- Lucene - Home
- Lucene - Overview
- Lucene - Environment Setup
- Lucene - First Application
- Lucene - Indexing Classes
- Lucene - Searching Classes
- Lucene - Indexing Process
- Lucene - Search Operation
- Lucene - Sorting
Lucene - Indexing Operations
- Lucene - Indexing Operations
- Lucene - Add Document
- Lucene - Update Document
- Lucene - Delete Document
- Lucene - Field Options
Lucene - Query Programming
- Lucene - Query Programming
- Lucene - TermQuery
- Lucene - TermRangeQuery
- Lucene - PrefixQuery
- Lucene - BooleanQuery
- Lucene - PhraseQuery
- Lucene - WildCardQuery
- Lucene - FuzzyQuery
- Lucene - MatchAllDocsQuery
- Lucene - MatchNoDocsQuery
- Lucene - RegexpQuery
Lucene - Analysis
- Lucene - Analysis
- Lucene - WhitespaceAnalyzer
- Lucene - SimpleAnalyzer
- Lucene - StopAnalyzer
- Lucene - StandardAnalyzer
- Lucene - KeywordAnalyzer
- Lucene - CustomAnalyzer
- Lucene - EnglishAnalyzer
- Lucene - FrenchAnalyzer
- Lucene - SpanishAnalyzer
Lucene - Resources
Lucene - Indexing Classes
Indexing process is one of the core functionalities provided by Lucene. The following diagram illustrates the indexing process and the use of classes. IndexWriter is the most important and the core component of the indexing process.
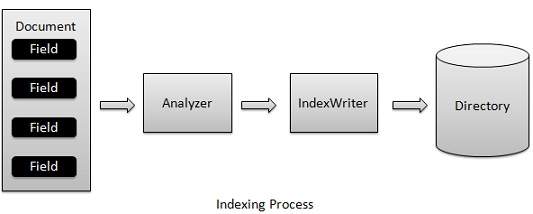
We add Document(s) containing Field(s) to IndexWriter which analyzes the Document(s) using the Analyzer and then creates/open/edit indexes as required and store/update them in a Directory. IndexWriter is used to update or create indexes. It is not used to read indexes.
Indexing Classes
Following is a list of commonly-used classes during the indexing process.
| S.No. | Class & Description |
|---|---|
| 1 |
IndexWriter
This class acts as a core component which creates/updates indexes during the indexing process. |
| 2 |
Directory
This class represents the storage location of the indexes. |
| 3 |
Analyzer
This class is responsible to analyze a document and get the tokens/words from the text which is to be indexed. Without analysis done, IndexWriter cannot create index. |
| 4 |
Document
This class represents a virtual document with Fields where the Field is an object which can contain the physical document's contents, its meta data and so on. The Analyzer can understand a Document only. |
| 5 |
Field
This is the lowest unit or the starting point of the indexing process. It represents the key value pair relationship where a key is used to identify the value to be indexed. Let us assume a field used to represent contents of a document will have key as "contents" and the value may contain the part or all of the text or numeric content of the document. Lucene can index only text or numeric content only. |
| 6 |
TokenStream
TokenStream is an output of the analysis process and it comprises of a series of tokens. It is an abstract class. |
