in field. |
| 4 |
PhraseQuery(String field, BytesRef... terms) Create a phrase query which will match documents that contain the given list of terms at consecutive positions in field. |
| S.No. | Method & Description |
|---|---|
| 1 |
List<BooleanClause> clauses() Return a list of the clauses of this BooleanQuery. |
| 2 |
Weight createWeight(IndexSearcher searcher, ScoreMode scoreMode, float boost) Expert: Constructs an appropriate Weight implementation for this query. |
| 3 |
boolean equals(Object other) Returns true iff o is equal to this. |
| 4 |
String getField() Returns the field this query applies to |
| 5 |
int[] getPositions() Returns the relative positions of terms in this phrase. |
| 6 |
int getSlop() Return the slop for this PhraseQuery. |
| 7 |
Term[] getTerms() Returns the list of terms in this phrase. |
| 8 |
int hashCode() Returns a hash code value for this object. |
| 9 |
Query rewrite(IndexSearcher indexSearcher) Expert: called to re-write queries into primitive queries. |
| 10 |
static float termPositionsCost(TermsEnum termsEnum) Returns an expected cost in simple operations of processing the occurrences of a term in a document that contains the term. |
| 11 |
String toString(String f) Prints a user-readable version of this query. |
| 12 |
void visit(QueryVisitor visitor) Recurse through the query tree, visiting any child queries. |
Methods Inherited
This class inherits methods from the following classes −
- org.apache.lucene.search.Query
- java.lang.Object
Usage of PhraseQuery
private void searchUsingPhraseQuery(String[] phrases)
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
PhraseQuery.Builder queryBuilder = new PhraseQuery.Builder();
queryBuilder.setSlop(0);
for(String word:phrases) {
queryBuilder.add(new Term(LuceneConstants.FILE_NAME,word));
}
PhraseQuery query = queryBuilder.build();
//do the search
TopDocs hits = searcher.search(query);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
}
Example Application
To test search using BooleanQuery, let us create a test Lucene application.
| Step | Description |
|---|---|
| 1 | Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene - First Application chapter. You can also use the project created in Lucene - First Application chapter as such for this chapter to understand the searching process. |
| 2 | Create LuceneConstants.java and Searcher.java as explained in the Lucene - First Application chapter. Keep the rest of the files unchanged. |
| 3 | Create LuceneTester.java as mentioned below. |
| 4 | Clean and Build the application to make sure business logic is working as per the requirements. |
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
Searcher.java
This class is used to read the indexes made on raw data and searches data using the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.nio.file.Paths;
import java.text.ParseException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.QueryBuilder;
public class Searcher {
IndexSearcher indexSearcher;
QueryBuilder queryBuilder;
Query query;
public Searcher(String indexDirectoryPath)
throws IOException {
DirectoryReader indexDirectory = DirectoryReader.open(FSDirectory.open(Paths.get(indexDirectoryPath)));
indexSearcher = new IndexSearcher(indexDirectory);
StandardAnalyzer analyzer = new StandardAnalyzer();
queryBuilder = new QueryBuilder(analyzer);
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryBuilder.createPhraseQuery(LuceneConstants.CONTENTS, searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public TopDocs search(Query query) throws IOException, ParseException {
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc) throws CorruptIndexException, IOException {
return indexSearcher.storedFields().document(scoreDoc.doc);
}
}
LuceneTester.java
This class is used to test the searching capability of the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.text.ParseException;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.PhraseQuery;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "D:\\Lucene\\Index";
String dataDir = "D:\\Lucene\\Data";
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
String[] phrases = new String[]{"record1.txt"};
tester.searchUsingPhraseQuery(phrases);
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void searchUsingPhraseQuery(String[] phrases)
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
PhraseQuery.Builder queryBuilder = new PhraseQuery.Builder();
queryBuilder.setSlop(0);
for(String word:phrases) {
queryBuilder.add(new Term(LuceneConstants.FILE_NAME,word));
}
PhraseQuery query = queryBuilder.build();
//do the search
TopDocs hits = searcher.search(query);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
}
}
Data & Index Directory Creation
I've used 10 text files from record1.txt to record10.txt containing names and other details of the students and put them in the directory D:\Lucene\Data. Test Data. An index directory path should be created as D:\Lucene\Index. After running the indexing program in the chapter Lucene - Indexing Process, you can see the list of index files created in that folder.
Running the Program
Once you are done with the creation of the source, the raw data, the data directory, the index directory and the indexes, you can proceed by compiling and running your program. To do this, keep the LuceneTester.Java file tab active and use either the Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If your application runs successfully, it will print the following message in Eclipse IDE's console −
Output
1 hits documents found. Time :31ms File: D:\lucene\Data\record1.txt
Lucene - WildCardQuery
WildCardQuery class is used to search documents using wildcards like '*' for any character sequence, matching a single character.
Class Declaration
Following is the declaration for org.apache.lucene.search.WildCardQuery class −
public class WildcardQuery extends AutomatonQuery
| S.No. | Method & Description |
|---|---|
| 1 |
static final char WILDCARD_CHAR Char equality with support for wildcards |
| 2 |
static final char WILDCARD_ESCAPE Escape character |
| 3 |
static final char WILDCARD_STRING String equality with support for wildcards |
| S.No. | Constructor & Description |
|---|---|
| 1 |
WildcardQuery(Term term) Constructs a query for terms matching term. |
| 2 |
WildcardQuery(Term term, int determinizeWorkLimit) Constructs a query for terms matching term. |
| 3 |
WildcardQuery(Term term, int determinizeWorkLimit, MultiTermQuery.RewriteMethod rewriteMethod) Constructs a query for terms matching term. |
| S.No. | Method & Description |
|---|---|
| 1 |
Term getTerm() Returns the pattern term. |
| 2 |
static Automaton toAutomaton(Term wildcardquery, int determinizeWorkLimit) Convert Lucene wildcard syntax into an automaton. |
| 3 |
String toString(String field) Prints a user-readable version of this query. |
Methods Inherited
This class inherits methods from the following classes −
- org.apache.lucene.search.AutomatonQuery
- org.apache.lucene.search.MultiTermQuery
- org.apache.lucene.search.Query
- java.lang.Object
Usage of WildCardQuery
private void searchUsingWildCardQuery(String searchQuery)
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term = new Term(LuceneConstants.FILE_NAME, searchQuery);
//create the term query object
Query query = new WildcardQuery(term);
//do the search
TopDocs hits = searcher.search(query);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
}
Example Application
To test search using BooleanQuery, let us create a test Lucene application.
| Step | Description |
|---|---|
| 1 | Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene - First Application chapter. You can also use the project created in Lucene - First Application chapter as such for this chapter to understand the searching process. |
| 2 | Create LuceneConstants.java and Searcher.java as explained in the Lucene - First Application chapter. Keep the rest of the files unchanged. |
| 3 | Create LuceneTester.java as mentioned below. |
| 4 | Clean and Build the application to make sure business logic is working as per the requirements. |
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
Searcher.java
This class is used to read the indexes made on raw data and searches data using the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.nio.file.Paths;
import java.text.ParseException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.QueryBuilder;
public class Searcher {
IndexSearcher indexSearcher;
QueryBuilder queryBuilder;
Query query;
public Searcher(String indexDirectoryPath)
throws IOException {
DirectoryReader indexDirectory = DirectoryReader.open(FSDirectory.open(Paths.get(indexDirectoryPath)));
indexSearcher = new IndexSearcher(indexDirectory);
StandardAnalyzer analyzer = new StandardAnalyzer();
queryBuilder = new QueryBuilder(analyzer);
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryBuilder.createPhraseQuery(LuceneConstants.CONTENTS, searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public TopDocs search(Query query) throws IOException, ParseException {
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc) throws CorruptIndexException, IOException {
return indexSearcher.storedFields().document(scoreDoc.doc);
}
}
LuceneTester.java
This class is used to test the searching capability of the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.text.ParseException;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.search.WildcardQuery;
public class LuceneTester {
String indexDir = "D:\\Lucene\\Index";
String dataDir = "D:\\Lucene\\Data";
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.searchUsingWildCardQuery("record1*");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void searchUsingWildCardQuery(String searchQuery)
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term = new Term(LuceneConstants.FILE_NAME, searchQuery);
//create the term query object
Query query = new WildcardQuery(term);
//do the search
TopDocs hits = searcher.search(query);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
}
}
Data & Index Directory Creation
I've used 10 text files from record1.txt to record10.txt containing names and other details of the students and put them in the directory D:\Lucene\Data. Test Data. An index directory path should be created as D:\Lucene\Index. After running the indexing program in the chapter Lucene - Indexing Process, you can see the list of index files created in that folder.
Running the Program
Once you are done with the creation of the source, the raw data, the data directory, the index directory and the indexes, you can proceed by compiling and running your program. To do this, keep the LuceneTester.Java file tab active and use either the Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If your application runs successfully, it will print the following message in Eclipse IDE's console −
Output
2 hits documents found. Time :70ms File: D:\lucene\Data\record1.txt File: D:\lucene\Data\record10.txt
Lucene - FuzzyQuery
FuzzyQuery class is used to search documents using fuzzy implementation that is an approximate search based on the edit distance algorithm.
Class Declaration
Following is the declaration for org.apache.lucene.search.FuzzyQuery class −
public class FuzzyQuery extends MultiTermQuery
| S.No. | Method & Description |
|---|---|
| 1 |
static final int defaultMaxEdits
|
| 2 |
static final int defaultMaxExpansions
|
| 3 |
static final int defaultPrefixLength
|
| 4 |
static final boolean defaultTranspositions
|
| S.No. | Constructor & Description |
|---|---|
| 1 |
FuzzyQuery(Term term) Calls FuzzyQuery(term, defaultMaxEdits). |
| 2 |
FuzzyQuery(Term term, int maxEdits) Calls FuzzyQuery(term, maxEdits, defaultPrefixLength). |
| 3 |
FuzzyQuery(Term term, int maxEdits, int prefixLength) Calls FuzzyQuery(term, maxEdits, prefixLength, defaultMaxExpansions, defaultTranspositions). |
| 4 |
FuzzyQuery(Term term, int maxEdits, int prefixLength, int maxExpansions, boolean transpositions) Calls FuzzyQuery(Term, int, int, int, boolean, org.apache.lucene.search.MultiTermQuery.RewriteMethod) FuzzyQuery(term, maxEdits, prefixLength, maxExpansions, defaultRewriteMethod(maxExpansions)) |
| 5 |
FuzzyQuery(Term term, int maxEdits, int prefixLength, int maxExpansions, boolean transpositions, MultiTermQuery.RewriteMethod rewriteMethod) Create a new FuzzyQuery that will match terms with an edit distance of at most maxEdits to term. |
| S.No. | Method & Description |
|---|---|
| 1 |
static MultiTermQuery.RewriteMethod defaultRewriteMethod(int maxExpansions) Creates a default top-terms blended frequency scoring rewrite with the given max expansions. |
| 2 |
boolean equals(Object obj) Override and implement query instance equivalence properly in a subclass. |
| 3 |
static int floatToEdits(float minimumSimilarity, int termLen) Helper function to convert from "minimumSimilarity" fractions to raw edit distances. |
| 4 |
CompiledAutomaton getAutomata() Returns the compiled automata used to match terms. |
| 5 |
static CompiledAutomaton getFuzzyAutomaton(String term, int maxEdits, int prefixLength, boolean transpositions) Returns the CompiledAutomaton internally used by FuzzyQuery to match terms. |
| 6 |
int getMaxEdits()
|
| 7 |
int getPrefixLength() Returns the non-fuzzy prefix length. |
| 8 |
Term getTerm() Returns the pattern term. |
| 9 |
protected TermsEnum getTermsEnum(Terms terms, AttributeSource atts) Construct the enumeration to be used, expanding the pattern term. |
| 10 |
boolean getTranspositions() Returns true if transpositions should be treated as a primitive edit operation. |
| 11 |
int hashCode() Override and implement query hash code properly in a subclass. |
| 12 |
String toString(String field) Prints a query to a string, with field assumed to be the default field and omitted. |
| 13 |
void visit(QueryVisitor visitor) Recurse through the query tree, visiting any child queries. |
Methods Inherited
This class inherits methods from the following classes −
- org.apache.lucene.search.MultiTermQuery
- org.apache.lucene.search.Query
- java.lang.Object
Usage of FuzzyQuery
private void searchUsingFuzzyQuery(String searchQuery)
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term = new Term(LuceneConstants.FILE_NAME, searchQuery);
//create the term query object
Query query = new FuzzyQuery(term);
//do the search
TopDocs hits = searcher.search(query);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.print("Score: "+ scoreDoc.score + " ");
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
}
Example Application
To test search using BooleanQuery, let us create a test Lucene application.
| Step | Description |
|---|---|
| 1 | Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene - First Application chapter. You can also use the project created in Lucene - First Application chapter as such for this chapter to understand the searching process. |
| 2 | Create LuceneConstants.java and Searcher.java as explained in the Lucene - First Application chapter. Keep the rest of the files unchanged. |
| 3 | Create LuceneTester.java as mentioned below. |
| 4 | Clean and Build the application to make sure business logic is working as per the requirements. |
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
Searcher.java
This class is used to read the indexes made on raw data and searches data using the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.nio.file.Paths;
import java.text.ParseException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.QueryBuilder;
public class Searcher {
IndexSearcher indexSearcher;
QueryBuilder queryBuilder;
Query query;
public Searcher(String indexDirectoryPath)
throws IOException {
DirectoryReader indexDirectory = DirectoryReader.open(FSDirectory.open(Paths.get(indexDirectoryPath)));
indexSearcher = new IndexSearcher(indexDirectory);
StandardAnalyzer analyzer = new StandardAnalyzer();
queryBuilder = new QueryBuilder(analyzer);
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryBuilder.createPhraseQuery(LuceneConstants.CONTENTS, searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public TopDocs search(Query query) throws IOException, ParseException {
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc) throws CorruptIndexException, IOException {
return indexSearcher.storedFields().document(scoreDoc.doc);
}
}
LuceneTester.java
This class is used to test the searching capability of the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.text.ParseException;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.FuzzyQuery;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "D:\\Lucene\\Index";
String dataDir = "D:\\Lucene\\Data";
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.searchUsingFuzzyQuery("cord3.txt");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void searchUsingFuzzyQuery(String searchQuery)
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term = new Term(LuceneConstants.FILE_NAME, searchQuery);
//create the term query object
Query query = new FuzzyQuery(term);
//do the search
TopDocs hits = searcher.search(query);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.print("Score: "+ scoreDoc.score + " ");
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
}
}
Data & Index Directory Creation
I've used 10 text files from record1.txt to record10.txt containing names and other details of the students and put them in the directory D:\Lucene\Data. Test Data. An index directory path should be created as D:\Lucene\Index. After running the indexing program in the chapter Lucene - Indexing Process, you can see the list of index files created in that folder.
Running the Program
Once you are done with the creation of the source, the raw data, the data directory, the index directory and the indexes, you can proceed by compiling and running your program. To do this, keep the LuceneTester.Java file tab active and use either the Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If your application runs successfully, it will print the following message in Eclipse IDE's console −
Output
1 hits documents found. Time :89ms Score: 0.73515606 File: D:\lucene\Data\record3.txt
Lucene - MatchAllDocsQuery
MatchAllDocsQuery class as the name suggests, matches all the documents.
Class Declaration
Following is the declaration for org.apache.lucene.search.MatchAllDocsQuery class −
public class MatchAllDocsQuery extends Query
| S.No. | Constructor & Description |
|---|---|
| 1 |
MatchAllDocsQuery() Default Constructor |
| S.No. | Method & Description |
|---|---|
| 1 |
Weight createWeight(IndexSearcher searcher, ScoreMode scoreMode, float boost) Expert: Constructs an appropriate Weight implementation for this query. |
| 2 |
boolean equals(Object obj) Override and implement query instance equivalence properly in a subclass. |
| 3 |
int hashCode() Override and implement query hash code properly in a subclass. |
| 4 |
String toString(String field) Prints a query to a string, with field assumed to be the default field and omitted. |
| 5 |
void visit(QueryVisitor visitor) Recurse through the query tree, visiting any child queries. |
Methods Inherited
This class inherits methods from the following classes −
- org.apache.lucene.search.Query
- java.lang.Object
Usage of MatchAllDocsQuery
private void searchUsingMatchAllDocsQuery()
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create the term query object
Query query = new MatchAllDocsQuery();
//do the search
TopDocs hits = searcher.search(query);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.print("Score: "+ scoreDoc.score + " ");
System.out.println("Doc ID: " + scoreDoc.doc);
}
}
Example Application
To test search using BooleanQuery, let us create a test Lucene application.
| Step | Description |
|---|---|
| 1 | Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene - First Application chapter. You can also use the project created in Lucene - First Application chapter as such for this chapter to understand the searching process. |
| 2 | Create LuceneConstants.java and Searcher.java as explained in the Lucene - First Application chapter. Keep the rest of the files unchanged. |
| 3 | Create LuceneTester.java as mentioned below. |
| 4 | Clean and Build the application to make sure business logic is working as per the requirements. |
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
Searcher.java
This class is used to read the indexes made on raw data and searches data using the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.nio.file.Paths;
import java.text.ParseException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.QueryBuilder;
public class Searcher {
IndexSearcher indexSearcher;
QueryBuilder queryBuilder;
Query query;
public Searcher(String indexDirectoryPath)
throws IOException {
DirectoryReader indexDirectory = DirectoryReader.open(FSDirectory.open(Paths.get(indexDirectoryPath)));
indexSearcher = new IndexSearcher(indexDirectory);
StandardAnalyzer analyzer = new StandardAnalyzer();
queryBuilder = new QueryBuilder(analyzer);
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryBuilder.createPhraseQuery(LuceneConstants.CONTENTS, searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public TopDocs search(Query query) throws IOException, ParseException {
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc) throws CorruptIndexException, IOException {
return indexSearcher.storedFields().document(scoreDoc.doc);
}
}
LuceneTester.java
This class is used to test the searching capability of the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.text.ParseException;
import org.apache.lucene.document.Document;
import org.apache.lucene.search.MatchAllDocsQuery;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "D:\\Lucene\\Index";
String dataDir = "D:\\Lucene\\Data";
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.searchUsingMatchAllDocsQuery();
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void searchUsingMatchAllDocsQuery()
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create the term query object
Query query = new MatchAllDocsQuery();
//do the search
TopDocs hits = searcher.search(query);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.print("Score: "+ scoreDoc.score + " ");
System.out.println("Doc ID: " + scoreDoc.doc);
}
}
}
Data & Index Directory Creation
I've used 10 text files from record1.txt to record10.txt containing names and other details of the students and put them in the directory D:\Lucene\Data. Test Data. An index directory path should be created as D:\Lucene\Index. After running the indexing program in the chapter Lucene - Indexing Process, you can see the list of index files created in that folder.
Running the Program
Once you are done with the creation of the source, the raw data, the data directory, the index directory and the indexes, you can proceed by compiling and running your program. To do this, keep the LuceneTester.Java file tab active and use either the Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If your application runs successfully, it will print the following message in Eclipse IDE's console −
Output
10 hits documents found. Time :12ms Score: 1.0 Doc ID: 1 Score: 1.0 Doc ID: 2 Score: 1.0 Doc ID: 3 Score: 1.0 Doc ID: 4 Score: 1.0 Doc ID: 5 Score: 1.0 Doc ID: 6 Score: 1.0 Doc ID: 7 Score: 1.0 Doc ID: 8 Score: 1.0 Doc ID: 9 Score: 1.0 Doc ID: 10
Lucene - MatchNoDocsQuery
MatchNoDocsQuery class as the name suggests, matches no documents.
Class Declaration
Following is the declaration for org.apache.lucene.search.MatchNoDocsQuery class −
public class MatchNoDocsQuery extends Query
| S.No. | Constructor & Description |
|---|---|
| 1 |
MatchNoDocsQuery() Default Constructor |
| 2 |
MatchNoDocsQuery(String reason) Provides a reason explaining why this query was used. |
| S.No. | Method & Description |
|---|---|
| 1 |
Weight createWeight(IndexSearcher searcher, ScoreMode scoreMode, float boost) Expert: Constructs an appropriate Weight implementation for this query. |
| 2 |
boolean equals(Object obj) Override and implement query instance equivalence properly in a subclass. |
| 3 |
int hashCode() Override and implement query hash code properly in a subclass. |
| 4 |
String toString(String field) Prints a query to a string, with field assumed to be the default field and omitted. |
| 5 |
void visit(QueryVisitor visitor) Recurse through the query tree, visiting any child queries. |
Methods Inherited
This class inherits methods from the following classes −
- org.apache.lucene.search.Query
- java.lang.Object
Usage of MatchNoDocsQuery
private void searchUsingMatchNoDocsQuery()
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create the term query object
Query query = new MatchNoDocsQuery();
//do the search
TopDocs hits = searcher.search(query);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.print("Score: "+ scoreDoc.score + " ");
System.out.println("Doc ID: " + scoreDoc.doc);
}
}
Example Application
To test search using BooleanQuery, let us create a test Lucene application.
| Step | Description |
|---|---|
| 1 | Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene - First Application chapter. You can also use the project created in Lucene - First Application chapter as such for this chapter to understand the searching process. |
| 2 | Create LuceneConstants.java and Searcher.java as explained in the Lucene - First Application chapter. Keep the rest of the files unchanged. |
| 3 | Create LuceneTester.java as mentioned below. |
| 4 | Clean and Build the application to make sure business logic is working as per the requirements. |
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
Searcher.java
This class is used to read the indexes made on raw data and searches data using the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.nio.file.Paths;
import java.text.ParseException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.QueryBuilder;
public class Searcher {
IndexSearcher indexSearcher;
QueryBuilder queryBuilder;
Query query;
public Searcher(String indexDirectoryPath)
throws IOException {
DirectoryReader indexDirectory = DirectoryReader.open(FSDirectory.open(Paths.get(indexDirectoryPath)));
indexSearcher = new IndexSearcher(indexDirectory);
StandardAnalyzer analyzer = new StandardAnalyzer();
queryBuilder = new QueryBuilder(analyzer);
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryBuilder.createPhraseQuery(LuceneConstants.CONTENTS, searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public TopDocs search(Query query) throws IOException, ParseException {
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc) throws CorruptIndexException, IOException {
return indexSearcher.storedFields().document(scoreDoc.doc);
}
}
LuceneTester.java
This class is used to test the searching capability of the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.text.ParseException;
import org.apache.lucene.document.Document;
import org.apache.lucene.search.MatchNoDocsQuery;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "D:\\Lucene\\Index";
String dataDir = "D:\\Lucene\\Data";
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.searchUsingMatchNoDocsQuery();
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void searchUsingMatchNoDocsQuery()
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create the term query object
Query query = new MatchNoDocsQuery();
//do the search
TopDocs hits = searcher.search(query);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.print("Score: "+ scoreDoc.score + " ");
System.out.println("Doc ID: " + scoreDoc.doc);
}
}
}
Data & Index Directory Creation
I've used 10 text files from record1.txt to record10.txt containing names and other details of the students and put them in the directory D:\Lucene\Data. Test Data. An index directory path should be created as D:\Lucene\Index. After running the indexing program in the chapter Lucene - Indexing Process, you can see the list of index files created in that folder.
Running the Program
Once you are done with the creation of the source, the raw data, the data directory, the index directory and the indexes, you can proceed by compiling and running your program. To do this, keep the LuceneTester.Java file tab active and use either the Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If your application runs successfully, it will print the following message in Eclipse IDE's console −
Output
0 hits documents found. Time :9ms
Lucene - RegexpQuery
RegexpQuery class represents a Regular Expression based Query. RegexpQuery comparisons are quiet fast.
Class Declaration
Following is the declaration for org.apache.lucene.search.RegexpQuery class −
public class RegexpQuery extends AutomatonQuery
| S.No. | Field & Description |
|---|---|
| 1 |
static final AutomatonProvider DEFAULT_PROVIDER A provider that provides no named automata. |
| S.No. | Constructor & Description |
|---|---|
| 1 |
RegexpQuery(Term term) Constructs a query for terms matching term. |
| 2 |
RegexpQuery(Term term, int flags) Constructs a query for terms matching term. |
| 3 |
RegexpQuery(Term term, int flags, int determinizeWorkLimit) Constructs a query for terms matching term. |
| 4 |
RegexpQuery(Term term, int syntaxFlags, int matchFlags, int determinizeWorkLimit) Constructs a query for terms matching term. |
| 5 |
RegexpQuery(Term term, int syntaxFlags, int matchFlags, AutomatonProvider provider, int determinizeWorkLimit, MultiTermQuery.RewriteMethod rewriteMethod) Constructs a query for terms matching term. |
| 6 |
RegexpQuery(Term term, int syntaxFlags, int matchFlags, AutomatonProvider provider, int determinizeWorkLimit, MultiTermQuery.RewriteMethod rewriteMethod, boolean doDeterminization) Constructs a query for terms matching term. |
| 7 |
RegexpQuery(Term term, int syntaxFlags, AutomatonProvider provider, int determinizeWorkLimit) Constructs a query for terms matching term. |
| S.No. | Method & Description |
|---|---|
| 1 |
Term getRegexp() Returns the regexp of this query wrapped in a Term. |
| 2 |
String toString(String field) Prints a user-readable version of this query. |
Methods Inherited
This class inherits methods from the following classes −
- org.apache.lucene.search.AutomatonQuery
- org.apache.lucene.search.MultiTermQuery
- org.apache.lucene.search.Query
- java.lang.Object
Usage of RegexpQuery
private void searchUsingRegexpQuery(String searchQuery)
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term = new Term(LuceneConstants.FILE_NAME, searchQuery);
//create the term query object
Query query = new RegexpQuery(term);
//do the search
TopDocs hits = searcher.search(query);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
}
Example Application
To test search using BooleanQuery, let us create a test Lucene application.
| Step | Description |
|---|---|
| 1 | Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene - First Application chapter. You can also use the project created in Lucene - First Application chapter as such for this chapter to understand the searching process. |
| 2 | Create LuceneConstants.java and Searcher.java as explained in the Lucene - First Application chapter. Keep the rest of the files unchanged. |
| 3 | Create LuceneTester.java as mentioned below. |
| 4 | Clean and Build the application to make sure business logic is working as per the requirements. |
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
Searcher.java
This class is used to read the indexes made on raw data and searches data using the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.nio.file.Paths;
import java.text.ParseException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.QueryBuilder;
public class Searcher {
IndexSearcher indexSearcher;
QueryBuilder queryBuilder;
Query query;
public Searcher(String indexDirectoryPath)
throws IOException {
DirectoryReader indexDirectory = DirectoryReader.open(FSDirectory.open(Paths.get(indexDirectoryPath)));
indexSearcher = new IndexSearcher(indexDirectory);
StandardAnalyzer analyzer = new StandardAnalyzer();
queryBuilder = new QueryBuilder(analyzer);
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryBuilder.createPhraseQuery(LuceneConstants.CONTENTS, searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public TopDocs search(Query query) throws IOException, ParseException {
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc) throws CorruptIndexException, IOException {
return indexSearcher.storedFields().document(scoreDoc.doc);
}
}
LuceneTester.java
This class is used to test the searching capability of the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.text.ParseException;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.search.RegexpQuery;
public class LuceneTester {
String indexDir = "D:\\Lucene\\Index";
String dataDir = "D:\\Lucene\\Data";
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.searchUsingRegexpQuery("record1*.txt");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void searchUsingRegexpQuery(String searchQuery)
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term = new Term(LuceneConstants.FILE_NAME, searchQuery);
//create the term query object
Query query = new RegexpQuery(term);
//do the search
TopDocs hits = searcher.search(query);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
}
}
Data & Index Directory Creation
I've used 10 text files from record1.txt to record10.txt containing names and other details of the students and put them in the directory D:\Lucene\Data. Test Data. An index directory path should be created as D:\Lucene\Index. After running the indexing program in the chapter Lucene - Indexing Process, you can see the list of index files created in that folder.
Running the Program
Once you are done with the creation of the source, the raw data, the data directory, the index directory and the indexes, you can proceed by compiling and running your program. To do this, keep the LuceneTester.Java file tab active and use either the Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If your application runs successfully, it will print the following message in Eclipse IDE's console −
Output
1 hits documents found. Time :53ms File: D:\lucene\Data\record1.txt
Lucene - Analysis
In one of our previous chapters, we have seen that Lucene uses IndexWriter to analyze the Document(s) using the Analyzer and then creates/open/edit indexes as required. In this chapter, we are going to discuss the various types of Analyzer objects and other relevant objects which are used during the analysis process. Understanding the Analysis process and how analyzers work will give you great insight over how Lucene indexes the documents.
Important Analyzer
Following is the list of objects that we'll discuss in due course.
| S.No. | Class & Description |
|---|---|
| 1 |
WhitespaceAnalyzer
This analyzer splits the text in a document based on whitespace. |
| 2 |
SimpleAnalyzer
This analyzer splits the text in a document based on non-letter characters and puts the text in lowercase. |
| 3 |
StopAnalyzer
This analyzer works just as the SimpleAnalyzer and removes the common words like 'a', 'an', 'the', etc. |
| 4 |
StandardAnalyzer
This is the most sophisticated analyzer and is capable of handling names, email addresses, etc. It lowercases each token and removes common words and punctuations, if any. |
| 5 |
KeywordAnalyzer
This analyzer treats entire stream as a token. It is best suited for identifiers, zip codes, product names etc. |
| 6 |
CustomAnalyzer
We can create our own custom analyzer as per custom requirements using CustomAnalyzer.builder() method. |
| 7 | EnglishAnalyzer
Analyzer for English language. |
| 8 | FrenchAnalyzer
Analyzer for French language. |
| 9 | Lucene - SpanishAnalyzer
Analyzer for Spanish language. |
Lucene - WhitespaceAnalyzer Analyzer
WhitespaceAnalyzer splits the text in a document based on whitespace.
Class Declaration
Following is the declaration for org.apache.lucene.analysis.core.WhitespaceAnalyzer class −
public final class WhitespaceAnalyzer extends Analyzer
| S.No. | Constructor & Description |
|---|---|
| 1 |
WhitespaceAnalyzer() Creates a new WhitespaceAnalyzer with a maximum token length of 255 chars. |
| 2 |
WhitespaceAnalyzer(int maxTokenLength) Creates a new WhitespaceAnalyzer with a custom maximum token length. |
| S.No. | Method & Description |
|---|---|
| 1 |
protected Analyzer.TokenStreamComponents createComponents(String fieldName) Creates a new Analyzer.TokenStreamComponents instance for this analyzer. |
Methods Inherited
This class inherits methods from the following classes −
- org.apache.lucene.analysis.Analyzer
- java.lang.Object
Usage of WhitespaceAnalyzer
private void displayTokenUsingWhitespaceAnalyzer() throws IOException {
String text
= "Lucene is simple yet powerful java based search library.";
Analyzer analyzer = new WhitespaceAnalyzer();
TokenStream tokenStream = analyzer.tokenStream(
LuceneConstants.CONTENTS, new StringReader(text));
CharTermAttribute term = tokenStream.addAttribute(CharTermAttribute.class);
tokenStream.reset();
while(tokenStream.incrementToken()) {
System.out.print("[" + term.toString() + "] ");
}
analyzer.close();
}
Example Application
To test search using WhitespaceAnalyzer, let us create a test Lucene application.
| Step | Description |
|---|---|
| 1 | Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene - First Application chapter. You can also use the project created in Lucene - First Application chapter as such for this chapter to understand the searching process. |
| 2 | Create LuceneConstants.java as explained in the Lucene - First Application chapter. Keep the rest of the files unchanged. |
| 3 | Create LuceneTester.java as mentioned below. |
| 4 | Clean and Build the application to make sure business logic is working as per the requirements. |
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
LuceneTester.java
This class is used to test the searching capability of the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.io.StringReader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.core.WhitespaceAnalyzer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
public class LuceneTester {
public static void main(String[] args) {
LuceneTester tester;
tester = new LuceneTester();
try {
tester.displayTokenUsingWhitespaceAnalyzer();
} catch (IOException e) {
e.printStackTrace();
}
}
private void displayTokenUsingWhitespaceAnalyzer() throws IOException {
String text
= "Lucene is simple yet powerful java based search library.";
Analyzer analyzer = new WhitespaceAnalyzer();
TokenStream tokenStream = analyzer.tokenStream(
LuceneConstants.CONTENTS, new StringReader(text));
CharTermAttribute term = tokenStream.addAttribute(CharTermAttribute.class);
tokenStream.reset();
while(tokenStream.incrementToken()) {
System.out.print("[" + term.toString() + "] ");
}
analyzer.close();
}
}
Running the Program
Once you are done with the creation of the source, the raw data, the data directory, the index directory and the indexes, you can proceed by compiling and running your program. To do this, keep the LuceneTester.Java file tab active and use either the Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If your application runs successfully, it will print the following message in Eclipse IDE's console −
Output
[lucene] [simple] [yet] [powerful] [java] [based] [search] [library]
Lucene - SimpleAnalyzer Analyzer
SimpleAnalyzer splits the text in a document based on non-letter characters and then puts them in lowercase.
Class Declaration
Following is the declaration for org.apache.lucene.analysis.core.SimpleAnalyzer class −
public final class SimpleAnalyzer extends Analyzer
| S.No. | Constructor & Description |
|---|---|
| 1 |
SimpleAnalyzer() Creates a new SimpleAnalyzer. |
| S.No. | Method & Description |
|---|---|
| 1 |
protected Analyzer.TokenStreamComponents createComponents(String fieldName) Creates a new Analyzer.TokenStreamComponents instance for this analyzer. |
| 2 |
protected TokenStream normalize(String fieldName, TokenStream in)
|
Methods Inherited
This class inherits methods from the following classes −
- org.apache.lucene.analysis.Analyzer
- java.lang.Object
Usage of SimpleAnalyzer
private void displayTokenUsingSimpleAnalyzer() throws IOException {
String text
= "Lucene is simple yet powerful java based search library.";
Analyzer analyzer = new SimpleAnalyzer();
TokenStream tokenStream = analyzer.tokenStream(
LuceneConstants.CONTENTS, new StringReader(text));
CharTermAttribute term = tokenStream.addAttribute(CharTermAttribute.class);
tokenStream.reset();
while(tokenStream.incrementToken()) {
System.out.print("[" + term.toString() + "] ");
}
analyzer.close();
}
Example Application
To test search using SimpleAnalyzer, let us create a test Lucene application.
| Step | Description |
|---|---|
| 1 | Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene - First Application chapter. You can also use the project created in Lucene - First Application chapter as such for this chapter to understand the searching process. |
| 2 | Create LuceneConstants.java as explained in the Lucene - First Application chapter. Keep the rest of the files unchanged. |
| 3 | Create LuceneTester.java as mentioned below. |
| 4 | Clean and Build the application to make sure business logic is working as per the requirements. |
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
LuceneTester.java
This class is used to test the searching capability of the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.io.StringReader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.core.SimpleAnalyzer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
public class LuceneTester {
public static void main(String[] args) {
LuceneTester tester;
tester = new LuceneTester();
try {
tester.displayTokenUsingSimpleAnalyzer();
} catch (IOException e) {
e.printStackTrace();
}
}
private void displayTokenUsingSimpleAnalyzer() throws IOException {
String text
= "Lucene is simple yet powerful java based search library.";
Analyzer analyzer = new SimpleAnalyzer();
TokenStream tokenStream = analyzer.tokenStream(
LuceneConstants.CONTENTS, new StringReader(text));
CharTermAttribute term = tokenStream.addAttribute(CharTermAttribute.class);
tokenStream.reset();
while(tokenStream.incrementToken()) {
System.out.print("[" + term.toString() + "] ");
}
analyzer.close();
}
}
Running the Program
Once you are done with the creation of the source, the raw data, the data directory, the index directory and the indexes, you can proceed by compiling and running your program. To do this, keep the LuceneTester.Java file tab active and use either the Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If your application runs successfully, it will print the following message in Eclipse IDE's console −
Output
[lucene] [simple] [yet] [powerful] [java] [based] [search] [library]
Lucene - StopAnalyzer Analyzer
StopAnalyzer works similar to SimpleAnalyzer and remove the common words like 'a', 'an', 'the', etc.
Class Declaration
Following is the declaration for org.apache.lucene.analysis.core.StopAnalyzer class −
public final class StopAnalyzer extends Analyzer
| S.No. | Constructor & Description |
|---|---|
| 1 |
StopAnalyzer(Reader stopwords) Builds an analyzer with the stop words from the given reader. |
| 2 |
StopAnalyzer(Reader stopwords) Builds an analyzer with the stop words from the given path. |
| 3 |
StopAnalyzer(CharArraySet stopWords) Builds an analyzer with the stop words from the given set. |
| S.No. | Method & Description |
|---|---|
| 1 |
protected Analyzer.TokenStreamComponents createComponents(String fieldName) Creates a new Analyzer.TokenStreamComponents used to tokenize all the text in the provided Reader. |
| 2 |
protected TokenStream normalize(String fieldName, TokenStream in)
|
Methods Inherited
This class inherits methods from the following classes −
- org.apache.lucene.analysis.StopwordAnalyzerBase
- org.apache.lucene.analysis.Analyzer
- java.lang.Object
Usage of StopAnalyzer
private void displayTokenUsingStopAnalyzer() throws IOException {
String text = "The Lucene is a simple yet powerful java based search library.";
Set<String> stopWords = new HashSet<>();
stopWords.add("a");
stopWords.add("an");
stopWords.add("the");
Analyzer analyzer = new StopAnalyzer(CharArraySet.copy(stopWords));
TokenStream tokenStream = analyzer.tokenStream(
LuceneConstants.CONTENTS, new StringReader(text));
CharTermAttribute term = tokenStream.addAttribute(CharTermAttribute.class);
tokenStream.reset();
while(tokenStream.incrementToken()) {
System.out.print("[" + term.toString() + "] ");
}
analyzer.close();
}
Example Application
To test search using StopAnalyzer, let us create a test Lucene application.
| Step | Description |
|---|---|
| 1 | Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene - First Application chapter. You can also use the project created in Lucene - First Application chapter as such for this chapter to understand the searching process. |
| 2 | Create LuceneConstants.java as explained in the Lucene - First Application chapter. Keep the rest of the files unchanged. |
| 3 | Create LuceneTester.java as mentioned below. |
| 4 | Clean and Build the application to make sure business logic is working as per the requirements. |
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
LuceneTester.java
This class is used to test the searching capability of the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.io.StringReader;
import java.util.HashSet;
import java.util.Set;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.CharArraySet;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.core.StopAnalyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
public class LuceneTester {
public static void main(String[] args) {
LuceneTester tester;
tester = new LuceneTester();
try {
tester.displayTokenUsingStopAnalyzer();
} catch (IOException e) {
e.printStackTrace();
}
}
private void displayTokenUsingStopAnalyzer() throws IOException {
String text
= "The Lucene is a simple yet powerful java based search library.";
Set<String> stopWords = new HashSet<>();
stopWords.add("a");
stopWords.add("an");
stopWords.add("the");
Analyzer analyzer = new StopAnalyzer(CharArraySet.copy(stopWords));
TokenStream tokenStream = analyzer.tokenStream(
LuceneConstants.CONTENTS, new StringReader(text));
CharTermAttribute term = tokenStream.addAttribute(CharTermAttribute.class);
tokenStream.reset();
while(tokenStream.incrementToken()) {
System.out.print("[" + term.toString() + "] ");
}
analyzer.close();
}
}
Running the Program
Once you are done with the creation of the source, the raw data, the data directory, the index directory and the indexes, you can proceed by compiling and running your program. To do this, keep the LuceneTester.Java file tab active and use either the Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If your application runs successfully, it will print the following message in Eclipse IDE's console −
Output
[lucene] [is] [simple] [yet] [powerful] [java] [based] [search] [library]
Lucene - StandardAnalyzer Analyzer
StandardAnalyzer is the most sophisticated analyzer and is capable of handling names, email addresses, etc. It lowercases each token and removes common words and punctuations, if any.
Class Declaration
Following is the declaration for org.apache.lucene.analysis.StandardAnalyzer class −
public final class StandardAnalyzer extends StopwordAnalyzerBase
| S.No. | Field & Description |
|---|---|
| 1 |
static final int DEFAULT_MAX_TOKEN_LENGTH Default maximum allowed token length. |
| S.No. | Constructor & Description |
|---|---|
| 1 |
StandardAnalyzer() Builds an analyzer with no stop words. |
| 2 |
StandardAnalyzer(Reader stopwords) Builds an analyzer with the stop words from the given reader. |
| 3 |
StandardAnalyzer(CharArraySet stopWords) Builds an analyzer with the given stop words. |
| S.No. | Method & Description |
|---|---|
| 1 |
protected Analyzer.TokenStreamComponents createComponents(String fieldName) Creates a new Analyzer.TokenStreamComponents instance for this analyzer. |
| 2 |
int getMaxTokenLength() Returns the current maximum token length. |
| 3 |
protected TokenStream normalize(String fieldName, TokenStream in) Wrap the given TokenStream in order to apply normalization filters. |
| 4 |
void setMaxTokenLength(int length) Set the max allowed token length. |
Methods Inherited
This class inherits methods from the following classes −
- org.apache.lucene.analysis.StopwordAnalyzerBase
- org.apache.lucene.analysis.Analyzer
- java.lang.Object
Usage of StandardAnalyzer
private void displayTokenUsingStandardAnalyzer() throws IOException {
String text
= "Lucene is simple yet powerful java based search library.";
Analyzer analyzer = new StandardAnalyzer();
TokenStream tokenStream = analyzer.tokenStream(
LuceneConstants.CONTENTS, new StringReader(text));
CharTermAttribute term = tokenStream.addAttribute(CharTermAttribute.class);
tokenStream.reset();
while(tokenStream.incrementToken()) {
System.out.print("[" + term.toString() + "] ");
}
analyzer.close();
}
Example Application
To test search using StandardAnalyzer, let us create a test Lucene application.
| Step | Description |
|---|---|
| 1 | Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene - First Application chapter. You can also use the project created in Lucene - First Application chapter as such for this chapter to understand the searching process. |
| 2 | Create LuceneConstants.java as explained in the Lucene - First Application chapter. Keep the rest of the files unchanged. |
| 3 | Create LuceneTester.java as mentioned below. |
| 4 | Clean and Build the application to make sure business logic is working as per the requirements. |
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
LuceneTester.java
This class is used to test the searching capability of the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.io.StringReader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
public class LuceneTester {
public static void main(String[] args) {
LuceneTester tester;
tester = new LuceneTester();
try {
tester.displayTokenUsingStandardAnalyzer();
} catch (IOException e) {
e.printStackTrace();
}
}
private void displayTokenUsingStandardAnalyzer() throws IOException {
String text
= "Lucene is simple yet powerful java based search library.";
Analyzer analyzer = new StandardAnalyzer();
TokenStream tokenStream = analyzer.tokenStream(
LuceneConstants.CONTENTS, new StringReader(text));
CharTermAttribute term = tokenStream.addAttribute(CharTermAttribute.class);
tokenStream.reset();
while(tokenStream.incrementToken()) {
System.out.print("[" + term.toString() + "] ");
}
analyzer.close();
}
}
Running the Program
Once you are done with the creation of the source, the raw data, the data directory, the index directory and the indexes, you can proceed by compiling and running your program. To do this, keep the LuceneTester.Java file tab active and use either the Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If your application runs successfully, it will print the following message in Eclipse IDE's console −
Output
[lucene] [simple] [yet] [powerful] [java] [based] [search] [library]
Lucene - KeywordAnalyzer Analyzer
KeywordAnalyzer analyzer treats entire stream as a token. It is best suited for identifiers, zip codes, product names etc.
Class Declaration
Following is the declaration for org.apache.lucene.analysis.core.KeywordAnalyzer class −
public final class KeywordAnalyzer extends Analyzer
| S.No. | Constructor & Description |
|---|---|
| 1 |
KeywordAnalyzer() Builds an analyzer. |
| S.No. | Method & Description |
|---|---|
| 1 |
protected Analyzer.TokenStreamComponents createComponents(String fieldName) Creates a new Analyzer.TokenStreamComponents. |
Methods Inherited
This class inherits methods from the following classes −
- org.apache.lucene.analysis.Analyzer
- java.lang.Object
Usage of KeywordAnalyzer
private void displayTokenUsingKeywordAnalyzer() throws IOException {
String text = "Lucene is simple yet powerful java based search library.";
Analyzer analyzer = new KeywordAnalyzer();
TokenStream tokenStream = analyzer.tokenStream(
LuceneConstants.CONTENTS, new StringReader(text));
CharTermAttribute term = tokenStream.addAttribute(CharTermAttribute.class);
tokenStream.reset();
while(tokenStream.incrementToken()) {
System.out.print("[" + term.toString() + "] ");
}
analyzer.close();
}
Example Application
To test search using StandardAnalyzer, let us create a test Lucene application.
| Step | Description |
|---|---|
| 1 | Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene - First Application chapter. You can also use the project created in Lucene - First Application chapter as such for this chapter to understand the searching process. |
| 2 | Create LuceneConstants.java as explained in the Lucene - First Application chapter. Keep the rest of the files unchanged. |
| 3 | Create LuceneTester.java as mentioned below. |
| 4 | Clean and Build the application to make sure business logic is working as per the requirements. |
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
LuceneTester.java
This class is used to test the searching capability of the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.io.StringReader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.core.KeywordAnalyzer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
public class LuceneTester {
public static void main(String[] args) {
LuceneTester tester;
tester = new LuceneTester();
try {
tester.displayTokenUsingKeywordAnalyzer();
} catch (IOException e) {
e.printStackTrace();
}
}
private void displayTokenUsingKeywordAnalyzer() throws IOException {
String text
= "Lucene is simple yet powerful java based search library.";
Analyzer analyzer = new KeywordAnalyzer();
TokenStream tokenStream = analyzer.tokenStream(
LuceneConstants.CONTENTS, new StringReader(text));
CharTermAttribute term = tokenStream.addAttribute(CharTermAttribute.class);
tokenStream.reset();
while(tokenStream.incrementToken()) {
System.out.print("[" + term.toString() + "] ");
}
analyzer.close();
}
}
Running the Program
Once you are done with the creation of the source, the raw data, the data directory, the index directory and the indexes, you can proceed by compiling and running your program. To do this, keep the LuceneTester.Java file tab active and use either the Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If your application runs successfully, it will print the following message in Eclipse IDE's console −
Output
[Lucene is simple yet powerful java based search library.]
Lucene - CustomAnalyzer
We can create our own custom analyzer as per custom requirements using CustomAnalyzer.builder() method.
Class Declaration
Following is the declaration for org.apache.lucene.analysis.core.CustomAnalyzer class −
public final class CustomAnalyzer extends Analyzer
| S.No. | Method & Description |
|---|---|
| 1 |
static CustomAnalyzer.Builder builder() Returns a builder for custom analyzers that loads all resources from Lucene's classloader. |
| 2 |
static CustomAnalyzer.Builder builder(Path configDir) Returns a builder for custom analyzers that loads all resources from the given file system base directory. |
| 3 |
static CustomAnalyzer.Builder builder(ResourceLoader loader) Returns a builder for custom analyzers that loads all resources using the given ResourceLoader. |
| 4 |
protected Analyzer.TokenStreamComponents createComponents(String fieldName)
|
| 5 |
List<CharFilterFactory> getCharFilterFactories() Returns the list of char filters that are used in this analyzer. |
| 6 |
int getOffsetGap(String fieldName)
|
| 7 |
int getPositionIncrementGap(String fieldName)
|
| 8 |
List<TokenFilterFactory> getTokenFilterFactories() Returns the list of token filters that are used in this analyzer. |
| 9 |
TokenizerFactory getTokenizerFactory() Returns the tokenizer that is used in this analyzer. |
| 10 |
protected Reader initReader(String fieldName, Reader reader)
|
| 11 |
protected Reader initReaderForNormalization(String fieldName, Reader reader)
|
| 12 |
protected TokenStream normalize(String fieldName, TokenStream in)
|
| 13 |
String toString() String representation of the analyzer. |
Methods Inherited
This class inherits methods from the following classes −
- org.apache.lucene.analysis.StopwordAnalyzerBase
- org.apache.lucene.analysis.Analyzer
- java.lang.Object
Usage of CustomAnalyzer
private void displayTokenUsingCustomAnalyzer() throws IOException {
String text
= "Lucene is simple yet powerful java based search library.";
Analyzer analyzer = CustomAnalyzer.builder()
.withTokenizer("standard")
.addTokenFilter("lowercase")
.addTokenFilter("stop")
.addTokenFilter("capitalization")
.build();
TokenStream tokenStream = analyzer.tokenStream(
LuceneConstants.CONTENTS, new StringReader(text));
CharTermAttribute term = tokenStream.addAttribute(CharTermAttribute.class);
tokenStream.reset();
while(tokenStream.incrementToken()) {
System.out.print("[" + term.toString() + "] ");
}
analyzer.close();
}
Example Application
To test search using CustomAnalyzer, let us create a test Lucene application.
| Step | Description |
|---|---|
| 1 | Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene - First Application chapter. You can also use the project created in Lucene - First Application chapter as such for this chapter to understand the searching process. |
| 2 | Create LuceneConstants.java as explained in the Lucene - First Application chapter. Keep the rest of the files unchanged. |
| 3 | Create LuceneTester.java as mentioned below. |
| 4 | Clean and Build the application to make sure business logic is working as per the requirements. |
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
LuceneTester.java
This class is used to test the searching capability of the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.io.StringReader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.custom.CustomAnalyzer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
public class LuceneTester {
public static void main(String[] args) {
LuceneTester tester;
tester = new LuceneTester();
try {
tester.displayTokenUsingCustomAnalyzer();
} catch (IOException e) {
e.printStackTrace();
}
}
private void displayTokenUsingCustomAnalyzer() throws IOException {
String text
= "Lucene is simple yet powerful java based search library.";
Analyzer analyzer = CustomAnalyzer.builder()
.withTokenizer("standard")
.addTokenFilter("lowercase")
.addTokenFilter("stop")
.addTokenFilter("capitalization")
.build();
TokenStream tokenStream = analyzer.tokenStream(
LuceneConstants.CONTENTS, new StringReader(text));
CharTermAttribute term = tokenStream.addAttribute(CharTermAttribute.class);
tokenStream.reset();
while(tokenStream.incrementToken()) {
System.out.print("[" + term.toString() + "] ");
}
analyzer.close();
}
}
Running the Program
Once you are done with the creation of the source, the raw data, the data directory, the index directory and the indexes, you can proceed by compiling and running your program. To do this, keep the LuceneTester.Java file tab active and use either the Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If your application runs successfully, it will print the following message in Eclipse IDE's console −
Output
[Lucene] [Simple] [Yet] [Powerful] [Java] [Based] [Search] [Library]
Lucene - EnglishAnalyzer
EnglishAnalyzer is a specific analyzer for English language.
Class Declaration
Following is the declaration for org.apache.lucene.analysis.en.EnglishAnalyzer class −
public final class EnglishAnalyzer extends StopwordAnalyzerBase
| S.No. | Field & Description |
|---|---|
| 1 |
static final CharArraySet ENGLISH_STOP_WORDS_SET An unmodifiable set containing some common English words that are not usually useful for searching. |
| S.No. | Constructor & Description |
|---|---|
| 1 |
EnglishAnalyzer() Builds an analyzer with the default stop words: getDefaultStopSet(). |
| 2 |
EnglishAnalyzer(CharArraySet stopwords) Builds an analyzer with the given stop words. |
| 3 |
EnglishAnalyzer(CharArraySet stopwords, CharArraySet stemExclusionSet) Builds an analyzer with the given stop words. |
| S.No. | Method & Description |
|---|---|
| 1 |
protected Analyzer.TokenStreamComponents createComponents(String fieldName) Creates a Analyzer.TokenStreamComponents which tokenizes all the text in the provided Reader. |
| 2 |
static CharArraySet getDefaultStopSet() Returns an unmodifiable instance of the default stop words set. |
| 3 |
protected TokenStream normalize(String fieldName, TokenStream in)
|
Methods Inherited
This class inherits methods from the following classes −
- org.apache.lucene.analysis.StopwordAnalyzerBase
- org.apache.lucene.analysis.Analyzer
- java.lang.Object
Usage of EnglishAnalyzer
private void displayTokenUsingEnglishAnalyzer() throws IOException {
String text = "Lucene is simple yet powerful java based search library.";
Analyzer analyzer = new EnglishAnalyzer();
TokenStream tokenStream = analyzer.tokenStream(
LuceneConstants.CONTENTS, new StringReader(text));
CharTermAttribute term = tokenStream.addAttribute(CharTermAttribute.class);
tokenStream.reset();
while(tokenStream.incrementToken()) {
System.out.print("[" + term.toString() + "] ");
}
analyzer.close();
}
Example Application
To test search using EnglishAnalyzer, let us create a test Lucene application.
| Step | Description |
|---|---|
| 1 | Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene - First Application chapter. You can also use the project created in Lucene - First Application chapter as such for this chapter to understand the searching process. |
| 2 | Create LuceneConstants.java as explained in the Lucene - First Application chapter. Keep the rest of the files unchanged. |
| 3 | Create LuceneTester.java as mentioned below. |
| 4 | Clean and Build the application to make sure business logic is working as per the requirements. |
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
LuceneTester.java
This class is used to test the searching capability of the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.io.StringReader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.en.EnglishAnalyzer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
public class LuceneTester {
public static void main(String[] args) {
LuceneTester tester;
tester = new LuceneTester();
try {
tester.displayTokenUsingEnglishAnalyzer();
} catch (IOException e) {
e.printStackTrace();
}
}
private void displayTokenUsingEnglishAnalyzer() throws IOException {
String text = "Lucene is simple yet powerful java based search library.";
Analyzer analyzer = new EnglishAnalyzer();
TokenStream tokenStream = analyzer.tokenStream(
LuceneConstants.CONTENTS, new StringReader(text));
CharTermAttribute term = tokenStream.addAttribute(CharTermAttribute.class);
tokenStream.reset();
while(tokenStream.incrementToken()) {
System.out.print("[" + term.toString() + "] ");
}
analyzer.close();
}
}
Running the Program
Once you are done with the creation of the source, the raw data, the data directory, the index directory and the indexes, you can proceed by compiling and running your program. To do this, keep the LuceneTester.Java file tab active and use either the Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If your application runs successfully, it will print the following message in Eclipse IDE's console −
Output
[lucen] [simpl] [yet] [power] [java] [base] [search] [librari]
Lucene - FrenchAnalyzer
FrenchAnalyzer is a specific analyzer for French language.
Class Declaration
Following is the declaration for org.apache.lucene.analysis.fr.FrenchAnalyzer class −
public final class FrenchAnalyzer extends StopwordAnalyzerBase
| S.No. | Field & Description |
|---|---|
| 1 |
static final CharArraySet DEFAULT_ARTICLES Default set of articles for ElisionFilter. |
| 2 |
static final CharArraySet DEFAULT_STOPWORD_FILE File containing default French stopwords. |
| S.No. | Constructor & Description |
|---|---|
| 1 |
FrenchAnalyzer() Builds an analyzer with the default stop words: getDefaultStopSet(). |
| 2 |
FrenchAnalyzer(CharArraySet stopwords) Builds an analyzer with the given stop words. |
| 3 |
FrenchAnalyzer(CharArraySet stopwords, CharArraySet stemExclusionSet) Builds an analyzer with the given stop words. |
| S.No. | Method & Description |
|---|---|
| 1 |
protected Analyzer.TokenStreamComponents createComponents(String fieldName) Creates a Analyzer.TokenStreamComponents which tokenizes all the text in the provided Reader. |
| 2 |
static CharArraySet getDefaultStopSet() Returns an unmodifiable instance of the default stop words set. |
| 3 |
protected TokenStream normalize(String fieldName, TokenStream in)
|
Methods Inherited
This class inherits methods from the following classes −
- org.apache.lucene.analysis.StopwordAnalyzerBase
- org.apache.lucene.analysis.Analyzer
- java.lang.Object
Usage of FrenchAnalyzer
private void displayTokenUsingFrenchAnalyzer() throws IOException {
String text = "Lucene est une bibliothèque de recherche simple mais puissante basée sur Java.";
Analyzer analyzer = new FrenchAnalyzer();
TokenStream tokenStream = analyzer.tokenStream(
LuceneConstants.CONTENTS, new StringReader(text));
CharTermAttribute term = tokenStream.addAttribute(CharTermAttribute.class);
tokenStream.reset();
while(tokenStream.incrementToken()) {
System.out.print("[" + term.toString() + "] ");
}
analyzer.close();
}
Example Application
To test search using FrenchAnalyzer, let us create a test Lucene application.
| Step | Description |
|---|---|
| 1 | Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene - First Application chapter. You can also use the project created in Lucene - First Application chapter as such for this chapter to understand the searching process. |
| 2 | Create LuceneConstants.java as explained in the Lucene - First Application chapter. Keep the rest of the files unchanged. |
| 3 | Create LuceneTester.java as mentioned below. |
| 4 | Clean and Build the application to make sure business logic is working as per the requirements. |
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
LuceneTester.java
This class is used to test the searching capability of the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.io.StringReader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.fr.FrenchAnalyzer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
public class LuceneTester {
public static void main(String[] args) {
LuceneTester tester;
tester = new LuceneTester();
try {
tester.displayTokenUsingFrenchAnalyzer();
} catch (IOException e) {
e.printStackTrace();
}
}
private void displayTokenUsingFrenchAnalyzer() throws IOException {
String text = "Lucene est une bibliothèque de recherche simple mais puissante basée sur Java.";
Analyzer analyzer = new FrenchAnalyzer();
TokenStream tokenStream = analyzer.tokenStream(
LuceneConstants.CONTENTS, new StringReader(text));
CharTermAttribute term = tokenStream.addAttribute(CharTermAttribute.class);
tokenStream.reset();
while(tokenStream.incrementToken()) {
System.out.print("[" + term.toString() + "] ");
}
analyzer.close();
}
}
Running the Program
Once you are done with the creation of the source, the raw data, the data directory, the index directory and the indexes, you can proceed by compiling and running your program. To do this, keep the LuceneTester.Java file tab active and use either the Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If your application runs successfully, it will print the following message in Eclipse IDE's console −
Output
[lucen] [est] [bibliothequ] [recherch] [simpl] [puisant] [base] [java]
Lucene - SpanishAnalyzer
SpanishAnalyzer is a specific analyzer for Spanish language.
Class Declaration
Following is the declaration for org.apache.lucene.analysis.es.SpanishAnalyzer class −
public final class SpanishAnalyzer extends StopwordAnalyzerBase
| S.No. | Field & Description |
|---|---|
| 1 |
static final String DEFAULT_STOPWORD_FILE File containing default Spanish stopwords. |
| S.No. | Constructor & Description |
|---|---|
| 1 |
SpanishAnalyzer() Builds an analyzer with the default stop words: getDefaultStopSet(). |
| 2 |
SpanishAnalyzer(CharArraySet stopwords) Builds an analyzer with the given stop words. |
| 3 |
SpanishAnalyzer(CharArraySet stopwords, CharArraySet stemExclusionSet) Builds an analyzer with the given stop words. |
| S.No. | Method & Description |
|---|---|
| 1 |
protected Analyzer.TokenStreamComponents createComponents(String fieldName) Creates a Analyzer.TokenStreamComponents which tokenizes all the text in the provided Reader. |
| 2 |
static CharArraySet getDefaultStopSet() Returns an unmodifiable instance of the default stop words set. |
| 3 |
protected TokenStream normalize(String fieldName, TokenStream in)
|
Methods Inherited
This class inherits methods from the following classes −
- org.apache.lucene.analysis.StopwordAnalyzerBase
- org.apache.lucene.analysis.Analyzer
- java.lang.Object
Usage of SpanishAnalyzer
private void displayTokenUsingSpanishAnalyzer() throws IOException {
String text = "Lucene es una biblioteca de búsqueda basada en Java sencilla pero potente.";
Analyzer analyzer = new SpanishAnalyzer();
TokenStream tokenStream = analyzer.tokenStream(
LuceneConstants.CONTENTS, new StringReader(text));
CharTermAttribute term = tokenStream.addAttribute(CharTermAttribute.class);
tokenStream.reset();
while(tokenStream.incrementToken()) {
System.out.print("[" + term.toString() + "] ");
}
analyzer.close();
}
Example Application
To test search using SpanishAnalyzer, let us create a test Lucene application.
| Step | Description |
|---|---|
| 1 | Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene - First Application chapter. You can also use the project created in Lucene - First Application chapter as such for this chapter to understand the searching process. |
| 2 | Create LuceneConstants.java as explained in the Lucene - First Application chapter. Keep the rest of the files unchanged. |
| 3 | Create LuceneTester.java as mentioned below. |
| 4 | Clean and Build the application to make sure business logic is working as per the requirements. |
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
LuceneTester.java
This class is used to test the searching capability of the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
import java.io.StringReader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.es.SpanishAnalyzer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
public class LuceneTester {
public static void main(String[] args) {
LuceneTester tester;
tester = new LuceneTester();
try {
tester.displayTokenUsingSpanishAnalyzer();
} catch (IOException e) {
e.printStackTrace();
}
}
private void displayTokenUsingSpanishAnalyzer() throws IOException {
String text = "Lucene es una biblioteca de búsqueda basada en Java sencilla pero potente.";
Analyzer analyzer = new SpanishAnalyzer();
TokenStream tokenStream = analyzer.tokenStream(
LuceneConstants.CONTENTS, new StringReader(text));
CharTermAttribute term = tokenStream.addAttribute(CharTermAttribute.class);
tokenStream.reset();
while(tokenStream.incrementToken()) {
System.out.print("[" + term.toString() + "] ");
}
analyzer.close();
}
}
Running the Program
Once you are done with the creation of the source, the raw data, the data directory, the index directory and the indexes, you can proceed by compiling and running your program. To do this, keep the LuceneTester.Java file tab active and use either the Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If your application runs successfully, it will print the following message in Eclipse IDE's console −
Output
[lucen] [bibliotec] [busqued] [basad] [java] [sencill] [potent]
