- Lucene - Home
- Lucene - Overview
- Lucene - Environment Setup
- Lucene - First Application
- Lucene - Indexing Classes
- Lucene - Searching Classes
- Lucene - Indexing Process
- Lucene - Search Operation
- Lucene - Sorting
Lucene - Indexing Operations
- Lucene - Indexing Operations
- Lucene - Add Document
- Lucene - Update Document
- Lucene - Delete Document
- Lucene - Field Options
Lucene - Query Programming
- Lucene - Query Programming
- Lucene - TermQuery
- Lucene - TermRangeQuery
- Lucene - PrefixQuery
- Lucene - BooleanQuery
- Lucene - PhraseQuery
- Lucene - WildCardQuery
- Lucene - FuzzyQuery
- Lucene - MatchAllDocsQuery
- Lucene - MatchNoDocsQuery
- Lucene - RegexpQuery
Lucene - Analysis
- Lucene - Analysis
- Lucene - WhitespaceAnalyzer
- Lucene - SimpleAnalyzer
- Lucene - StopAnalyzer
- Lucene - StandardAnalyzer
- Lucene - KeywordAnalyzer
- Lucene - CustomAnalyzer
- Lucene - EnglishAnalyzer
- Lucene - FrenchAnalyzer
- Lucene - SpanishAnalyzer
Lucene - Resources
Lucene - Delete Document Operation
Delete document is another important operation of the indexing process. This operation is used when already indexed contents are updated and indexes become invalid or indexes become very large in size, then in order to reduce the size and update the index, delete operations are carried out.
We delete Document(s) containing Field(s) to IndexWriter where IndexWriter is used to update indexes.
We will now show you a step-wise approach and make you understand how to delete a document using a basic example.
Delete a document from an index
Follow these steps to delete a document from an index −
Step 1 − Create a method to delete a Lucene document of an obsolete text file.
private void deleteDocument(File file) throws IOException {
//delete indexes for a file
writer.deleteDocument(new Term(LuceneConstants.FILE_NAME,file.getName()));
writer.commit();
}
Create an IndexWriter
IndexWriter class acts as a core component which creates/updates indexes during the indexing process.
Follow these steps to create an IndexWriter −
Step 1 − Create object of IndexWriter.
Step 2 − Create a Lucene directory which should point to a location where indexes are to be stored.
Step 3 − Initialize the IndexWriter object created with the index directory, a standard analyzer having the version information and other required/optional parameters.
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory = FSDirectory.open(Paths.get(indexDirectoryPath));
StandardAnalyzer analyzer = new StandardAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(analyzer);
writer = new IndexWriter(indexDirectory, config);
}
Delete Document and Start Reindexing Process
Following are the ways to delete the document.
deleteDocuments(Term) − Delete all the documents containing the term.
deleteDocuments(Term[]) − Delete all the documents containing any of the terms in the array.
deleteDocuments(Query) − Delete all the documents matching the query.
deleteDocuments(Query[]) − Delete all the documents matching the query in the array.
deleteAll() − Delete all the documents.
private void indexFile(File file) throws IOException {
System.out.println("Deleting index for "+file.getCanonicalPath());
deleteDocument(file);
}
Example Application
To test the indexing process, let us create a Lucene application test.
| Step | Description |
|---|---|
| 1 | Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene - First Application chapter. You can also use the project created in Lucene - First Application chapter as such for this chapter to understand the indexing process. |
| 2 | Create LuceneConstants.java,TextFileFilter.java and Indexer.java as explained in the Lucene - First Application chapter. Keep the rest of the files unchanged. |
| 3 | Create LuceneTester.java as mentioned below. |
| 4 | Clean and Build the application to make sure business logic is working as per the requirements. |
LuceneConstants.java
This class provides various constants that can be used across the sample application.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
TextFileFilter.java
This class is used as a .txt file filter.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}
Indexer.java
This class is used to index the raw data thereby, making it searchable using the Lucene library.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
import java.io.IOException;
import java.nio.file.Paths;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
public class Indexer {
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory = FSDirectory.open(Paths.get(indexDirectoryPath));
StandardAnalyzer analyzer = new StandardAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(analyzer);
writer = new IndexWriter(indexDirectory, config);
}
public void close() throws CorruptIndexException, IOException {
writer.close();
}
private void deleteDocument(File file) throws IOException {
//delete indexes for a file
writer.deleteDocuments(
new Term(LuceneConstants.FILE_NAME,file.getName()));
writer.commit();
}
private void indexFile(File file) throws IOException {
System.out.println("Deleting index: "+file.getCanonicalPath());
deleteDocument(file);
}
public int createIndex(String dataDirPath, FileFilter filter)
throws IOException {
//get all files in the data directory
File[] files = new File(dataDirPath).listFiles();
for (File file : files) {
if(!file.isDirectory()
&& !file.isHidden()
&& file.exists()
&& file.canRead()
&& filter.accept(file)
){
indexFile(file);
}
}
return writer.getDocStats().numDocs;
}
}
LuceneTester.java
This class is used to test the indexing capability of the Lucene library.
package com.tutorialspoint.lucene;
import java.io.IOException;
public class LuceneTester {
String indexDir = "D:\\Lucene\\Index";
String dataDir = "D:\\Lucene\\Data";
Indexer indexer;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.createIndex();
} catch (IOException e) {
e.printStackTrace();
}
}
private void createIndex() throws IOException {
indexer = new Indexer(indexDir);
int numIndexed;
long startTime = System.currentTimeMillis();
numIndexed = indexer.createIndex(dataDir, new TextFileFilter());
long endTime = System.currentTimeMillis();
indexer.close();
}
}
Data & Index Directory Creation
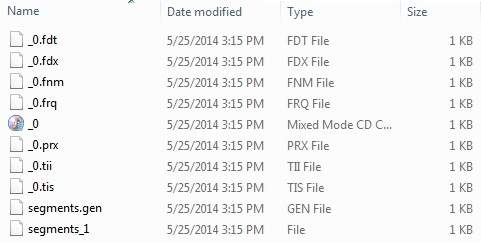
Weve used 10 text files from record1.txt to record10.txt containing names and other details of the students and put them in the directory D:\Lucene\Data. Test Data. An index directory path should be created as D:\Lucene\Index. After running this program, you can see the list of index files created in that folder.
Running the Program
Once you are done with the creation of the source, the raw data, the data directory and the index directory, you can compile and run your program. To do this, keep the LuceneTester.Java file tab active and use either the Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If your application runs successfully, it will print the following message in Eclipse IDE's console −
Output
Deleting index: D:\lucene\Data\record1.txt Deleting index: D:\lucene\Data\record10.txt Deleting index: D:\lucene\Data\record2.txt Deleting index: D:\lucene\Data\record3.txt Deleting index: D:\lucene\Data\record4.txt Deleting index: D:\lucene\Data\record5.txt Deleting index: D:\lucene\Data\record6.txt Deleting index: D:\lucene\Data\record7.txt Deleting index: D:\lucene\Data\record8.txt Deleting index: D:\lucene\Data\record9.txt 11 File indexed, time taken: 325 ms
Once you've run the program successfully, you will have following content in your index directory −