- Java Microservices Tutorial
- Java Microservices - Home
- Microservices - Introduction
- Microservices vs Monolith vs SOA
- Java Microservices - Environment Setup
- Java Microservices - Advantages of Spring Boot
- Java Microservices - Design Patterns
- Java Microservices - Domain Driven Design
- Java Microservices - Decomposition by Business Capability
- Java Microservices - Decomposition by Subdomain
- Java Microservices - Backend for Frontend
- Java Microservices - The Strangler Pattern
- Java Microservices - Synchronous Communication
- Java Microservices - Asynchronous Communication
- Java Microservices - Saga Pattern
- Java Microservices - Centralized Logging (ELK Stack)
- Java Microservices - Event Sourcing
- Java Microservices - CQRS Pattern
- Java Microservices - Sidecar Pattern
- Java Microservices - Service Mesh Pattern
- Java Microservices - Circuit Breaker Pattern
- Java Microservices - Distributed Tracing
- Java Microservices - Control Loop Pattern
- Java Microservices - Database Per Service
- Java Microservices - Bulkhead Pattern
- Java Microservices - Health Check API
- Java Microservices - Retry Pattern
- Java Microservices - Fallback Pattern
- Java Microservices Useful Resources
- Java Microservices Quick Guide
- Java Microservices Useful Resources
- Java Microservices Discussion
Java Microservices - Quick Guide
Microservices - Introduction
In today's fast-paced digital world, businesses demand agility, scalability, and resilience from their software applications. Traditional monolithic architectures, where all components are tightly integrated, often struggle to meet these demands. Enter Microservices - a revolutionary architectural approach that structures applications as a collection of small, independent services, each responsible for a specific business function. This article explores what microservices are, their key characteristics, benefits, challenges, and real-world applications.
What are Microservices?
Microservices, or microservice architecture, is a software design pattern where an application is broken down into multiple loosely coupled, independently deployable services. Each service −
Focuses on a single business capability (e.g., user authentication, payment processing, order management).
Runs in its own process and communicates via APIs (typically REST, gRPC, or message brokers like Kafka).
Can use different programming languages and databases, allowing teams to choose the best tech stack for each service.
Unlike monolithic applications, where a single failure can crash the entire system, microservices isolate faults, ensuring that one service's failure doesn't disrupt others.
Example: Monolithic/Traditional Application Architecture
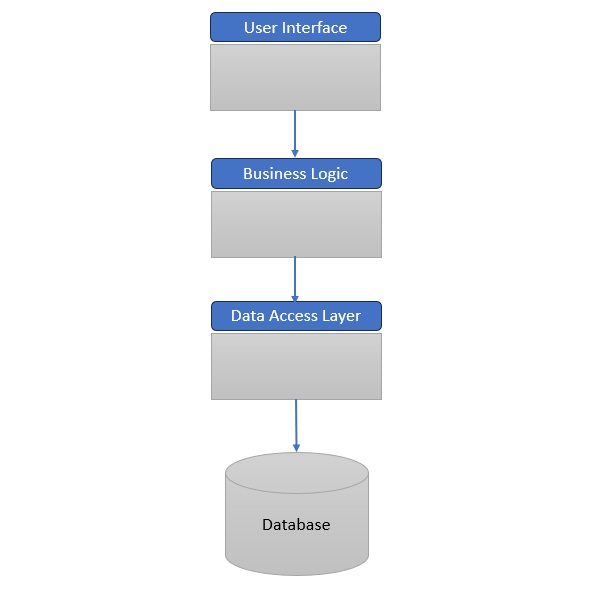
Example: Microservices Architecture
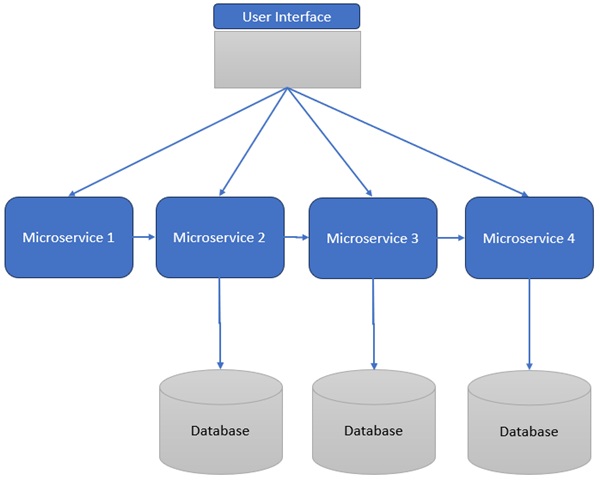
Benefits of Microservices
Faster Development & Deployment
Teams can work in parallel on different services, accelerating release cycles.
Improved Fault Isolation
A crash in one service (e.g., recommendation engine) doesn't bring down the entire app.
Technology Flexibility
Developers can use Python for machine learning services while using Go for high-performance APIs.
Easier Maintenance
Updating a single service is simpler than redeploying a monolithic app.
Better Scalability
Only high-demand services (e.g., checkout) need scaling, optimizing resource usage.
Challenges of Microservices
Increased Complexity
Managing multiple services, databases, and inter-service communication requires robust DevOps practices.
Testing & Debugging Difficulties
End-to-end testing is harder due to distributed dependencies.
Higher Operational Overhead
Requires advanced monitoring (e.g., Prometheus, Grafana) and orchestration tools (e.g., Kubernetes).
Real-World Applications
E-Commerce (Shopee, Amazon) −
Shopee uses microservices for payments, inventory, and delivery, allowing seamless scaling during sales events.
Amazon's transition from a monolith to microservices enabled faster feature rollouts (e.g., AWS, Prime Video).
Streaming Services (Spotify) −
Spotify's microservices handle playlists, recommendations, and podcasts independently, improving performance.
IoT & Smart Devices −
Microservices manage sensor data, analytics, and device control in IoT ecosystems (e.g., smart homes, connected cars).
FinTech (Banking & Payments) −
Banks use microservices for fraud detection, transactions, and customer profiles, ensuring high availability.
When to Use Microservices?
Microservices are ideal for −
Large, complex applications (e.g., enterprise SaaS, global e-commerce).
Teams needing agility (e.g., startups scaling rapidly).
Systems requiring high availability (e.g., financial services, IoT).
However, monoliths may still be better for small projects with limited scalability needs.
Conclusion
Microservices have become the "home" of modern software architecture, offering unparalleled flexibility, scalability, and resilience. While they introduce complexity, their benefits−faster development, fault isolation, and tech diversity−make them indispensable for businesses aiming to thrive in a digital-first world. Whether you're building the next Spotify or a smart home IoT system, microservices provide the foundation for innovation.
Microservices vs Monolith vs SOA
Introduction to Microservices
Microservices, also known as Microservice Architecture (MSA), is a software development approach where applications are structured as a collection of small, independent, and loosely coupled services. Each service is designed to perform a specific business function and communicates with other services via well-defined APIs.
Why Microservices?
Traditional monolithic applications bundle all functionalities into a single codebase, making them difficult to scale, maintain, and update.
Microservices break down applications into modular components, enabling faster development, independent scaling, and improved fault isolation.
Core Principles
Single Responsibility Principle (SRP) − Each service should handle one business capability (e.g., authentication, payment processing).
Decentralized Data Management − Services can use different databases (SQL, NoSQL) based on their needs.
Independent Deployment − Teams can update and deploy services without affecting others.
Evolution from Monolithic to Microservices Architecture
Monolithic Architecture
Single-tiered application where UI, business logic, and database are tightly integrated.
Pros − Simple to develop, test, and deploy initially.
Cons −
Difficult to scale (must scale the entire app).
Long deployment cycles (small changes require full redeployment).
High risk of system-wide failures.
Service-Oriented Architecture (SOA)
An intermediate step between monoliths and microservices.
Uses Enterprise Service Bus (ESB) for communication, leading to tight coupling and bottlenecks.
Microservices Architecture
Eliminates central orchestration (no ESB).
Lightweight protocols (REST, gRPC, Kafka) replace heavy middleware.
Each service is autonomous, improving agility and scalability.
Key Characteristics of Microservices
Modularity − Services are small and focused on a single function.
Decentralized Control − Teams can choose different tech stacks (e.g., Python for ML, Java for backend).
Resilience − Failures in one service don't crash the entire system.
Automated DevOps − CI/CD pipelines enable rapid deployments.
API-First Approach − Services communicate via APIs (REST, GraphQL).
Cloud-Native − Designed for containerization (Docker) and orchestration (Kubernetes).
Microservices vs. Monolithic vs. SOA
| Sr.No. | Aspect | Monolith | SOA | Microservices |
|---|---|---|---|---|
| 1 | Coupling | Tightly coupled | Loosely coupled (via ESB) | Loosely coupled (direct APIs) |
| 2 | Scalability | Scales as a whole | Partial scaling | Per-service scaling |
| 3 | Deployment | Full redeploy needed | Complex due to ESB | Independent deployments |
| 4 | Tech Stack | Limited to one language | Mixed, but constrained | Fully polyglot |
Real-World Use Cases
🛒 E-Commerce (Amazon, Shopee)
Amazon migrated from a monolith to microservices to handle **Prime Day traffic surges**.
Shopee uses microservices for **real-time inventory updates**.
🎵 Streaming (Netflix, Spotify)
Netflix's recommendation engine runs as an independent microservice.
Spotify uses microservices for personalized playlists.
🏦 FinTech (PayPal, Revolut)
PayPal processes millions of transactions daily using microservices.
Revolut's fraud detection runs as a separate service.
Best Practices for Implementing Microservices
Start Small, Then Scale
Begin with one or two services before full adoption.
Use Containers & Orchestration
Docker for containerization, Kubernetes for orchestration.
Implement API Gateways
Kong, Apigee, or AWS API Gateway manage routing, load balancing, and security.
Adopt DevOps & CI/CD
GitLab CI, Jenkins, GitHub Actins automate testing and deployment.
Monitor & Log Everything
Prometheus (metrics), ELK Stack (logs), Grafana (dashboards).
Conclusion
Microservices represent a paradigm shift in software architecture, offering scalability, flexibility, and resilience that monolithic systems cannot match. While they introduce complexity, the benefits−faster deployments, independent scaling, and fault tolerance−make them indispensable for modern cloud-native applications.
Java Microservices - Environment Setup
This chapter will guide you on how to prepare a development environment to start your work with Java Based Microservices. It will also teach you how to set up JDK, Maven and STS on your machine before you set up Spring Boot Framework for Microservices −
Step 1 - Setup Java Development Kit (JDK)
You can download the latest version of SDK from Oracle's Java site − Java SE Downloads. You will find instructions for installing JDK in downloaded files, follow the given instructions to install and configure the setup. Finally set PATH and JAVA_HOME environment variables to refer to the directory that contains java and javac, typically java_install_dir/bin and java_install_dir respectively.
If you are running Windows and have installed the JDK in C:\Program Files\Java\jdk-21, you would have to put the following line in your C:\autoexec.bat file.
set PATH=C:\Program Files\Java\jdk-21;%PATH% set JAVA_HOME=C:\Program Files\Java\jdk-21
Alternatively, on Windows NT/2000/XP, you will have to right-click on My Computer, select Properties → Advanced → Environment Variables. Then, you will have to update the PATH value and click the OK button.
On Unix (Solaris, Linux, etc.), if the SDK is installed in /usr/local/jdk-21 and you use the C shell, you will have to put the following into your .cshrc file.
setenv PATH /usr/local/jdk-21/bin:$PATH setenv JAVA_HOME /usr/local/jdk-21
Alternatively, if you use an Integrated Development Environment (IDE) like Borland JBuilder, Eclipse, IntelliJ IDEA, or Sun ONE Studio, you will have to compile and run a simple program to confirm that the IDE knows where you have installed Java. Otherwise, you will have to carry out a proper setup as given in the document of the IDE.
Step 2 - Setup Spring Tool Suite
All the examples in this tutorial have been written using Spring Tool Suite. So we would suggest you should have the latest version of Spring Tool Suite installed on your machine.
To install Spring Tools IDE, download the latest Spring Tools binaries from https://spring.io/tools. Once you download the installation, unpack the binary distribution into a convenient location. For example, in C:\sts on Windows, or /usr/local/sts on Linux/Unix and finally set PATH variable appropriately.
String Tool Suite can be started by executing the following commands on Windows machine, or you can simply double-click on eclipse.exe
%C:\sts\SpringToolSuite4.exe
SpringToolSuite4 can be started by executing the following commands on Unix (Solaris, Linux, etc.) machine −
$/usr/local/sts/SpringToolSuite4
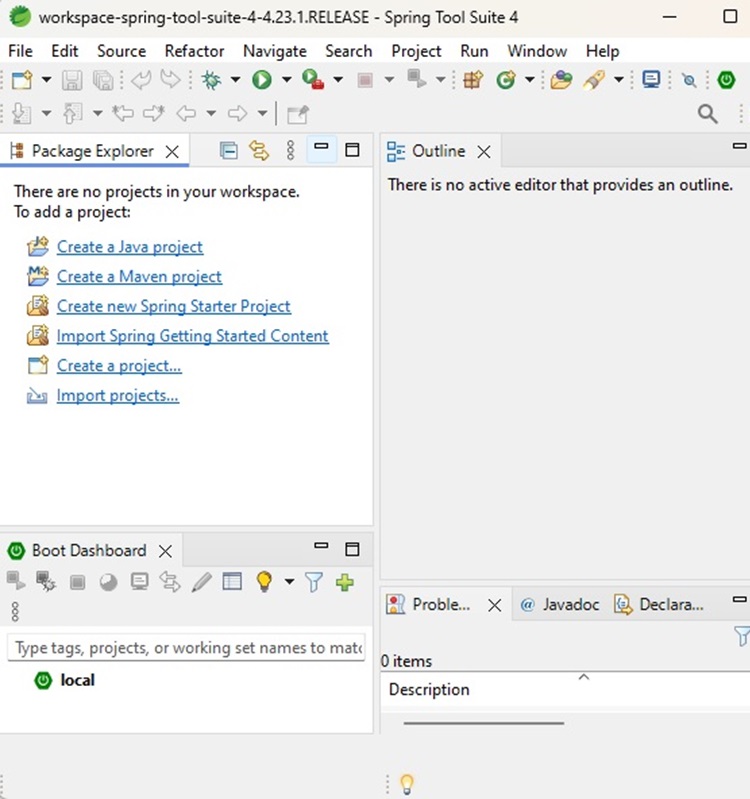
After a successful startup, if everything is fine then it should display the following result −
Step 3 - Download Maven Archive
Download Maven 3.9.8 from https://maven.apache.org/download.cgi.
| OS | Archive name |
|---|---|
| Windows | apache-maven-3.9.8-bin.zip |
| Linux | apache-maven-3.9.8-bin.tar.gz |
| Mac | apache-maven-3.9.8-bin.tar.gz |
Step 4 - Extract the Maven Archive
Extract the archive, to the directory you wish to install Maven 3.9.8. The subdirectory apache-maven-3.9.8 will be created from the archive.
| OS | Location (can be different based on your installation) |
|---|---|
| Windows | C:\Program Files\Apache\apache-maven-3.9.8 |
| Linux | /usr/local/apache-maven |
| Mac | /usr/local/apache-maven |
Step 5 - Set Maven Environment Variables
Add M2_HOME, M2, MAVEN_OPTS to environment variables.
| OS | Output |
|---|---|
| Windows |
Set the environment variables using system properties. M2_HOME=C:\Program Files\Apache\apache-maven-3.9.8 M2=%M2_HOME%\bin MAVEN_OPTS=-Xms256m -Xmx512m |
| Linux |
Open command terminal and set environment variables. export M2_HOME=/usr/local/apache-maven/apache-maven-3.9.8 export M2=$M2_HOME/bin export MAVEN_OPTS=-Xms256m -Xmx512m |
| Mac |
Open command terminal and set environment variables. export M2_HOME=/usr/local/apache-maven/apache-maven-3.9.8 export M2=$M2_HOME/bin export MAVEN_OPTS=-Xms256m -Xmx512m |
Step 6 - Add Maven bin Directory Location to System Path
Now append M2 variable to System Path.
| OS | Output |
|---|---|
| Windows | Append the string ;%M2% to the end of the system variable, Path. |
| Linux | export PATH=$M2:$PATH |
| Mac | export PATH=$M2:$PATH |
Step 7 - Verify Maven Installation
Now open console and execute the following mvn command.
| OS | Task | Command |
|---|---|---|
| Windows | Open Command Console | c:\> mvn --version |
| Linux | Open Command Terminal | $ mvn --version |
| Mac | Open Terminal | machine:~ joseph$ mvn --version |
Finally, verify the output of the above commands, which should be as follows −
| OS | Output |
|---|---|
| Windows |
Apache Maven 3.9.8 (36645f6c9b5079805ea5009217e36f2cffd34256) Maven home: C:\Program Files\Apache\apache-maven-3.9.8 Java version: 21.0.2, vendor: Oracle Corporation, runtime: C:\Program Files\Java\jdk-21 Default locale: en_IN, platform encoding: UTF-8 OS name: "windows 11", version: "10.0", arch: "amd64", family: "windows" |
| Linux |
Apache Maven 3.9.8 (36645f6c9b5079805ea5009217e36f2cffd34256) Java version: 21.0.2 Java home: /usr/local/java-current/jre |
| Mac |
Apache Maven 3.9.8 (36645f6c9b5079805ea5009217e36f2cffd34256) Java version: 21.0.2 Java home: /Library/Java/Home/jre |
Step 8 - Setup Postman
Postman can be installed in operating systems like Mac, Windows and Linux. It is basically an independent application which can be installed in the following ways −
Postman can be installed from the Chrome Extension (will be available only in Chrome browser).
It can be installed as a standalone application.
To download Postman as a standalone application in Windows, navigate to the following link https://www.postman.com/downloads/
For installation steps, you can visit our Postman Tutorial Page Postman - Environment Setup.
Java Microservices - Advantages of Using Spring Boot
In the fast-paced world of software development, Microservices Architecture has emerged as a powerful alternative to monolithic applications. It promotes the idea of developing single-purpose, loosely coupled services that can be deployed independently. Spring Boot, a project from the Spring ecosystem, is one of the most popular frameworks used to build microservices due to its simplicity, speed, and strong community support.
This chapter explores the key advantages of using Spring Boot to develop microservices, including its features, architecture support, tooling, and real-world applicability.
What is Spring Boot?
Spring Boot is an extension of the Spring framework that simplifies the setup and development of Spring-based applications. It minimizes boilerplate code, automates configuration, and promotes convention over configuration.
Spring Boot makes it easy to create stand-alone, production-grade Spring-based applications. - Spring IO
Key Features
Auto-configuration
Embedded servers (Tomcat, Jetty, Undertow)
Production-ready metrics and health checks
Minimal XML configuration
Spring Initializr and CLI tools
How Spring Boot Supports Microservices
Spring Boot, along with Spring Cloud, offers built-in support to develop resilient, scalable, and cloud-ready microservices.
Microservices Architecture using Spring Boot
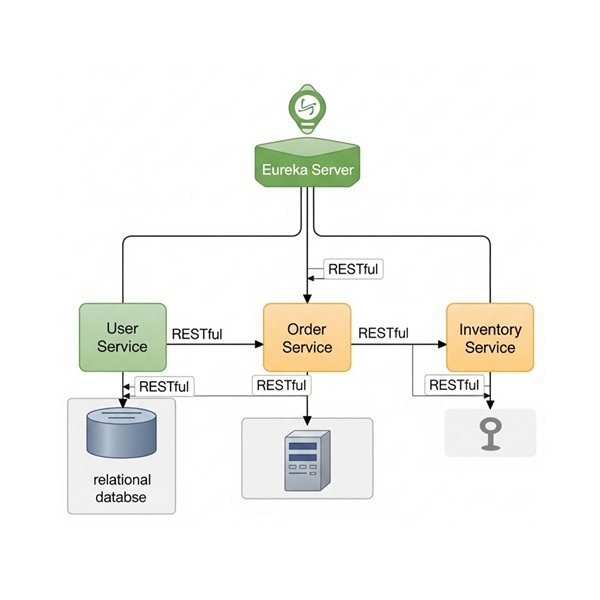
Advantages of Using Spring Boot in Microservices
Simplified Development
Spring Boot provides −
Pre-built templates and project structures (via Spring Initializr).
Auto-configuration based on classpath contents.
Minimal setup to get REST APIs running.
Example
With just a few annotations (@RestController, @SpringBootApplication), a microservice is ready.
@SpringBootApplication
public class InventoryServiceApplication {
public static void main(String[] args) {
SpringApplication.run(InventoryServiceApplication.class, args);
}
}
Embedded Web Servers
Spring Boot embeds web servers like Tomcat or Jetty, eliminating the need for external server deployment. This makes each microservice −
Self-contained
Easier to deploy in Docker containers or cloud environments
Seamless Integration with Spring Cloud
Spring Cloud provides extensions to Spring Boot that facilitate −
Service discovery (Eureka)
API gateway (Spring Cloud Gateway)
Load balancing (Cloud Loadbalancer)
Circuit breakers (Resilience4j)
Config server (Spring Config Server)
All these integrations are minimal-code and declarative.
Rapid Bootstrapping with Spring Initializr
https://start.spring.io provides a UI and API to generate Spring Boot microservices with −Preselected dependencies (e.g., Web, JPA, Actuator)
Maven or Gradle configuration
Java/Kotlin/Groovy language support
This accelerates development and ensures consistency.
Built-in Monitoring with Spring Boot Actuator
Spring Boot Actuator offers endpoints like −
/health
/metrics
/info
These endpoints integrate well with Prometheus, Grafana, or ELK stack, providing real-time monitoring and health checks for microservices.
Easy Testing and Mocking
Spring Boot provides test annotations −
@SpringBootTest
@WebMvcTest
@DataJpaTest
It also supports −
MockMVC for REST controllers
Testcontainers for Docker-based integration tests
Docker & Cloud-Native Friendly
Spring Boot jars are −
Self-contained − Easily deployable in Docker.
Portable − Can be moved to Kubernetes clusters, AWS ECS, Azure Containers, etc.
Dockerfile Example −
FROM openjdk:17 ADD target/inventory-service.jar app.jar ENTRYPOINT ["java", "-jar", "/app.jar"]
Spring Boot and DevOps Pipelines
Spring Boot integrates well with CI/CD tools −
Jenkins
GitHub Actions
GitLab CI/CD
Automated testing, packaging, and deployment are straightforward.
Case Study - E-Commerce Microservices
Services −
Product Service
Order Service
Payment Service
Notification Service
Using Spring Boot −
Each service uses REST or messaging (RabbitMQ/Kafka)
Configuration is centralized via Spring Cloud Config
Eureka handles service discovery
Gateway provides a unified API interface
Java Microservices - Domain Driven Design
Introduction to Domain-Driven Design (DDD)
Domain-Driven Design (DDD), introduced by Eric Evans in his 2003 book, is a software design approach that focuses on modelling business domains and aligning software architecture with business needs.
In microservices, DDD helps −
Break down complex business domains into smaller, manageable services.
Define clear boundaries between services (Bounded Contexts).
Improve collaboration between developers and domain experts.
Why Use DDD in Microservices?
Microservices require loose coupling and high cohesion, which DDD facilitates by −
Preventing Anaemic Domain Models (services with no business logic).
Avoiding Big Ball of Mud (monolithic-like interdependencies).
Improving Scalability by isolating domain logic.
Enabling Autonomous Teams (each team owns a domain).
Example - E-Commerce System
Without DDD
A single "OrderService" handling payments, inventory, and shipping → tight coupling.
With DDD
Separate Order Service, Payment Service, Inventory Service → clear domain boundaries.
Core Concepts of Domain-Driven Design
Bounded Context
A well-defined boundary where a domain model applies.
Each microservice should align with one Bounded Context.
Example
Order Context − Manages order creation, status.
Shipping Context − Handles logistics, tracking.
Ubiquitous Language
A shared vocabulary between developers and business experts.
Avoids miscommunication (e.g., "customer" vs. "user").
Domain Models
| Sr.No. | Concept | Description | Example |
|---|---|---|---|
| 1 | Entity | Unique identity (e.g., 'Order' with 'orderId'). | Customer(id, name, email) |
| 2 | Value Object | No identity, immutable (e.g., 'Address'). | Money(amount, currency) |
| 3 | Aggregate | A cluster of related objects (e.g., 'Order' + 'OrderItems') | Order (root) → OrderLineItems |
Implementing DDD in Microservices
Service Decomposition by Domain
Each microservice = one Bounded Context.
Example −
User Service (handles authentication, profiles).
Order Service (order lifecycle).
Inventory Service (stock management).
Event Storming
A workshop technique to identify domain events.
Example −
'OrderPlaced' → 'PaymentProcessed' → 'InventoryUpdated'.
CQRS (Command Query Responsibility Segregation)
Separates reads (Queries) and writes (Commands).
Example −
Command Side − 'CreateOrder()' (writes to DB).
Query Side − 'GetOrderHistory()' (reads from a read-optimized DB).
Event Sourcing
Stores state changes as events (not just current state).
Example −
Instead of updating 'OrderStatus', log − '1. OrderCreated → 2. OrderPaid → 3. OrderShipped'.
Challenges & Best Practices
Challenges
Complexity − DDD requires deep domain understanding.
Over-Engineering − Not all systems need DDD.
Eventual Consistency − Microservices may have delayed sync.
Best Practices
Start Small − Apply DDD only to complex domains.
Use Domain Events − For inter-service communication.
Leverage Tools − Axon Framework, Spring Modulith.
Case Study: DDD in a Real-World Microservices System
Company − A large e-commerce platform.
Problem − Monolith struggling with scaling orders and inventory.
Solution
Identified "Bounded Contexts" (Orders, Payments, Inventory).
Applied "Event Storming" to define workflows.
Used CQRS for fast order history queries.
Result
40% faster order processing.
Better team autonomy.
Conclusion
Domain-Driven Design is powerful but not a silver bullet. When applied correctly in microservices it −
Improves maintainability.
Aligns tech with business needs.
Reduces coupling between services.
Java Microservices - Decomposition by Business Capability
Introduction
Microservices architecture enables the development of complex systems as a suite of independently deployable, modular services. One of the most critical aspects of microservices design is how to decompose a large application into smaller, manageable services. This article focuses on a key decomposition strategy: Decomposition by Business Capability.
This pattern emphasizes splitting services based on business domains rather than technical layers, promoting better alignment with organizational structures, product thinking, and scalability.
What Is Decomposition in Microservices?
In a microservices system, decomposition refers to the act of breaking down a monolithic application into independently deployable units (microservices). Each unit should have −
A well-defined boundary
Autonomy over its data and logic
A clear business purpose
Poor decomposition can lead to tightly coupled services, redundancy, and operational inefficiencies.
Understanding Business Capability
A business capability is something that the business does or needs to do to achieve its objectives. It is −
Stable over time
Independent from organizational changes
Often modeled using Domain-Driven Design (DDD)
Examples of Business Capabilities
| Sr.No. | Business Domain | Business Capabilities |
|---|---|---|
| 1 | E-commerce | Order Management, Payments, Customer Service |
| 2 | Banking | Account Management, Loans, Risk Analysis |
| 3 | Healthcare | Patient Records, Appointments, Billing |
Pattern − Decomposition by Business Capability
Definition
Decomposition by business capability is a microservices design pattern that organizes services around what the business does, not how the software is technically layered.
Core Principle
Each microservice corresponds to a single business capability, becoming the owner of all data and logic related to that capability.
Benefits of Decomposition by Business Capability
| Sr.No. | Benefit | Description |
|---|---|---|
| 1 | High cohesion | Services are focused and internally consistent. |
| 2 | Loose coupling | Independent deployment and scalability. |
| 3 | Clear ownership | Easier to assign to teams (Team-Service alignment). |
| 4 | Faster development | Services evolve independently without breaking other components. |
| 5 | Better DDD alignment | Ties naturally with DDD's Bounded Contexts. |
Applying the Pattern: A Case Study
Scenario: Building an Online Retail Platform
Monolith Capabilities
User management
Product catalog
Order management
Payment processing
Decomposed Microservices
| Sr.No. | Microservice | Business Capability |
|---|---|---|
| 1 | user-service | User registration, profiles |
| 2 | product-service | Product listings, categories |
| 3 | order-service | Cart, checkout, orders |
| 4 | payment-service | Payment processing |
Step-by-Step Implementation (Spring Boot)
We'll use Spring Boot to demonstrate decomposition by business capability.
Create Individual Services.
user-service – User Capability
UserController.java
@RestController
@RequestMapping("/users")
public class UserController {
@GetMapping("/{id}")
public String getUser(@PathVariable String id) {
return "User profile for ID: " + id;
}
}
product-service – Product Capability
ProductController.java
@RestController
@RequestMapping("/products")
public class ProductController {
@GetMapping("/{id}")
public String getProduct(@PathVariable String id) {
return "Product details for ID: " + id;
}
}
order-service – Order Capability
OrderController.java
@RestController
@RequestMapping("/orders")
public class OrderController {
@PostMapping("/")
public String placeOrder(@RequestBody String orderData) {
return "Order placed successfully";
}
}
payment-service – Payment Capability
PaymentController.java
@RestController
@RequestMapping("/payments")
public class PaymentController {
@PostMapping("/")
public String makePayment(@RequestBody String paymentData) {
return "Payment successful";
}
}
Each service is an isolated Spring Boot application, deployed independently, with its own database.
Communication Between Business Capabilities
Inter-service communication is done via REST or asynchronous messaging.
REST Example from Order to Payment
@Autowired
private RestTemplate restTemplate;
public String callPaymentService() {
return restTemplate.postForObject("http://payment-service/payments", new Payment(), String.class);
}
Integration with Domain-Driven Design (DDD)
Decomposition by business capability is closely aligned with DDD's Bounded Context.
Bounded Context Example
ProductContext → product-service
CustomerContext → user-service
OrderContext → order-service
Each service is a self-contained model and is responsible for its own aggregates, entities, and repositories.
Database Design per Capability
Each microservice manages its own database. This ensures −
Loose coupling
Independent schema evolution
Avoidance of shared database anti-pattern
Example
| Sr.No. | Service | Table |
|---|---|---|
| 1 | user-service | Users |
| 2 | product-service | products, categories |
| 3 | order-service | orders, order_items |
Challenges in This Pattern
| Sr.No. | Challenge | Description |
|---|---|---|
| 1 | Data consistency | No distributed transactions; must use eventual consistency |
| 2 | Cross-cutting concerns | Logging, auth, monitoring must be centralized |
| 3 | Service granularity confusion | Too fine-grained = overhead; too coarse = mini-monolith |
| 4 | Initial complexity | More moving parts to manage compared to monolith |
Real-World Examples
| Sr.No. | Company | Business Capability-based Microservices |
|---|---|---|
| 1 | Amazon | Order, Inventory, Delivery, Payment |
| 2 | Netflix | Playback, Recommendations, Membership |
| 3 | Uber | Ride Booking, Payments, Driver Management |
These companies structure services around business functions, not technical tiers.
Conclusion
Decomposition by Business Capability is one of the most effective strategies for structuring microservices. It helps design systems that are −
Modular and scalable
Aligned with business goals
Easy to manage and evolve
This pattern provides a strong foundation for team autonomy, agile development, and cloud-native deployment.
Java Microservices - Decomposition by Subdomain
Introduction
Modern software systems must evolve quickly, scale independently, and remain robust in the face of change. Microservices architecture provides a foundation for these requirements by breaking down applications into independent services.
However, how we decompose a system is critical. A poor decomposition can lead to tight coupling, poor scalability, and development friction. Among the various decomposition strategies, "Decomposition by Subdomain" − driven by Domain-Driven Design (DDD) − stands out as one of the most effective and sustainable methods.
This article explores the Decomposition by Subdomain pattern in microservices, its rationale, implementation approach, and real-world applications using Spring Boot.
What is Decomposition by Subdomain?
Definition
Decomposition by subdomain is a microservices design pattern that breaks a system into services based on domain substructures called subdomains, identified through Domain-Driven Design (DDD).
Instead of organizing services by technical functions (like DAO, controllers), we organize them by business function areas such as−
Customer Management
Billing
Inventory
Shipping
Each subdomain becomes a bounded context, which maps directly to a microservice.
Benefits of Decomposition by Subdomain
| Sr.No. | Benefit | Explanation |
|---|---|---|
| 1 | High Cohesion | Services handle a specific, focused domain task |
| 2 | Loosely Coupled Services | Minimizes dependencies between services |
| 3 | Aligned to Business Goals | Improves communication between technical and business teams |
| 4 | Supports Team Autonomy | Teams can own and evolve services independently |
| 5 | Easier Maintenance | Smaller, focused services are easier to debug and test |
Identifying Subdomains: A Case Study
Let's consider an online learning platform like Coursera.
Business Capabilities
User Registration
Course Catalog
Enrollment & Payment
Content Delivery
Certification
Decomposed Subdomains
| Sr.No. | Subdomain | Microservice |
|---|---|---|
| 1 | Identity & Access | auth-service |
| 2 | Course Management | course-service |
| 3 | Payment & Enrollment | enrollment-service |
| 4 | Video Streaming | streaming-service |
| 5 | Certificate Issuance | certification-service |
Implementing the Pattern Using Spring Boot
We'll illustrate with two subdomains: Course Management and Enrollment.
Course-Service (Core Subdomain)
Responsibilities
Manage course creation, categories, metadata.
CourseController.java
@RestController
@RequestMapping("/courses")
public class CourseController {
@GetMapping("/{id}")
public String getCourse(@PathVariable String id) {
return "Course info for ID: " + id;
}
@PostMapping("/")
public String createCourse(@RequestBody Course course) {
return "Course created: " + course.getTitle();
}
}
application.yml
spring:
application:
name: course-service
server:
port: 8081
Enrollment-Service (Core Subdomain)
Responsibilities
Manage student enrollment and payment status.
EnrollmentController.java
@RestController
@RequestMapping("/enrollments")
public class EnrollmentController {
@PostMapping("/")
public String enroll(@RequestBody Enrollment enrollment) {
return "Student enrolled in course ID: " + enrollment.getCourseId();
}
}
application.yml
spring:
application:
name: enrollment-service
server:
port: 8082
Manage student enrollment and payment status.
Each service has −
Its own data model
Database
And communicates via REST or asynchronous events.
Communicating Across Subdomains
Subdomain-based services often need to interact.
REST Call (Synchronous)
enrollment-service calls course-service to validate a course −
@Autowired
private RestTemplate restTemplate;
public String getCourse(String id) {
return restTemplate.getForObject("http://course-service/courses/" + id, String.class);
}
Event-Driven (Asynchronous)
Using Kafka or RabbitMQ for loose coupling −
course-service emits CourseCreatedEvent.
enrollment-service listens and updates its cache.
Aligning Subdomains with Bounded Contexts
Subdomain decomposition often aligns with bounded contexts in DDD.
Bounded Context − A logical boundary where a particular domain model is defined and applicable.
This allows −
Unique data models
Different vocabularies
Clear API boundaries
Example
course-service uses CourseEntity
enrollment-service uses CourseView (DTO)
This prevents leaky abstractions and supports data autonomy.
Subdomain Database Design
Each service/subdomain must own its data.
Microservice DB Ownership
| Sr.No. | Service | Tables |
|---|---|---|
| 1 | course-service | courses, categories |
| 2 | enrolment-service | enrolments, students |
| 3 | auth-service | users, roles, permissions |
No shared schemas or cross-database joins.
For queries across services: use data replication, event-driven updates, or API composition.
Best Practices and Considerations
| Sr.No. | Best Practice | Tables |
|---|---|---|
| 1 | Use domain modeling | Deeply understand the business language |
| 2 | Keep bounded contexts separate | Avoid accidental coupling |
| 3 | Implement shared contracts | Use OpenAPI or shared message formats |
| 4 | Ensure services work together | Use Event Storming or DDD modeling |
| 5 | Use observability tools | Monitor interactions (e.g., Sleuth, Zipkin, Prometheus) |
Real-World Example: Netflix
Netflix decomposes by subdomain−
| Sr.No. | Subdomain | Service Name |
|---|---|---|
| 1 | Playback | video-stream-service |
| 2 | Recommendation | reco-engine-service |
| 3 | Account Management | account-service |
| 4 | Billing | billing-service |
Each team owns one or more subdomains and releases features independently.
Challenges and How to Address Them
| Sr.No. | Challenge | Solution |
|---|---|---|
| 1 | Data consistency | Use eventual consistency + sagas or event sourcing |
| 2 | Duplication of logic/data | Keep services independent, use APIs to sync |
| 3 | Complexity of orchestration | Use orchestration (e.g., Netflix Conductor) or choreography |
| 4 | Domain boundaries unclear | Use Event Storming or DDD modeling |
Conclusion
Decomposition by Subdomain is a powerful pattern that promotes −
Business-aligned services
Autonomous development teams
Scalable and maintainable architecture
It fosters long-term agility by structuring software based on what the business actually does, not just on technology or project constraints.
With proper modeling, tooling, and communication strategies, subdomain decomposition leads to systems that are easier to build, grow, and maintain.
Java Microservices - Backend for Frontend
Microservices architectures offer modularity, scalability, and development agility. But they also introduce new challenges in client-to-service interactions, particularly when multiple clients-such as web apps, mobile apps, and IoT devices-consume backend services differently. The Backend for Frontend (BFF) pattern solves this problem by introducing a customized backend layer for each type of frontend. This article explores the BFF pattern in depth, from its motivation and benefits to its implementation using Spring Boot.
The Challenge with Shared Backends
Let's consider a monolithic or centralized API that serves all clients (web, mobile, desktop). Problems often include −
Over-fetching or under-fetching data
Heavy payloads sent to mobile devices
diverse authentication requirements
Frontend-specific transformations polluting backend logic
Example
| Sr.No. | Frontend | Requirement |
|---|---|---|
| 1 | Web | Full product details + reviews |
| 2 | Mobile | Minimal product summary |
| 3 | SmartWatch | Only product name + price |
A one-size-fits-all backend is suboptimal. You either over-engineer APIs or add complex branching logic in the frontend or backend.
What is the Backend for Frontend (BFF) Pattern?
Definition
Backend for Frontend (BFF) is a microservices design pattern where each type of client gets its own dedicated backend layer that interacts with downstream services and tailors the response specifically for that frontend.
Origin
Coined by Sam Newman, the BFF pattern is widely used in companies like Netflix, Amazon, and Spotify to streamline frontend-backend interactions.
Architecture Overview
Each frontend has its own BFF that −
Aggregates and formats data
Performs client-specific logic
Secures and optimizes communication
Benefits of BFF Pattern
| Sr.No. | Benefit | Description |
|---|---|---|
| 1 | Client-specific APIs | Serve just what the client needs-no more, no less |
| 2 | Reduced frontend logic | Frontend doesn't need to transform or combine data |
| 3 | Better performance | Smaller, optimized payloads for mobile, watches, etc |
| 4 | Simplified backend services | Backend microservices stay generic and reusable |
| 5 | Team autonomy | Separate BFFs allow independent teams for each frontend |
| 6 | Security boundary | Frontends don't directly call internal services |
Real-World Example: E-commerce Platform
Core Microservices
product-service
review-service
inventory-service
user-service
Clients
Web app
Mobile app
BFF Setup
| Sr.No. | BFF | Functions |
|---|---|---|
| 1 | Web BFF | Combines product + reviews + inventory |
| 2 | Mobile BFF | Returns product summary + price only |
BFF Implementation Using Spring Boot
Let's implement two BFFs using Spring Boot: one for Web and one for Mobile.
product-service (Downstream Service)
ProductController.java
@RestController
@RequestMapping("/products")
public class ProductController {
@GetMapping("/{id}")
public Product getProduct(@PathVariable String id) {
return new Product(id, "iPhone 15", "High-end smartphone", 1299.99);
}
}
Web BFF
WebProductController.java
@RestController
@RequestMapping("/web/products")
public class WebProductController {
@Autowired
private RestTemplate restTemplate;
@GetMapping("/{id}")
public Map<String, Object> getFullProduct(@PathVariable String id) {
Product product = restTemplate.getForObject("http://localhost:8081/products/" + id, Product.class);
Map<String, Object> response = new HashMap<>();
response.put("name", product.getName());
response.put("description", product.getDescription());
response.put("price", product.getPrice());
response.put("reviews", List.of("Great phone!", "Excellent display"));
return response;
}
}
Mobile BFF
MobileProductController.java
@RestController
@RequestMapping("/mobile/products")
public class MobileProductController {
@Autowired
private RestTemplate restTemplate;
@GetMapping("/{id}")
public Map<String, Object> getProductSummary(@PathVariable String id) {
Product product = restTemplate.getForObject("http://localhost:8081/products/" + id, Product.class);
Map<String, Object> response = new HashMap<>();
response.put("name", product.getName());
response.put("price", product.getPrice());
return response;
}
}
Note − In production, you'd use service discovery, circuit breakers, caching, and load balancing.
Key Responsibilities of a BFF
| Sr.No. | Responsibility | Why It's Important |
|---|---|---|
| 1 | API Composition | Aggregate results from multiple services |
| 2 | Payload Optimization | Tailor response size and shape |
| 3 | Security Layer | Token validation, OAuth2 flow |
| 4 | Session Handling | Manage session tokens, cookies |
| 5 | Error Handling | Convert internal errors to frontend-appropriate messages |
| 6 | Caching | Apply client-specific caching strategies |
Best Practices
Do:
Create one BFF per frontend (not per team)
Keep BFF logic frontend-specific, not business-specific
Apply rate limiting and auth at BFF layer
Use open APIs internally for microservice communication
Keep BFFs lightweight and stateless
Don't:
Overload BFFs with business logic
Reuse a single BFF for all frontends
Hard-code service URLs (use discovery mechanisms)
Ignore observability and monitoring
Tools and Frameworks
| Sr.No. | Concern | Tools |
|---|---|---|
| 1 | Framework | Spring Boot, Node.js |
| 2 | API Gateway | Spring Cloud Gateway, NGINX |
| 3 | Auth | OAuth2, JWT, Keycloak |
| 4 | Service Discovery | Eureka, Consul |
| 5 | Monitoring | Prometheus, Grafana, ELK |
When Should You Use BFF Pattern?
Ideal When −
Multiple frontends (mobile, web, IoT)
Different data requirements per frontend
Need for optimized client-server communication
Complex aggregation logic required
Security concerns restrict frontend access to backend
Not Ideal If −
Single frontend
Simple system with flat data requirements
Real-World Companies Using BFF
| Sr.No. | Company | Use Case |
|---|---|---|
| 1 | Netflix | Mobile, TV, web apps-each with separate BFFs for performance |
| 2 | Spotify | Separate APIs for mobile and desktop clients with custom features |
| 3 | Amazon | Web and Alexa clients using different response models and BFFs |
Challenges and Mitigation
| Sr.No. | Challenge | Solution |
|---|---|---|
| 1 | Duplicate logic in BFFs | Share common libraries or move to shared microservices |
| 2 | Increased deployment units | Automate CI/CD pipelines |
| 3 | Versioning across BFFs | Use semantic versioning or independent endpoints |
| 4 | Security complexities | Centralize auth logic via API Gateway or shared library |
Conclusion
The Backend for Frontend pattern is a smart strategy to tailor backend communication for different frontend clients. By implementing a dedicated BFF for each frontend, you can−
Optimize performance
Improve user experience
Simplify frontend development
Maintain backend service purity
When used correctly, BFF enhances the agility, modularity, and maintainability of microservices-based systems.
Java Microservices - The Strangler Pattern
Introduction
One of the most challenging tasks in modern software architecture is migrating legacy monolithic systems to microservices without causing service disruptions or rewriting the entire application from scratch. This is where the Strangler Pattern proves invaluable.
Inspired by the way strangler fig trees grow-by slowly enveloping and replacing their host trees-the Strangler Pattern enables a gradual and safe migration. This article explores the pattern in-depth, including its purpose, structure, benefits, challenges, and implementation using Spring Boot.
The Need for the Strangler Pattern
Common Legacy Problems
Difficult to scale monoliths horizontally
High risk and cost in making changes
Long build and deployment times
Technology obsolescence
Poor modularization and code ownership
A complete rewrite of a monolithic system is −
Risky
Expensive
Often unsuccessful due to scope creep
Solution
Strangler Pattern allows for incremental replacement −
Develop new functionality as microservices
Gradually extract old components
Redirect traffic progressively
Retire monolith module by module
What is the Strangler Pattern?
Definition
The Strangler Pattern is a migration strategy that incrementally replaces legacy components by building a facade that routes requests to either the old monolith or the new microservices.
Over time, as microservices take over more responsibilities, the monolith becomes obsolete and can be decommissioned.
Origin
Named by Martin Fowler, inspired by how the strangler fig overtakes host trees over time.
Key Components of the Strangler Pattern
| Sr.No. | Component | Role |
|---|---|---|
| 1 | Facade Layer | Routes incoming requests to monolith or microservices |
| 2 | Legacy Monolith | Existing application codebase |
| 3 | Microservices | New components replacing monolith parts |
| 4 | Routing Logic | Determines where each request should go |
| 5 | Monitoring Tools | Ensure proper behavior during migration |
Diagram: Strangler Pattern in Action
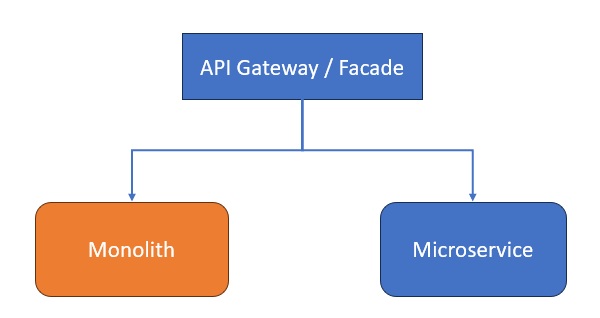
API Gateway forwards requests based on route mappings.
Requests for newer functionality go to microservices.
Legacy requests go to the monolith.
Real-World Use Case
Scenario: Legacy E-commerce Platform
Monolith Responsibilities
Product Catalog
Cart & Checkout
Payments
Order History
Migration Goal
Refactor into microservices
product-service
checkout-service
payment-service
Approach
Facade − Introduce Spring Cloud Gateway as the entry point.
Route old product-related endpoints to monolith.
Route new checkout/payment endpoints to new services.
Gradually migrate and remove old endpoints.
Step-by-Step Implementation Using Spring Boot
Introduce a Gateway (Strangling Point)
Facade − Introduce Spring Cloud Gateway as the entry point.
Route old product-related endpoints to monolith.
Route new checkout/payment endpoints to new services.
Gradually migrate and remove old endpoints.
Use Spring Cloud Gateway −
pom.xml
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-gateway</artifactId> </dependency>
application.yml
spring:
application:
name: api-gateway
cloud:
gateway:
routes:
- id: monolith-service
uri: http://localhost:8080
predicates:
- Path=/products/**, /cart/**
- id: checkout-service
uri: http://localhost:8081
predicates:
- Path=/checkout/**
- id: payment-service
uri: http://localhost:8082
predicates:
- Path=/payment/**
Keep Monolith Intact (Initially)
No code changes in the monolith are needed immediately.
Develop Microservices (e.g., Checkout)
CheckoutController.java
@RestController
@RequestMapping("/checkout")
public class CheckoutController {
@PostMapping("/")
public String checkout(@RequestBody CheckoutRequest req) {
return "Checked out cart ID: " + req.getCartId();
}
}
application.yml (checkout-service)
server:
port: 8081
spring:
application:
name: checkout-service
Gradual Migration
Redirect /checkout to new service
Extract logic for /cart next
Replace /products as last step
Each move is low risk
Advantages of the Strangler Pattern
| Sr.No. | Benefit | Description |
|---|---|---|
| 1 | Incremental Migration | Safely move piece-by-piece to microservices |
| 2 | Reduced Risk | Avoids "big bang" rewrites |
| 3 | Easier Debugging | Only part of the system changes at any time |
| 4 | Reuses Existing Features | Keeps old monolith alive until no longer needed |
| 5 | Supports Parallel Dev | Teams can build new modules while legacy still runs |
Challenges and Solutions
| Sr.No. | Challenge | Solution |
|---|---|---|
| 1 | Routing Complexity | Use Spring Cloud Gateway / Istio for traffic control |
| 2 | Inconsistent Data Models | Use event-driven sync or API composition |
| 3 | Monolith Coupling | Use facade to abstract internals; slowly decouple modules |
| 4 | Dual Maintenance Effort | Keep migration short-lived per module |
| 5 | Authentication Integration | Centralize with OAuth2 / JWT and shared identity provider |
Tools and Technologies for Strangler Pattern
| Sr.No. | Purpose | Tools |
|---|---|---|
| 1 | Routing / Gateway | Spring Cloud Gateway, Istio, NGINX |
| 2 | Service Discovery | Eureka, Consul |
| 3 | Asynchronous Events | Kafka, RabbitMQ |
| 4 | Observability | Sleuth, Zipkin, Prometheus |
| 5 | CI/CD | Jenkins, GitLab CI/CD |
Real-World Example: Amazon
Amazon moved from a monolithic system in the early 2000s to thousands of microservices by −
Introducing API gateways
Migrating single features at a time
Using service ownership by small autonomous teams
Strangler Pattern helped ensure uninterrupted service during their evolution.
When to Use the Strangler Pattern
Use When −
You want minimal risk migration
You must maintain availability
You don't have budget or time for rewrites
The monolith is too large for a full refactor
Avoid If −
The system is small and simple
Conclusion
The Strangler Pattern is a powerful and pragmatic approach to incrementally migrating legacy monolithic systems to modern microservice architectures.
By placing a routing layer between consumers and services, teams can −
Gradually introduce new microservices
Retire legacy components step-by-step
Minimize risk and maximize business continuity
This pattern reduces technical debt progressively and supports long-term modernization efforts, making it one of the most practical patterns in the microservices transition toolkit.
Java Microservices - Synchronous Communication (REST/gRPC)
Introduction
Microservices architecture involves breaking down applications into independently deployable, loosely coupled services. For these services to work cohesively, they must communicate with each other-either synchronously or asynchronously.
This article focuses on the Synchronous Communication pattern, where services interact in real time, expecting immediate responses. The two most widely used technologies for synchronous communication are −
REST (Representational State Transfer)
gRPC (Google Remote Procedure Call)
We will explore both in detail−understanding their use cases, trade-offs, implementation techniques, and how they compare.
What Is Synchronous Communication?
Definition
Synchronous communication in microservices refers to a communication pattern where one service sends a request to another and waits for a response before proceeding.
This is akin to traditional function calls: Service A calls Service B, and waits for the result to continue its execution.
Characteristics of Synchronous Communication
| Sr.No. | Feature | Description |
|---|---|---|
| 1 | Real-time interaction | The client waits until the response is received |
| 2 | Simple error handling | Built-in status codes, retries, and fallbacks |
| 3 | Tightly coupled timing | Both services must be available during communication |
| 4 | Serialization | Data is serialized into formats like JSON (REST) or Protobuf (gRPC) |
Why Use Synchronous Communication?
Ideal for −
Real-time data requirements (e.g., payments, user authentication)
CRUD operations (e.g., read user profile)
Predictable and consistent APIs
Not Ideal for −
High-volume or event-driven scenarios
Long-running processes
Systems requiring decoupling and fault tolerance
Technology Options
| Sr.No. | Protocol | Description | Common Usage |
|---|---|---|---|
| 1 | REST | HTTP-based API using JSON/XML | Web, mobile, HTTP clients |
| 2 | gRPC | Binary protocol over HTTP/2 using Protobuf | Internal microservices, low-latency systems |
Architecture Overview

Service A makes a synchronous request to Service B
Service B processes and responds instantly
If B fails, A must retry or handle the failure
REST-Based Synchronous Communication with Spring Boot
Project Setup
Dependencies (Maven)
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-webflux</artifactId> <!-- Optional for async REST --> </dependency>
Service B: Profile Service
@RestController
@RequestMapping("/profiles")
public class ProfileController {
@GetMapping("/{id}")
public Profile getProfile(@PathVariable String id) {
return new Profile(id, "Alice", "alice@example.com");
}
}
Service A: User Service (REST Client)
@Service
public class ProfileClient {
@Autowired
private RestTemplate restTemplate;
public Profile getProfile(String userId) {
return restTemplate.getForObject("http://profile-service/profiles/" + userId, Profile.class);
}
}
Enable LoadBalanced RestTemplate
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
Configuration (application.yml)
spring:
application:
name: user-service
eureka:
client:
service-url:
defaultZone: http://localhost:8761/eureka
gRPC-Based Synchronous Communication in Spring Boot
Why gRPC?
Feature REST gRPC Format JSON / XML Protocol Buffers (binary) Performance Moderate Very high Streaming Limited Full-duplex supported Language Support Wide Also wide HTTP Version HTTP/1.1 HTTP/2gRPC is ideal for internal service communication requiring low latency.
Setup: Add gRPC Dependencies
Use yidongnan's Spring Boot starter for gRPC −
Maven
<dependency> <groupId>net.devh</groupId> <artifactId>grpc-server-spring-boot-starter</artifactId> <version>2.14.0.RELEASE</version> </dependency> <dependency> <groupId>net.devh</groupId> <artifactId>grpc-client-spring-boot-starter</artifactId> <version>2.14.0.RELEASE</version> </dependency>
Define Proto File
profile.proto
syntax = "proto3";
package profile;
service ProfileService {
rpc GetProfile (ProfileRequest) returns (ProfileResponse);
}
message ProfileRequest {
string userId = 1;
}
message ProfileResponse {
string userId = 1;
string name = 2;
string email = 3;
}
Compile with the Protobuf plugin to generate Java classes.
Implement the gRPC Server
@GrpcService
public class ProfileServiceImpl extends ProfileServiceGrpc.ProfileServiceImplBase {
@Override
public void getProfile(ProfileRequest request, StreamObserver<ProfileResponse> responseObserver) {
ProileResponse response = ProfileResponse.newBuilder()
.setUserId(request.getUserId())
.setName("Alice")
.setEmail("alice@example.com")
.build();
responseObserver.onNext(response);
responseObserver.onCompleted();
}
}
gRPC Client
@Service
public class ProfileGrpcClient {
@GrpcClient("profile-service")
private ProfileServiceGrpc.ProfileServiceBlockingStub stub;
public ProfileResponse getProfile(String userId) {
return stub.getProfile(ProfileRequest.newBuilder().setUserId(userId).build());
}
}
Synchronous Communication Best Practices
| Sr.No. | Practice | Description |
|---|---|---|
| 1 | Circuit Breakers | Use Resilience4j or Hystrix to avoid cascading failures |
| 2 | Timeouts | Set request timeouts to avoid hanging requests |
| 3 | Retries | Automatically retry transient failures |
| 4 | Load Balancing | Use Ribbon, Eureka, or Kubernetes for distributing traffic |
| 5 | Monitoring & Tracing | Use Sleuth, Zipkin, Prometheus for observability |
| 6 | Fallback Mechanisms | Provide alternative responses if a service fails |
Pros and Cons of Synchronous Communication
| Sr.No. | Pros | Cons |
|---|---|---|
| 1 | Simpler to implement and debug | Coupling in availability |
| 2 | Easier data consistency | Not suitable for large-scale, event-driven systems |
| 3 | Familiar request/response model | Latency increases with each network hop |
| 4 | Ideal for chained workflows | Prone to cascading failures |
Use Cases Comparison: REST vs. gRPC
| Sr.No. | Use Case | Recommended Approach |
|---|---|---|
| 1 | Internal microservice communication | gRPC (performance critical) |
| 2 | Mobile/Web communication | REST (browser/client friendly) |
| 3 | Streaming large datasets | gRPC with streaming |
| 4 | Public APIs | REST (easy integration) |
Real-World Example: Netflix
Netflix uses gRPC extensively for internal communications between services like recommendation engines and playback servers, due to its high performance and contract-first development.
However, for public APIs, Netflix still uses REST with GraphQL for client flexibility.
When to Use Synchronous Communication
Use When
Real-time responses are required
Workflow depends on sequential execution
Systems are under control in terms of scale
Avoid When
Services are frequently unavailable
High-volume traffic or long processing is involved
Decoupling and resilience are key priorities
Conclusion
Synchronous communication is a core pattern in microservices that enables real-time, request-response interaction between services. With REST and gRPC as the leading technologies, you can choose based on −
Performance needs (gRPC)
Interoperability (REST)
Use case complexity
For mission-critical, performance-sensitive applications, gRPC is highly effective. For client-facing and public APIs, REST remains the default choice.
Design your system based on communication patterns that align with business and technical requirements.
Java Microservices - Asynchronous Communication
Introduction
As microservices become more complex, their need for effective communication grows. Traditionally, services interact synchronously-one service calls another and waits for a response. However, this model can lead to tight coupling, reduced resilience, and latency issues.
To address these challenges, modern systems often rely on Asynchronous Communication, especially via Event-Driven Architecture (EDA). In this model, services publish and subscribe to events, enabling loose coupling, scalability, and high performance.
This article explores the asynchronous communication model using RabbitMQ and Apache Kafka, and demonstrates practical implementations using Spring Boot.
What is Asynchronous Communication?
Definition
Asynchronous communication is a pattern where services interact without waiting for a direct response. Messages or events are sent and received independently, typically via message brokers or event buses.
Characteristics
Non-blocking communication
Services don't need to be online simultaneously
Interaction via queues, topics, or streams
Enables event-driven workflows
Why Use Asynchronous Communication in Microservices?
Advantages
Example
| Sr.No. | Feature | Benefit |
|---|---|---|
| 1 | Loose Coupling | Services don't directly depend on each other |
| 2 | Resilience | Failures in one service don't cascade |
| 3 | Scalability | Easily scale consumers independently |
| 4 | Performance | No waiting for slow downstream responses |
| 5 | Decoupled Development | Teams can build services independently |
Common Use Cases
Order processing
Email notifications
Event sourcing
Payment workflows
Audit and logging
Architecture of Event-Driven Microservices
Key Components
| Sr.No. | Component | Role |
|---|---|---|
| 1 | Producer | Sends events (e.g., OrderPlaced) |
| 2 | Broker | Delivers events (RabbitMQ, Kafka, etc.) |
| 3 | Consumer | Subscribes to and processes events |
Diagram
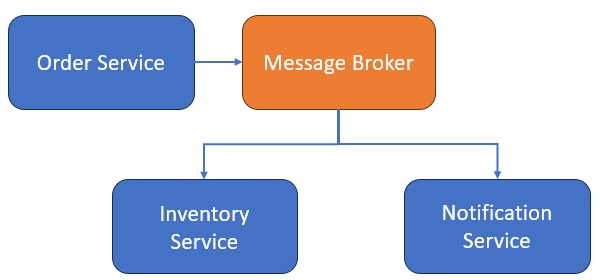
Technologies for Asynchronous Communication
| Sr.No. | Tool | Description | Best Use Cases |
|---|---|---|---|
| 1 | RabbitMQ | Lightweight message broker using AMQP | Task queues, retry queues, real-time alerts |
| 2 | Kafka | Distributed event streaming platform | High-volume data, event sourcing, audit |
| 3 | ActiveMQ | Legacy support, JMS compatibility | Java-based systems |
| 4 | Amazon SNS/SQS | Managed messaging services | Cloud-native systems |
Asynchronous Communication with RabbitMQ and Spring Boot
Overview of RabbitMQ
RabbitMQ is a message queueing broker that supports multiple protocols, primarily AMQP. It uses exchanges, queues, and bindings.
Exchange − Routes messages
Queue − Stores messages until consumed
Binding − Connects exchanges to queues
Setup (Spring Boot)
Maven Dependencies−
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-amqp</artifactId> </dependency>
Producer Example: Order Service
@Service
public class OrderProducer {
@Autowired
private RabbitTemplate rabbitTemplate;
public void sendOrderEvent(Order order) {
rabbitTemplate.convertAndSend("order.exchange", "order.routingKey", order);
}
}
Configuration
@Configuration
public class RabbitMQConfig {
@Bean
public Queue orderQueue() {
return new Queue("order.queue", true);
}
@Bean
public DirectExchange exchange() {
return new DirectExchange("order.exchange");
}
@Bean
public Binding binding() {
return BindingBuilder
.bind(orderQueue())
.to(exchange())
.with("order.routingKey");
}
}
Consumer Example: Inventory Service
@Service
public class InventoryConsumer {
@RabbitListener(queues = "order.queue")
public void handleOrder(Order order) {
System.out.println("Processing inventory for order: " + order.getId());
}
}
Asynchronous Communication with Apache Kafka
Overview of Kafka
Apache Kafka is a distributed, fault-tolerant event streaming platform.
Producer− Publishes messages to a topic
Consumer− Subscribes to topic(s)
Broker− Manages topics and partitions
Topic− Logical stream of events
Setup (Spring Boot)
Maven Dependencies −
<dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency>
Producer Example: Order Service
@Service
public class KafkaOrderProducer {
@Autowired
private KafkaTemplate<String, Order> kafkaTemplate;
public void sendOrder(Order order) {
kafkaTemplate.send("order-topic", order);
}
}
Kafka Configuration
spring:
kafka:
bootstrap-servers: localhost:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
consumer:
group-id: inventory-service
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
Consumer Example: Inventory Service
@Service
public class KafkaOrderConsumer {
@KafkaListener(topics = "order-topic", groupId = "inventory-service")
public void consume(Order order) {
System.out.println("Inventory updated for Order: " + order.getId());
}
}
Comparison: RabbitMQ vs Kafka
| Sr.No. | Feature | RabbitMQ | Apache Kafka |
|---|---|---|---|
| 1 | Model | Message Queue (Push) | Event Log (Pull) |
| 2 | Message Retention | Deletes after consumption | Retains for configured period |
| 3 | Use Case | Real-time messaging | Event streaming, audit, analytics |
| 4 | Performance | Good for low/medium volume | Excellent for high-throughput |
| 5 | Delivery Guarantees | At most once / at least once | Exactly once (with config) |
| 6 | Built-in Features | Dead-letter queues, priority | Stream replay, partitioning |
Best Practices
| Sr.No. | Practice | Description |
|---|---|---|
| 1 | Idempotency | Ensure consumers handle duplicate events safely |
| 2 | Dead-letter Queues (DLQs) | Handle failed messages without losing them |
| 3 | Retries and Backoff | Use exponential backoff for transient failures |
| 4 | Message Versioning | Support schema evolution |
| 5 | Monitoring & Tracing | Use Zipkin, Prometheus, Kafka UI for observability |
| 6 | Async Boundaries | Use command/event distinction (e.g., OrderPlaced vs OrderConfirmed) |
Real-World Use Cases
| Sr.No. | Company | Event-Driven Use Case |
|---|---|---|
| 1 | Uber | Geolocation updates, surge pricing via Kafka |
| 2 | Netflix | User activity tracking, recommendation pipelines with Kafka |
| 3 | Shopify | Order fulfillment via RabbitMQ |
| 4 | Built Kafka for internal use−event sourcing at scale |
When to Use Asynchronous Communication
Ideal For −
High-volume systems
Background task processing
Decoupled architectures
Event sourcing and audit trails
Retry-able workflows (notifications, billing, etc.)
Not Ideal When −
Immediate response is required
Simple request-response is sufficient
External system mandates synchronous calls (e.g., payment gateway)
Conclusion
Asynchronous communication is a key architectural pattern for building scalable, resilient, and event-driven microservices.
RabbitMQ is a great choice for lightweight message-based systems.
Apache Kafka shines in high-throughput, log-based systems.
By adopting this pattern, organizations gain the flexibility to −
Decouple services
Increase responsiveness
Handle complex workflows
Enable real-time data pipelines
When combined with proper tooling and best practices, asynchronous communication becomes a cornerstone of robust microservices systems.
Java Microservices - Saga Pattern
Introduction
As businesses embrace microservices architecture, one major challenge arises: how to maintain data consistency across distributed services. In traditional monoliths, a database transaction ensures ACID properties. But in microservices, each service often manages its own database − making distributed transactions difficult.
The Saga pattern is a solution to this problem. It allows services to collaborate on a long-running business transaction by exchanging a sequence of local transactions and compensating actions when needed.
This article explores the Saga pattern in detail, including its types, real-world examples, implementation with Spring Boot, and best practices.
What is Saga Pattern?
A Saga is a sequence of local transactions, where each transaction updates data within a single microservice and publishes an event or calls the next service. If one transaction fails, the Saga executes compensating transactions to undo the impact of previous ones.
A saga is a failure management pattern for long-running distributed transactions.
Why Do We Need Sagas?
Challenges in Distributed Transactions
| Sr.No. | Challenge | Description |
|---|---|---|
| 1 | Lack of global transactions | No XA/2PC (Two Phase Commit) across microservices |
| 2 | Data ownership | Each service owns its data (Database per service) |
| 3 | Partial failures | Some steps may succeed, others may fail |
| 4 | Consistency | Eventual consistency instead of strict ACID |
The Saga pattern helps orchestrate distributed workflows with eventual consistency.
Types of Saga Implementations
Choreography Based Saga
No central controller
Services listen to events and act accordingly
Lightweight, but complex with many services
Example Flow
Order Service → emits OrderCreated
Payment Service → listens, processes payment → emits PaymentCompleted
Inventory Service → reserves stock → emits InventoryReserved
Shipping Service → ships item
If any step fails, a compensating event is triggered.
Orchestration-Based Saga
Central Saga orchestrator directs the flow
Each service executes commands from the orchestrator
Easier to manage, but introduces coupling
Example Flow
Orchestrator → calls Order Service
On success → calls Payment Service
On failure → instructs Order Service to cancel
Real-World Example: E-Commerce Order Processing
Steps
Place Order
Reserve Inventory
Process Payment
Ship Item
Each service has a local database and transaction logic.
If payment fails, we must −
Cancel the order
Release the inventory
This is handled by a Saga.
Saga architecture
Diagram: Choreography Based Saga
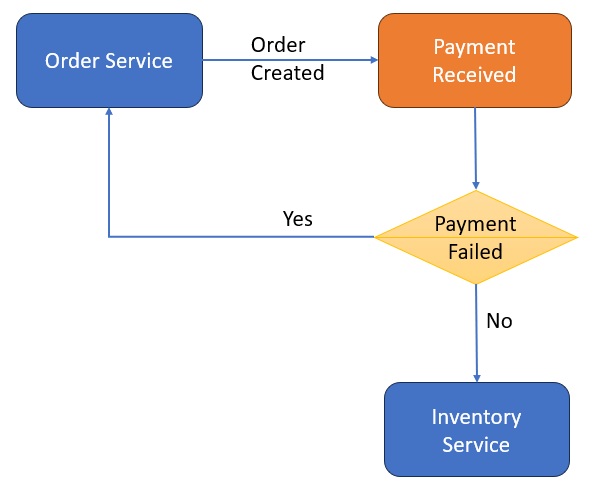
Each service publishes and subscribes to events through a broker like Kafka or RabbitMQ.
Implementing Saga Pattern in Spring Boot
Let's implement a Choreography based saga using Spring Boot + Kafka.
Technologies Used
Spring Boot
Spring Kafka
Apache Kafka (as the event broker)
Lombok for model simplification
Maven Dependencies
<dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <scope>provided</scope> </dependency>
Example Services and Topics
| Sr.No. | Service | Events Published | Topics Subscribed |
|---|---|---|---|
| 1 | Order Service | OrderCreated, OrderCancelled | PaymentFailed, InventoryFailed |
| 2 | Payment Service | PaymentCompleted, PaymentFailed | OrderCreated |
| 3 | Inventory Service | InventoryReserved, InventoryFailed | PaymentCompleted |
Sample Event: OrderCreatedEvent.java
@Data
@AllArgsConstructor
@NoArgsConstructor
public class OrderCreatedEvent {
private String orderId;
private String productId;
private int quantity;
}
Order Service − Kafka Producer
@Service
public class OrderService {
@Autowired
private KafkaTemplate<String, Object> kafkaTemplate;
public void createOrder(OrderCreatedEvent event) {
kafkaTemplate.send("order-created", event);
}
}
Payment Service − Kafka Consumer
@KafkaListener(topics = "order-created", groupId = "payment-service")
public void handleOrder(OrderCreatedEvent event) {
// Process payment
boolean success = processPayment(event);
if (success) {
kafkaTemplate.send("payment-completed", new PaymentCompletedEvent(event.getOrderId()));
} else {
kafkaTemplate.send("payment-failed", new PaymentFailedEvent(event.getOrderId()));
}
}
Inventory Service − Kafka Consumer
@KafkaListener(topics = "payment-completed", groupId = "inventory-service")
public void handlePayment(PaymentCompletedEvent event) {
// Reserve inventory
boolean success = reserveStock(event.getOrderId());
if (success) {
kafkaTemplate.send("inventory-reserved", new InventoryReservedEvent(event.getOrderId()));
} else {
kafkaTemplate.send("inventory-failed", new InventoryFailedEvent(event.getOrderId()));
}
}
Saga Compensation and Failure Handling
Compensating Transactions
If a step fails (e.g., inventory reservation), previous actions must be reversed−
InventoryFailed → triggers PaymentRollback
PaymentFailed → triggers OrderCancelled
These compensating actions must be idempotent and safe to retry.
Benefits of the Saga Pattern
| Sr.No. | Benefit | Description |
|---|---|---|
| 1 | Decentralized workflow | Maintains autonomy of microservices |
| 2 | Resilience | Can recover from partial failures |
| 3 | Eventual consistency | Instead of strict ACID transactions |
| 4 | Scalable and fault-tolerant | Built on asynchronous messaging |
Challenges and Pitfalls
| Sr.No. | Challenge | Mitigation |
|---|---|---|
| 1 | Complex error handling | Use retries and DLQs |
| 2 | Debugging flows | Use tracing tools like Zipkin |
| 3 | Compensating logic overhead | Modularize and isolate business logic |
| 4 | Message ordering issues | Use Kafka partitions wisely |
Testing a Saga
Approaches
Use Testcontainers to simulate Kafka or RabbitMQ
Verify event flow using integration tests
Mock downstream services using WireMock
Simulate failures to test compensation logic
Real-World Examples
| Sr.No. | Company | Use of Saga Pattern |
|---|---|---|
| 1 | Netflix | Manages distributed workflows in video delivery |
| 2 | Booking.com | Manages hotel bookings, payments, and cancellations |
| 3 | Uber | Handles driver assignment, payments, and cancellations |
| 4 | Amazon | Processes multi-step order and inventory systems |
Best Practices
| Sr.No. | Practice | Reason |
|---|---|---|
| 1 | Use separate event models | Avoid domain model leakage |
| 2 | Make compensating actions idempotent | Safe retries |
| 3 | Implement timeouts | Avoid stuck sagas |
| 4 | Track saga state | Use DB or state store |
| 5 | Use correlation IDs | Easier debugging and tracing |
Conclusion
The Saga pattern provides an elegant solution to the problem of distributed transactions in a microservices architecture. Whether using choreography or orchestration, sagas enable services to maintain data consistency, handle failures gracefully, and ensure resilient workflows.
By combining Spring Boot with Kafka or orchestration engines, developers can build reliable, scalable, and maintainable systems that operate effectively across service boundaries.
Java Microservices - Centralized Logging (ELK Stack)
Introduction
As microservices become the norm for building large-scale, distributed applications, operational challenges increase-especially in monitoring and troubleshooting. Each microservice may run on separate hosts, containers, or clusters, generating logs in different formats and locations.
Centralized Logging is a critical design pattern in microservices architecture. It allows the aggregation of logs from all services into a single searchable system, enabling faster diagnostics, alerting, and auditing.
One of the most popular solutions for centralized logging is the ELK Stack, which stands for Elasticsearch, Logstash, and Kibana.
Why Centralized Logging?
Logging in Monolith vs Microservices
| Sr.No. | Feature | Monolith | Microservices |
|---|---|---|---|
| 1 | Log Location | Single location | Multiple services, containers, and hosts |
| 2 | Troubleshooting | Easier (single log file) | Harder (correlating across services) |
| 3 | Log Format | Uniform | Varies across services |
| 4 | Access | Simple | Complex in distributed environments |
Problems Without Centralized Logging
Logs are scattered across nodes and services.
Difficult to trace a request end-to-end.
Inconsistent logging formats.
No support for full-text search or visualization.
Troubleshooting becomes time-consuming and error-prone.
What is the ELK Stack?
The ELK Stack is an open-source collection of tools designed to collect, analyze, and visualize logs in real time.
| Sr.No. | Component | Role |
|---|---|---|
| 1 | Elasticsearch | Distributed search and analytics engine |
| 2 | Logstash | Data processing pipeline for log ingestion |
| 3 | Kibana | Visualization tool for dashboards and queries |
The ELK Stack is often extended with Beats (e.g., Filebeat) for lightweight data shipping.
ELK Stack Architecture in Microservices
Architecture Overview
Filebeat reads logs from microservices.
Logstash parses, filters, and ships logs.
Elasticsearch indexes and stores logs.
Kibana lets you search and visualize log data.
Benefits of Centralized Logging
| Sr.No. | Benefit | Description |
|---|---|---|
| 1 | Single View of All Logs | Unified access to logs from all microservices |
| 2 | Faster Troubleshooting | Trace errors across services using filters/search |
| 3 | Enhanced Security | Logs are protected centrally instead of scattered files |
| 4 | Analytics & Dashboards | Kibana enables real-time metrics and visualizations |
| 5 | Auditing and Compliance | Historical logs can be retained and searched |
| 6 | Scalability | Elasticsearch handles high-volume log data |
Integrating Spring Boot with ELK
Configure Log Output Format (JSON)
Use logstash-logback-encoder −
Maven Dependency
<dependency> <groupId>net.logstash.logback</groupId> <artifactId>logstash-logback-encoder</artifactId> <version>7.4</version> </dependency>
logback-spring.xml
<configuration>
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>localhost:5000</destination>
<encoder class="net.logstash.logback.encoder.LogstashEncoder" />
</appender>
<root level="INFO">
<appender-ref ref="LOGSTASH" />
</root>
</configuration>
This sends structured JSON logs to Logstash via TCP.
Setting Up the ELK Stack
Install via Docker Compose
version: '3.7'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:8.10.0
environment:
- discovery.type=single-node
ports:
- "9200:9200"
logstash:
image: docker.elastic.co/logstash/logstash:8.10.0
volumes:
- ./logstash.conf:/usr/share/logstash/pipeline/logstash.conf
ports:
- "5000:5000"
kibana:
image: docker.elastic.co/kibana/kibana:8.10.0
ports:
- "5601:5601"
Sample Logstash Configuration (logstash.conf)
input {
tcp {
port => 5000
codec => json
}
}
output {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "microservices-logs"
}
}
Viewing Logs in Kibana
Access Kibana at http://localhost:5601
Go to "Discover" → Select microservices-logs index
Use filters like−
level: ERROR
serviceName: order-service
@timestamp > now-1h
You can also create −
Real-time dashboards
Alerts for errors
Graphs for log frequency over time
Correlating Logs with Trace IDs
To trace a request across services−
Use a correlation ID or trace ID
Pass it via HTTP headers or message brokers
Include it in every log entry
Best Practices
| Sr.No. | Best Practice | Reason |
|---|---|---|
| 1 | Use structured JSON logging | Easier parsing and searching |
| 2 | Implement correlation IDs | Trace requests across services |
| 3 | Use log levels wisely | Avoid flooding Elasticsearch with DEBUG logs |
| 4 | Configure log retention policies | Save storage and meet compliance |
| 5 | Secure access to Kibana | Prevent unauthorized data exposure |
| 6 | Monitor Elasticsearch health | Avoid index overloads |
Alternatives to ELK Stack
| Sr.No. | Tool | Description |
|---|---|---|
| 1 | EFK Stack | ELK + Fluentd (instead of Logstash) |
| 2 | OpenSearch | Fork of Elasticsearch/Kibana maintained by AWS |
| 3 | Datadog, Splunk | Paid observability platforms |
| 4 | Grafana Loki | Lightweight logging solution, integrates with Prometheus |
Real-World Use Cases
| Sr.No. | Company | Use of Centralized Logging |
|---|---|---|
| 1 | Netflix | Observability of thousands of microservices |
| 2 | Airbnb | Analyses structured logs to detect production issues |
| 3 | Uber | Tracks end-to-end request latency with centralized logs |
| 4 | Uses structured logging for internal debugging |
Challenges and Limitations
| Sr.No. | Challenge | Solution |
|---|---|---|
| 1 | High storage usage | Implement log rotation and TTL |
| 2 | Parsing unstructured logs | Use Logstash filters or structured formats |
| 3 | Elasticsearch overload | Use ILM (Index Lifecycle Management) |
| 4 | Complex configuration | Use managed services (e.g., AWS OpenSearch) |
Conclusion
Centralized Logging with ELK Stack is essential for managing modern, distributed microservices systems. It brings together logs from all services into one place, enabling −
Real-time monitoring
Faster root-cause analysis
Improved security and auditing
Scalable observability
By integrating Spring Boot with Logstash, and visualizing logs in Kibana, teams gain a powerful toolkit to ensure operational excellence in microservices architectures.
Java Microservices - Event Sourcing
Introduction
In traditional systems, application state is stored as the current value of entities. For example, if a user updates their address, the database reflects only the latest address.
But in microservices, sometimes it's necessary to store a full history of changes - not just the final state.
Event Sourcing is a powerful design pattern that solves this by storing changes to application state as a sequence of events. Instead of only saving the current state, you store all events that led to it.
What is Event Sourcing?
Definition
Event Sourcing is a pattern in which every change to the state of an application is captured in an event object, and those events are persisted. The current state is then rebuilt by replaying the sequence of past events.
Example
Instead of storing:
{ "accountBalance": 1000 }
You store events like:
[
{ "type": "AccountCreated", "amount": 0 },
{ "type": "DepositMade", "amount": 1000 }
]
Replaying these events leads to the current balance.
Key Concepts of Event Sourcing
| Sr.No. | Concept | Description |
|---|---|---|
| 1 | Event | Immutable fact describing what happened |
| 2 | Aggregate | Entity that applies events to rebuild state |
| 3 | Event Store | Database or broker where events are saved |
| 4 | Projection | Read model built from event stream |
| 5 | Replay | Rebuilding state by applying past events |
Benefits of Event Sourcing
| Sr.No. | Benefit | Explanation |
|---|---|---|
| 1 | Auditability | Full history of what happened and when |
| 2 | Debugging & Replayability | Reconstruct bugs by replaying events |
| 3 | Temporal Queries | View system state at any point in time |
| 4 | Decoupling | Services can react to events asynchronously |
| 5 | Event-Driven Integration | Pairs naturally with messaging patterns |
Use Cases in Microservices
| Sr.No. | Domain | Event Sourcing Use Case |
|---|---|---|
| 1 | Banking | Transactions, audit trails |
| 2 | eCommerce | Orders, inventory changes |
| 3 | Healthcare | Patient record changes |
| 4 | Logistics | Shipment events and delivery status |
Spring Boot Example: Simple Event Sourcing for Account
We will build a simple Account microservice that −
Accepts commands like CreateAccount, DepositMoney
Persists events to an in-memory list (simulating event store)
Applies events to rebuild account balance
Technologies
Java 17+
Spring Boot 3.x
Model: Domain Event Base Class
public interface DomainEvent {
LocalDateTime occurredAt();
}
Account Events
public class AccountCreatedEvent implements DomainEvent {
private final String accountId;
private final LocalDateTime occurredAt = LocalDateTime.now();
public AccountCreatedEvent(String accountId) {
this.accountId = accountId;
}
public String getAccountId() { return accountId; }
public LocalDateTime occurredAt() { return occurredAt; }
}
public class MoneyDepositedEvent implements DomainEvent {
private final String accountId;
private final double amount;
private final LocalDateTime occurredAt = LocalDateTime.now();
public MoneyDepositedEvent(String accountId, double amount) {
this.accountId = accountId;
this.amount = amount;
}
public String getAccountId() { return accountId; }
public double getAmount() { return amount; }
public LocalDateTime occurredAt() { return occurredAt; }
}
Event Store (In-Memory)
@Service
public class EventStore {
private final List<DomainEvent> events = new ArrayList<>();
public void save(DomainEvent event) {
events.add(event);
}
public List<DomainEvent> getEventsForAccount(String accountId) {
return events.stream()
.filter(e -> {
if (e instanceof AccountCreatedEvent ac) {
return ac.getAccountId().equals(accountId);
} else if (e instanceof MoneyDepositedEvent md) {
return md.getAccountId().equals(accountId);
}
return false;
})
.toList();
}
}
Aggregate: Account
public class Account {
private final String accountId;
private double balance = 0;
public Account(String accountId) {
this.accountId = accountId;
}
public void apply(DomainEvent event) {
if (event instanceof AccountCreatedEvent) {
// no-op
} else if (event instanceof MoneyDepositedEvent e) {
this.balance += e.getAmount();
}
}
public double getBalance() {
return balance;
}
}
Command Controller
@RestController
@RequestMapping("/accounts")
public class AccountController {
@Autowired
private EventStore store;
@PostMapping("/{id}/create")
public ResponseEntity<String> createAccount(@PathVariable String id) {
AccountCreatedEvent event = new AccountCreatedEvent(id);
store.save(event);
return ResponseEntity.ok("Account created: " + id);
}
@PostMapping("/{id}/deposit")
public ResponseEntity<String> deposit(@PathVariable String id, @RequestParam double amount) {
MoneyDepositedEvent event = new MoneyDepositedEvent(id, amount);
store.save(event);
return ResponseEntity.ok("Deposited " + amount);
}
@GetMapping("/{id}")
public ResponseEntity<String> getBalance(@PathVariable String id) {
List<DomainEvent> events = store.getEventsForAccount(id);
Account account = new Account(id);
events.forEach(account::apply);
return+ ResponseEntity.ok("Balance: " + account.getBalance());
}
}
Combining with CQRS
Event Sourcing works beautifully with CQRS −
Command model modifies state via events
Query model uses projections of those events
Can use different databases for read/write
This enables high scalability and responsiveness for read-heavy systems.
Tools and Frameworks
| Sr.No. | Tool / Library | Description |
|---|---|---|
| 1 | Axon Framework | Java framework for CQRS + Event Sourcing |
| 2 | Eventuate | Platform for event-driven microservices |
| 3 | Kafka | Durable distributed event store |
| 4 | PostgreSQL | Can be used as event store with event tables |
| 5 | Debezium | CDC (Change Data Capture) tool for generating events from DB changes |
Summary
| Sr.No. | Topic | Key Takeaway |
|---|---|---|
| 1 | What is Event Sourcing | Store state as events |
| 2 | Benefits | Audit, scalability, debugging |
| 3 | Implementation | Events + Aggregates + Event Store |
| 4 | Best Fit | Complex domains, financial logs |
| 5 | Tools | Axon, Kafka, Spring Boot |
Conclusion
Event Sourcing is a powerful pattern that provides traceability, scalability, and flexibility. When combined with microservices and messaging tools like Kafka, it enables robust, event-driven architectures.
While it introduces complexity, especially around modeling and querying, the long-term benefits−especially in systems requiring audit, replay, and high scalability-are significant.
Start small with in-memory event logs or lightweight projections, and grow into full-fledged event-sourced systems as your microservices mature.
Java Microservices - Command Query Responsibility Segregation (CQRS)
Introduction
In traditional CRUD-based applications, the same data model is used to perform both read and write operations. While simple and effective for smaller systems, this model introduces limitations as applications scale in size, complexity, and performance demands.
Command Query Responsibility Segregation (CQRS) is a design pattern that separates the read (query) and write (command) responsibilities of an application into distinct models, often even across different services or databases.
This article explains CQRS in detail, especially in the context of microservices, and provides implementation guidance using Spring Boot.
What is CQRS?
Definition
CQRS stands for −
Command − Operations that modify state (Create, Update, Delete).
Query − Operations that retrieve data (Read).
In CQRS, commands and queries are handled by separate models. This improves scalability, clarity, and performance−especially for applications with complex domain logic or high read/write loads.
| Sr.No. | Feature | Traditional CRUD | CQRS |
|---|---|---|---|
| 1 | Model | Single model for both read and write | Separate models |
| 2 | Data store | One database | Can use separate databases |
| 3 | Performance | Limited optimization | Queries and commands optimized independently |
| 4 | Complexity | Simple | More complex architecture |
| 5 | Scaling | Hard to scale reads and writes separately | Easy to scale separately |
Why Use CQRS in Microservices?
Microservices often need to support −
High-volume reads (analytics, dashboards)
Complex writes (business logic, transactions)
Separate service responsibilities
CQRS allows microservices to −
Decouple the read model from the domain model
Use denormalized views for fast querying
Improve performance and scalability
Simplify event-driven communication
CQRS Architecture Overview
Here's a typical CQRS architecture in a microservice −
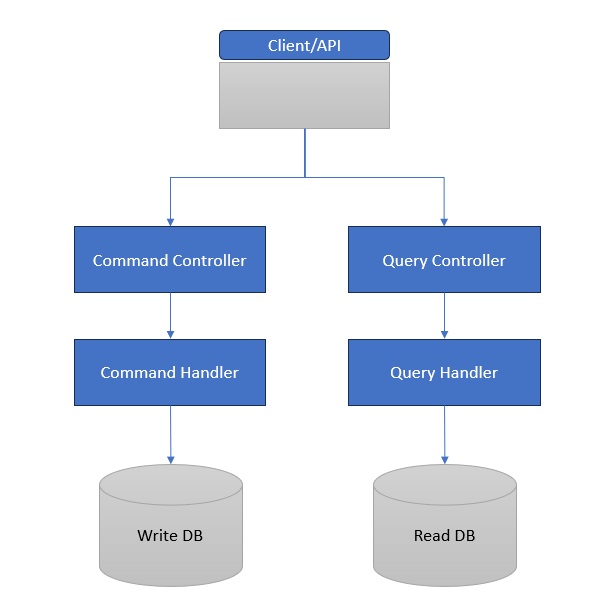
Commands go through a command handler to update the write database.
Queries are executed against a read-optimized store (e.g., denormalized or cache).
Implementation Example in Spring Boot
Let's create a simple Product Service using CQRS−
Use Case
POST /products – Create a product
GET /products/{id} – Get product details
Maven Dependencies
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
</dependencies>
Domain Model
@Entity
public class Product {
@Id
private UUID id;
private String name;
private double price;
// Getters and Setters
}
Command: Create Product
DTO
public class CreateProductCommand {
private String name;
private double price;
// Getters and Setters
}
Product Repository
public interface ProductRepository extends JpaRepository<Product, UUID>{
}
Command Handler
@Service
public class ProductCommandHandler {
@Autowired
private ProductRepository productRepository;
public UUID handle(CreateProductCommand command) {
Product product = new Product();
product.setId(UUID.randomUUID());
product.setName(command.getName());
product.setPrice(command.getPrice());
productRepository.save(product);
return product.getId();
}
}
Command Controller
@RestController
@RequestMapping("/products")
public class ProductCommandController {
@Autowired
private ProductCommandHandler handler;
@PostMapping
public ResponseEntity createProduct(@RequestBody CreateProductCommand cmd) {
UUID id = handler.handle(cmd);
return ResponseEntity.ok("Product created with ID: " + id);
}
}
Query: Read Product
DTO
public class ProductView {
private UUID id;
private String name;
private double price;
}
Query Handler
@Service
public class ProductQueryHandler {
@Autowired
private ProductRepository productRepository;
public ProductView getById(UUID id) {
Product product = productRepository.findById(id).orElseThrow();
ProductView view = new ProductView();
view.setId(product.getId());
view.setName(product.getName());
view.setPrice(product.getPrice());
return view;
}
}
Query Controller
@RestController
@RequestMapping("/products")
public class ProductQueryController {
@Autowired
private ProductQueryHandler handler;
@GetMapping("/{id}")
public ResponseEntity getProduct(@PathVariable UUID id) {
return ResponseEntity.ok(handler.getById(id));
}
}
Event-Driven CQRS with Kafka or RabbitMQ
In advanced scenarios −
Write service publishes events (e.g., ProductCreatedEvent)
Read service listens and updates a read store (denormalized view)
Benefits of CQRS
| Sr.No. | Benefit | Description |
|---|---|---|
| 1 | Performance Optimization | Read and write stores optimized separately |
| 2 | Scalability | Independent scaling of read and write paths |
| 3 | Separation of Concerns | Cleaner code and responsibilities |
| 4 | Denormalized Read Model | Faster reads via projections |
| 5 | Supports Event Sourcing | Easily integrates with event-driven design |
When to Use CQRS
| Sr.No. | Use When... | Avoid When... |
|---|---|---|
| 1 | You have high read/write load imbalance | Your app is simple with CRUD operations |
| 2 | You need to scale reads independently | There's no performance bottleneck |
| 3 | You use event-driven architecture | You need strong consistency everywhere |
| 4 | You require audit/event trail | Your domain logic is very basic |
Real-World Examples
| Sr.No. | Company | Usage of CQRS |
|---|---|---|
| 1 | Uber | Separate command/log and query/search systems |
| 2 | News feed write model vs read-optimized cache |
Summary
| Sr.No. | Aspect | Details |
|---|---|---|
| 1 | Pattern | CQRS (Command Query Responsibility Segregation) |
| 2 | Use | Decouple read and write responsibilities |
| 3 | Implementation | Handlers, separate models, optional events |
| 4 | Tools | Spring Boot, Spring Web, Spring Data JPA |
| 5 | Advanced | Kafka, Event Sourcing, NoSQL for reads |
Conclusion
CQRS is a powerful architectural pattern for building scalable, maintainable, and efficient microservices. It enables better separation of concerns, supports modern patterns like event sourcing, and provides performance benefits in high-scale systems.
Java Microservices - Sidecar Design Pattern
What Is the Sidecar Pattern?
The Sidecar pattern is a microservices design pattern where a service (the "sidecar") runs in the same environment as the primary application but as a separate process. It's deployed alongside the main application service-within the same container, pod, or virtual machine-but remains logically independent.
Key principle− The sidecar enhances or augments the primary service by offloading infrastructure concerns such as logging, service discovery, proxying, or monitoring.
Why "Sidecar"?
The term draws its name from a motorcycle sidecar. Just as a sidecar adds functionality (e.g., carrying an extra passenger) without modifying the core vehicle, the sidecar service augments an app without changing its code.
How the Sidecar Pattern Works
In Kubernetes, the Sidecar pattern is most commonly implemented by deploying two containers in the same pod −
Application container − Runs the business logic (e.g., a payment microservice).
Sidecar container − Handles auxiliary responsibilities (e.g., collecting logs, managing network traffic).
Because they're in the same pod −
They share network space (localhost communication).
They can share volumes (logs, configurations).
They scale together-ensuring consistent availability.
In other environments, sidecars might be separate processes running on the same virtual machine or physical host.
Key Use Cases of the Sidecar Pattern
Service Proxying (e.g., Envoy, Linkerd Proxy)
Used in service meshes, sidecars act as intercepting proxies for outbound and inbound traffic. This allows centralized control over −
Traffic routing
Mutual TLS encryption
Circuit breaking
Metrics collection
Observability: Logging, Monitoring, Tracing
Offloading logging, metrics, and tracing to sidecars helps keep services focused on business logic while ensuring platform observability.
Examples
A Fluent Bit sidecar for log shipping
Prometheus exporter sidecar for app metrics
Configuration Sync & Secrets Management
A sidecar can watch for config or secret changes and inject updates into the primary container's file system or environment.
Examples
HashiCorp Vault agent sidecar for secrets injection
Consul Template for config rendering
Service Discovery
Rather than baking in service discovery logic, sidecars can handle dynamic service registration and discovery with tools like Consul, Eureka, or DNS-based resolution.
Language-Agnostic Capabilities
Sidecars enable polyglot architectures-services in different languages can rely on a uniform mechanism for observability, traffic, and security.
Advantages of the Sidecar Pattern
Separation of Concerns
Sidecars offload generic operational responsibilities from the app code. Your services stay focused on business logic.
Language and Platform Agnostic
Since the sidecar is a separate process, it can support any application, regardless of the language or framework used.
Uniform Policy Enforcement
You can enforce consistent logging, security, traffic shaping, and monitoring across all services without modifying their code.
Scalability and Flexibility
Sidecars scale with the app, making them ideal for dynamic environments like Kubernetes. And since they are loosely coupled, sidecars can be independently upgraded or replaced.
Fail-Safe Wrappers
If the sidecar fails, the app can often continue running (depending on what the sidecar handles). This makes system failure more graceful.
Drawbacks and Limitations
Increased Resource Usage
Every instance of a service includes a sidecar, effectively doubling container count and consuming more memory/CPU.
Operational Overhead
Managing, configuring, and monitoring all sidecars−especially in a large fleet-can add significant complexity.
Coupling in Practice
While logically independent, sidecars are operationally coupled to the application. A misbehaving sidecar can impact service availability.
Debugging Complexity
With multiple moving parts in every pod, debugging becomes harder-logs are split, interactions are indirect, and network traces can be opaque.
Real-World Examples
Istio Service Mesh
Istio deploys Envoy as a sidecar alongside each microservice. These proxies intercept and manage all traffic, enabling −
Mutual TLS
Advanced routing (e.g., canary, A/B)
Tracing with Zipkin or Jaeger
Resilience patterns (timeouts, retries)
The sidecar model is central to Istio's approach and allows the application itself to remain agnostic of the underlying network features.
HashiCorp Vault Agent
To handle secrets securely, Vault's sidecar agent authenticates to the Vault server and injects secrets into the application container via shared volume or environment variables.
Fluent Bit or Logstash Sidecars
These are used for shipping logs from application containers to centralized systems like Elasticsearch or Loki, without requiring logging code in the main service.
When to Use the Sidecar Pattern
Ideal Scenarios
You want standardized tooling across multiple services (e.g., logs, metrics, security).
Your platform uses Kubernetes, making pod co-location trivial.
You prefer infrastructure abstraction from application logic.
You operate polyglot services needing a unified interface to platform capabilities.
When to Avoid
In very small applications-overhead might outweigh the benefits.
On resource-constrained systems-sidecars multiply resource usage.
When simplicity or startup time is critical.
Best Practices
Automate Sidecar Injection
Use tools like Kubernetes Mutating Admission Webhooks or mesh-specific injectors to automate the addition of sidecars during deployment.
Limit Sidecar Responsibilities
Avoid feature bloat−each sidecar should have a clear, single responsibility to maintain modularity.
Monitor Resource Usage
Track CPU/memory usage of sidecars separately to avoid hidden bottlenecks.
Secure Communication
Use mutual TLS between sidecar and app container where sensitive data is shared.
Failover Planning
Ensure graceful degradation−apps should have fallbacks if the sidecar is temporarily unavailable.
Conclusion
The Sidecar pattern is a powerful tool for building scalable, maintainable, and consistent microservices systems. By co-locating operational features next to business services, it strikes a balance between modularity and integration.
While it's not without cost-extra containers, operational overhead-it's often a worthwhile trade-off for systems that need observability, security, and traffic control at scale.
As with any architectural decision, choose the Sidecar pattern only when its advantages align with your system's needs. Used wisely, it becomes a cornerstone of a robust, cloud-native architecture.
Java Microservices - Service Mesh Pattern
Introduction
A service mesh implements a dedicated network layer through sidecar proxies ( see Sidecar design pattern) and a control plane, managing all traffic between microservices with minimal or zero changes to application code.
Core Architecture & Key Benefits
Architecture
Data Plane − Lightweight proxies (eg., Envoy, Linkerd2 proxy) deployed alongside each service as "sidecars." They intercept and manage every request.
Control Plane − Central brain−configures proxies, enforces policies, and gathers telemetry.
Benefits
Connectivity & Traffic Management
Intelligent load balancing (round robin, EWMA, least requests)
Traffic shaping: canary, blue green deployments
Retries, timeouts, circuit breakers
Security
Enforced mutual TLS (mTLS) for inter-service encryption
Identity-based authorization (JWTs, ACLs, policies)
Observability
Distributed tracing (Jaeger, Zipkin)
Prometheus-compatible metrics, logs via Grafana
Istio vs. Linkerd: At a Glance
| Sr.No. | Feature | Istio | Linkerd |
|---|---|---|---|
| 1 | Architecture | Envoy sidecars with powerful control plane components (Pilot, Citadel...) | Lightweight Rust/Go proxy, simpler design |
| 2 | Traffic Management | Full-featured: routing, retries, fault injection, circuit breakers | Basic load balancing, retries, circuit breakers |
| 3 | Security | mTLS, JWT, fine-grained policies | mTLS by default, basic ACLs |
| 4 | Observability | Rich telemetry, pluggable integrations | Built-in dashboard, concise metrics |
| 5 | Usability | Steep learning curve, high operational overhead | Easy install, Kubernetes-native |
| 6 | Performance | Impact Notable latency/cpu overhead, though mitigated in Ambient mode | Minimal overhead, optimized proxies |
| 7 | Supported Environments | Kubernetes + VMs + multi-cloud; strong ecosystem with GCP, Azure support | Primarily Kubernetes; mesh expansion added |
Deep Dive into Istio
Feature Highlights
Advanced Traffic Management − VirtualServices, DestinationRules, fault injection
Comprehensive Security − mTLS, JWT auth, RBAC, policy enforcement
Robust Observability − Metrics, tracing, logging; integrates with Prometheus, Jaeger, Grafana, Kiali
Evolution
Istio's original Mixer-based model has been streamlined; the newer releases simplify configuration and reduce complexity.
Considerations
Complexity − Steep learning curve; requires deep understanding of proxies and control plane internals.
Resource Overhead − Higher CPU/memory usage for Envoy and Istio components.
Deep Dive into Linkerd
Feature Highlights
Simplicity − Easy install via CLI or Helm; lightweight Rust proxy
Security − Auto mTLS, SPIFFE support, basic authorization
Observability − Integrated dashboard, Prometheus metrics and tracing support
Traffic Handling − Excellent per-request load balancing via latency-based EWMA
Performance
Lower overhead than Istio; users report near-zero footprint, even at multi-cluster scale.
Multi-Environment Support
Mesh expansion now supports non-Kubernetes workloads, bridging VMs into the mesh.
Considerations
Feature Set − Less advanced traffic and policy management than Istio
Legacy Deployments − Initially didn't support VMs, though recent versions now do.
When to Use (and Not Use) a Service Mesh
Use Cases
Large-scale systems requiring secure communication, deep telemetry, and traffic control.
Multi-cluster or multi-cloud deployments with strict zero-trust policies.
Environments needing fault injection, intricate routing schemes.
Avoid If
You're running a handful of microservices in a controlled environment.
You lack in-house DevOps maturity or just want simplicity.
Performance/resource constraints outweigh the benefits.
Sidecar overhead and added latency make service meshes a significant investment−evaluate if your scenario demands it.
Best Practices for Adoption
Assess Need First− Don't assume every microservices setup requires a mesh.
Start Simple− Begin with Linkerd or lightweight mesh; grow into Istio if needed.
Gradual Rollout− Pilot with select services before wider adoption.
CI/CD Integration− Treat mesh configs as code; git versioning is essential.
Focus on Observability− Prep Prometheus/Grafana/Jaeger before mesh deployment.
Security First− Enforce mTLS from day zero; harden with RBAC and policies.
Monitor Overhead− Keep an eye on latency, CPU, and memory; consider Istio Ambient or Linkerd if overhead is problematic.
Training & Documentation− Ensure developers and SREs understand mesh concepts.
Future Trends
Sidecar-less architectures gaining traction (e.g. Istio Ambient).
Unified multi-cloud support, broader mesh expansion for non-K8s environments.
Standardization efforts (SPIFFE/SPIRE, CNI) easing adoption.
Performance optimizations, through better proxy efficiency and smarter routing.
Conclusion
Service meshes like Istio and Linkerd are powerful solutions for mature, complex microservices needs: they deliver robust traffic control, security, and observability, all while abstracting network concerns away from application code.
Istio offers rich features suited to large-scale enterprise environments, but at the cost of complexity and resource overhead.
Linkerd emphasizes simplicity, performance, and developer-friendly operations−ideal for smaller, Kubernetes-focused systems.
Java Microservices - Circuit Breaker Design Pattern
Introduction
In the microservices landscape, there are several microservices communicating with each other. What happens when one service fails? The failure can cascade, causing timeouts and system-wide outages. To prevent this, we need a way to fail fast and recover gracefully.
The Circuit Breaker pattern solves this. It guards against repeated failures by detecting when a service is failing and short-circuiting further calls until the service recovers.
What Is the Circuit Breaker Pattern?
At its core, a Circuit Breaker monitors service calls and intervenes when failures cross a threshold. It wraps remote calls and determines whether to allow them, fail fast, or attempt recovery.
The Three States
Closed − Calls pass through normally. Failures are counted.
Open − Calls are blocked immediately. This prevents overloading a failing service.
Half-Open − A limited number of test calls are allowed to check if the service has recovered.
If the remote service fails consistently, the breaker opens and returns fallback responses. Once enough time has passed, it enters half-open mode to test service health.
Why Circuit Breakers Matter in Microservices
Prevent Cascading Failures
Without circuit breakers, a single failing service could overload other services waiting for timeouts, leading to thread starvation and system collapse.
Improve Latency
By failing fast, you avoid wasting time on doomed requests. This reduces latency for end users and keeps service queues short.
Enhance Fault Isolation
Circuit breakers contain failures within a service boundary, ensuring that localized issues don't become global ones.
Enable Self-Healing
They also support recovery strategies like retrying, backoff, or fallbacks−giving systems a chance to recover gracefully.
Real-World Use Cases
Payment Gateway Integration
If a third-party payment API becomes unreliable, the circuit breaker can prevent repeated attempts, return cached or offline payment instructions, and resume only when the gateway recovers.
Search or Recommendation Services
These non-critical features can be bypassed with graceful degradation when dependent services fail.
Remote Configuration or Feature Flags
If the config server goes down, services can use cached settings instead of timing out repeatedly.
Implementation Approaches
Circuit Breakers can be implemented in code, libraries, or infrastructure. Each approach offers trade-offs.
Library-Based Circuit Breakers
These live inside your service code. Popular options −
Resilience4j
Lightweight, functional API
Separate modules: retry, rate limiter, time limiter, bulkhead
Easy to use with Spring Boot
CircuitBreakerConfig config = CircuitBreakerConfig.custom() .failureRateThreshold(50) .waitDurationInOpenState(Duration.ofSeconds(10)) .build();
Polly (for .NET)
Fluent syntax
Supports retries, timeouts, fallback, and circuit breakers
Service Mesh (Infrastructure-Based)
Circuit breaking can be handled at the infrastructure level using proxies.
Istio + Envoy
Configure circuit breakers via DestinationRule
Controls max concurrent requests, timeouts, and outlier detection
spec:
trafficPolicy:
connectionPool:
http:
http1MaxPendingRequests: 1
maxRequestsPerConnection: 1
outlierDetection:
consecutiveErrors: 5
interval: 10s
baseEjectionTime: 30s
Benefit− No changes to application code. Works for any language.
Circuit Breaker vs Related Patterns
| Sr.No. | Pattern | Purpose | Difference |
|---|---|---|---|
| 1 | Retry | Automatically retries failed operations | Can work with Circuit Breaker to avoid premature failures |
| 2 | Timeouts | Set a limit for how long to wait | Circuit Breaker uses timeouts as one failure condition |
| 3 | Bulkhead | Isolates resources like threads/pools | Circuit Breaker halts all calls temporarily |
| 4 | Fallback | Provides a default response or behavior | Often used inside circuit breakers |
These patterns work best in combination, not in isolation.
Best Practices
Set Realistic Thresholds
Avoid overreacting to transient failures. Example −
Failure rate threshold: 50%
Minimum request volume: 10 requests
Open state duration: 10–30 seconds
Use Fallbacks Wisely
Fallbacks shouldn't mask critical issues. For mission-critical services (like payment processing), a hard fail may be safer.
Monitor and Tune
Track −
Circuit breaker open/close metrics
Failure rates
Latency trends
Use tools like Prometheus + Grafana, Resilience4j's built-in metrics, or Istio dashboards.
Combine with Retries and Backoff
Retries with exponential backoff + circuit breakers offer controlled failure recovery. But beware of retry storms.
Isolate Circuits per Dependency
Use separate breakers for each downstream service. Don't lump all calls into one.
Common Pitfalls to Avoid
Overly Aggressive Timeouts− May trigger unnecessary failures.
Global Circuit Breaker− A failure in one service blocks unrelated services.
No Observability− Without metrics, you're flying blind.
Retry Inside Circuit− Retrying failed calls during open state defeats the purpose.
Ignoring Fallback Failures− Fallbacks should be tested and monitored too.
Real-World Case Studies
Netflix
Netflix pioneered Hystrix to protect its massive microservices system. Circuit breakers ensured that even when recommendation engines failed, playback continued. Hystrix has now been replaced by Resilience4j.
Alibaba
Uses circuit breakers as part of Sentinel (their open-source traffic protection system) to manage massive distributed loads during peak sales events.
Amazon
Implements aggressive timeouts and fail-fast policies for all external calls-ensuring that one slow microservice doesn't degrade the entire customer experience
When Not to Use a Circuit Breaker
While circuit breakers are powerful, they're not for every situation.
Don't use when
The cost of a false open state is high (e.g., life-support systems).
Dependencies are already highly reliable and low-latency.
You lack enough traffic to trigger meaningful stats.
In those cases, consider timeouts, retries, or graceful degradation without a full circuit breaker setup.
The Future of Circuit Breakers
As systems evolve toward serverless, event-driven, or edge computing architectures, circuit breaker concepts are adapting too −
Service Mesh Circuit Breaking − Becoming default in Kubernetes environments.
Adaptive Breakers − Using machine learning to tune thresholds dynamically.
Serverless Timeouts − Implicit circuit-breaker behavior via time-bound execution (e.g., AWS Lambda).
Tooling is also improving−
Resilience4j supports Grafana dashboards
Istio and Linkerd provide declarative breaker policies
AWS App Mesh, Google Anthos integrate breaker settings out of the box
Conclusion
The Circuit Breaker pattern is an essential tool for building resilient microservices. It protects your system from cascading failures, improves user experience during downtimes, and enables faster recovery from transient issues.
But it's not a silver bullet. Circuit breakers require thoughtful configuration, ongoing monitoring, and strategic fallback design. Done right, they turn fragile architectures into robust, self-healing systems.
Bottom line
If you build microservices, don't wait for a system-wide failure to discover you needed a circuit breaker. Make it part of your architecture from day one.
Java Microservices - Distributed Tracing
Introduction
Distributed Tracing - a design pattern and observability toolset that gives you visibility into how a request flows through your microservices landscape. It helps you identify bottlenecks, understand dependencies, and debug production issues.
This article breaks down the concept of distributed tracing, how it works, why it matters, and how to implement it using tools like OpenTelemetry, Jaeger, and Zipkin.
What Is Distributed Tracing?
Distributed Tracing tracks the journey of a single request (or transaction) as it moves through different components of a distributed system.
Where traditional logs and metrics offer fragmented data, tracing links those fragments into a single, end-to-end view−across processes, containers, services, and even infrastructure boundaries.
Key Concepts
Trace − The full journey of a request across the system.
Span − A single operation within that journey (e.g., a service call).
Context propagation − Metadata (trace ID, span ID) passed between services to maintain trace continuity.
Every trace consists of multiple spans, with parent-child relationships reflecting the call hierarchy.
Why Distributed Tracing Matters
Visibility Across Services
In a monolith, you can debug with logs. In microservices, each service might have its own log format, tool, or team. Tracing ties them together.
Faster Root Cause Analysis
Without tracing, debugging requires stitching logs from multiple services. Tracing provides a unified view to identify latency spikes, retry loops, and error origins.
Dependency Mapping
Distributed tracing builds dynamic service dependency graphs, revealing which services interact most-and where failures cascade.
Performance Optimization
Trace timelines help identify slow database queries, overloaded services, or redundant calls.
Anatomy of a Trace
A typical distributed trace includes −
Trace ID: 4fd0c3a2d2b3
Span 1: HTTP Ingress (API Gateway) [Root]
|-Span 2: Auth Service
|-Span 3: User DB Query
|-Span 4: Payment Service
|-Span 5: Payment Provider API
Each span includes−
Span ID
Parent Span ID
Start/end timestamps
Tags (e.g., HTTP status, method, URL)
Logs/events (e.g., retries, exceptions)
Traces can be visualized as timelines (Gantt-style) or call trees (hierarchical views).
Context Propagation: The Heart of Tracing
To track a request across services, trace context must be passed along HTTP headers or message metadata.
Common propagation formats −
traceparent and tracestate (W3C standard)
X-B3-* headers (Zipkin)
uber-trace-id (Jaeger)
Modern tracing frameworks automatically handle context propagation across threads, services, and network boundaries-provided you instrument your code properly.
Implementing Distributed Tracing
Instrument Your Code
You need to wrap code around HTTP clients, databases, and messaging libraries to create spans.
Use libraries that support automatic instrumentation (e.g., OpenTelemetry SDKs) to minimize effort.
Collect Traces
Traces are collected by agents/exporters and sent to a backend like−
Jaeger
Zipkin
Tempo
AWS X-Ray
Datadog/APM vendors
Visualize Traces
Use UIs to explore traces by −
Duration
Service
Error status
Tags (e.g., user ID, order ID)
This is invaluable during outages or latency investigations.
Popular Distributed Tracing Tools
OpenTelemetry
The CNCF (Cloud Native Computing Foundation)- backed, vendor-neutral standard for telemetry (traces, metrics, logs).
Unified APIs and SDKs for many languages
Collector for data processing and exporting
Pluggable to any backend (Jaeger, Prometheus, etc.)
Replaces OpenTracing and OpenCensus
Jaeger
CNCF (Cloud Native Computing Foundation) project from Uber
Works with OpenTelemetry Collector
Provides trace search, visualization, and dependency graph
Zipkin
Twitter-originated, lightweight
Focused on speed and simplicity
Integrates well with Spring Cloud (e.g., Sleuth)
Datadog / New Relic / Honeycomb
Commercial solutions with advanced analytics
Host trace collection and visualization
Good for organizations that need managed observability
Tracing in Service Meshes
If you're using a service mesh like Istio or Linkerd, tracing can be implemented at the proxy level.
Sidecars like Envoy intercept all traffic
Automatically generate spans for inbound/outbound calls
Require minimal code changes
Best Practices for Distributed Tracing
Start With Critical Paths
Instrument high-value services first (e.g., login, checkout). Then expand.
Use Consistent Naming
Standardize span names and tags. Use domain-specific terms (e.g., checkout.payment.charge).
Add Business Metadata
Inject useful tags like−
User ID
Order ID
Region
Customer type
This makes searching and filtering traces easier.
Correlate Logs and Metrics
Use trace IDs in logs and metrics to connect everything. Many observability stacks (Grafana, Splunk, ELK) support this.
Pitfalls to Avoid
No Trace Context Propagation
If you forget to forward trace headers, traces get fragmented. Always pass them across−
HTTP requests
Messaging queues
Async jobs
Over-Instrumentation
Avoid creating spans for every trivial operation. Focus on critical I/O, logic paths, and inter-service calls.
Unbounded Trace Data
Sampling helps−don't trace every request in production. Use−
Random sampling (e.g., 10%)
Tail-based sampling (e.g., retain slowest traces)
Ignoring Storage and Privacy
Trace data can include PII or sensitive metadata. Sanitize and manage retention policies.
Real-World Example
Let's walk through a real use case−
Scenario: E-Commerce Checkout
User Request hits /checkout
Checkout Service calls−
Auth Service → span created
Cart Service → span created
Payment Service → span created
Calls external API (e.g., Stripe) → span created
All spans are linked under a common trace ID
Observability Gains−
Detect a 600ms delay in Payment Service
Visualize retries in Stripe API
See which services are dependent on Cart
This helps the team diagnose and optimize the payment flow efficiently.
Future of Distributed Tracing
The tracing ecosystem is evolving rapidly.
OpenTelemetry is becoming the de facto standard
Trace + Logs + Metrics correlation is improving
AI-powered root cause analysis is emerging in observability platforms
Edge-to-database tracing (from browser/app to backend) is now possible with full-stack instrumentation
Soon, distributed tracing will be a core pillar of production observability-on par with logs and metrics.
Conclusion
Distributed tracing isn't just a debugging tool-it's an essential pattern for understanding and managing complex microservices systems.
It provides−
End-to-end visibility
Faster incident response
Smarter performance tuning
Greater team alignment
Whether you're operating five services or five hundred, tracing transforms your blind spots into actionable insights.
Start small. Choose an open standard like OpenTelemetry. Instrument a critical path. Set up Jaeger or Zipkin.
Then trace everything that matters.
Java Microservices - Control Loop Design Pattern
What Is the Control Loop Pattern?
The Control Loop pattern is a microservice design approach in which a component (called a controller) continuously−
Observes the system state
Compares it with the desired state
Takes actions to bring the system closer to that desired state
This loop continues indefinitely, enabling real-time responsiveness and autonomous system behavior.
Key Steps
Sense− Collect metrics, events, or resource states
Analyze− Compare current state vs. desired state
Act− Apply changes to correct or improve the system
Anatomy of a Control Loop in Microservices
Let's break down the core components of a control loop.
Desired State
The target configuration or behavior you want the system to achieve. Defined declaratively (e.g., "5 running pods", "CPU < 60%").
Observed State
The actual, real-time condition of the system. Pulled from metrics, logs, APIs, or status reports.
Reconciler / Controller
A service or component that evaluates the gap between desired and observed state, and takes corrective action.
Actuator
The mechanism that enforces the change−such as calling an API, modifying a config, or restarting a service.
Real-World Examples of Control Loop
Kubernetes Controllers
ReplicaSet Controller − Ensures the number of pod replicas matches the deployment spec
Horizontal Pod Autoscaler (HPA) − Adjusts pod count based on CPU/memory usage
Node Controller − Detects and evicts unhealthy nodes
Each of these runs a continuous loop of: observe → compare → act.
Service Mesh Control Planes
Istio's control plane (e.g., Pilot) pushes configuration to Envoy proxies. It monitors changes and ensures proxies are synchronized.
Chaos Engineering Tools
Tools like Gremlin or LitmusChaos apply random failures, and custom controllers observe system responses to ensure reliability goals are met.
Autoscalers and Load Shapers
Custom autoscalers read Prometheus metrics and adjust resources dynamically−following the control loop logic.
Why Use Control Loops?
Autonomy
Systems fix themselves instead of requiring manual intervention.
Resilience
The loop reacts to failure and maintains equilibrium−especially in volatile environments.
Continuous Optimization
Loops can be tuned to optimize latency, resource usage, availability, or cost-all in real time.
Declarative Management
Developers define what the system should look like; the controller ensures how it gets there.
Scalability
Control loops work well in distributed, multi-node systems because they're decentralized and modular.
Design Patterns That Leverage Control Loops
The Control Loop pattern can be implemented in various forms −
Reconciler Pattern (Kubernetes)
A controller watches for changes and continuously reconciles actual and desired states. Failures are transient-if the loop fails once, it'll try again.
Operator Pattern
An extension of the reconciler, where domain-specific controllers manage complex applications (e.g., databases, Kafka, ML pipelines).
Example− A Kafka Operator ensures partitions and replication factors match cluster specs.
Monitor-Analyze-Plan-Execute (MAPE-K)
Used in autonomic computing, this variation adds planning and decision-making between analysis and execution.
Building a Custom Control Loop
Let's walk through building a simple control loop microservice−
Use Case − Ensure 3 instances of a worker service are always running.
Steps
Observe − Query the current number of running worker pods from Kubernetes API
Compare − If current ≠ desired, trigger scale-up or scale-down
Act − Call the Kubernetes API to adjust the replica count
Repeat − Sleep for N seconds, then repeat the loop
Pseudo-code
while True:
current = get_running_instances("worker")
desired = 3
if current < desired:
scale_up("worker", desired - current)
elif current > desired:
scale_down("worker", current - desired)
sleep(10)
Challenges and Anti-Patterns
Oscillation
If the loop reacts too aggressively, it can cause ping-pong behavior (e.g., rapid scaling up and down).
Solution− Add hysteresis or cooldown periods to stabilize reactions.
Conflicting Loops
Two control loops trying to manage the same resource can fight each other.
Solution− Define clear ownership boundaries and avoid overlapping scopes.
Lag or Slow Feedback
Delayed metrics or slow sensors may result in outdated observations.
Solution− Use real-time or near-real-time telemetry (e.g., Prometheus with alert thresholds).
Lack of Idempotency
Actions must be safe to repeat. If an action fails mid-way, the next loop must be able to retry without breaking state.
Solution− Make actuation idempotent and transactional.
Best Practices for Control Loop
Design for Observability
Include metrics and logs for−
Loop frequency
Observed vs. desired values
Actions taken
Errors encountered
Use Retry with Backoff
Actions may fail due to network issues or API limits. Use exponential backoff and circuit breakers in your actuation logic.
Use Declarative Configs
Instead of hardcoding desired state, define it in YAML, JSON, or CRDs. This aligns with GitOps and infrastructure-as-code principles.
Rate-Limit Your Loops
Don't run too frequently-balance responsiveness with efficiency.
Fail Safely
If your loop malfunctions, it should degrade gracefully, log clearly, and avoid making things worse.
Future Trends
I-powered loops− Use ML models to predict system behavior and optimize decisions.
Event-driven control loops− Hybrid systems with event-driven triggers and loop-based reconciliations.
Self-tuning loops− Controllers that adjust their thresholds and reaction strength over time.
As systems become more autonomous, control loops will grow in complexity and intelligence.
Key Takeaways
Control loops run continuously to align system state with desired goals.
Kubernetes is a prime example of control-loop-driven architecture.
Design loops with stability, idempotency, and observability in mind.
Combine loops with event-driven architectures for flexibility and speed.
Java Microservices - Database per Service Pattern
Microservices architecture splits a monolith application into a set of modules, each owning a distinct business capability. But breaking up an application isn't just about code. Data must be decentralized too.
That's where the Database per Service pattern comes in. It's a foundational principle of microservices that ensures each service owns its own data, with no direct access from other services.
This article explores what this pattern is, why it matters, how to implement it correctly, and the trade-offs you need to consider.
What Is the "Database per Service" Pattern?
Definition
In this pattern, each microservice has its own private database that only it can access directly. No other service is allowed to read or write to that database.
The service is the only interface to the data. External access must go through the service's API.
Each microservice manages its own schema, storage engine, and database logic, ensuring data encapsulation and independence.
Why It Matters in Microservices
Service Independence
If services share a database, they're tightly coupled. Schema changes or performance issues in one service can impact others. Owning the database lets each service evolve independently.
Scalability
With separate databases, each service can scale independently−both in terms of compute and storage.
Polyglot Persistence
Different services may benefit from different database technologies (SQL, NoSQL, graph, time-series). This pattern allows each team to choose the best fit.
Security and Data Isolation
Data boundaries align with service boundaries. Only the owning service can enforce access rules, reducing accidental data leaks.
Anatomy of a Database-per-Service System
Consider an e-commerce application split into−
User Service → PostgreSQL
Order Service → MySQL
Catalog Service → MongoDB
Shipping Service → Cassandra
Each service −
Connects only to its own database
Exposes APIs for other services to access data
Can be deployed, versioned, and migrated independently
Advantages of This Pattern
Loose Coupling Between Services
Without shared databases, changes to a schema or table won't ripple through other teams' services.
Autonomy for Development Teams
Each team can manage their database as they see fit-indexing, scaling, backups, migration strategy, etc.
Improved Availability and Fault Isolation
A failure in one database or service doesn't bring down the entire application.
Better Alignment with Domain-Driven Design
The data model closely follows the service's domain logic. Bounded contexts stay intact.
Technology Freedom
One service can use PostgreSQL for relational consistency, while another uses MongoDB for document flexibility.
Trade-Offs and Challenges
Despite its benefits, this pattern brings complexity. Here's what to watch for−
Data Duplication
To avoid cross-service DB access, services may copy data between each other (e.g., customer profile info). This leads to duplication and potential staleness.
Distributed Transactions
ACID guarantees across multiple services become difficult. Traditional distributed transactions (e.g., two-phase commit) are complex and fragile.
Solution− Use eventual consistency and patterns like Saga or event-driven workflows.
Querying Across Services
You can't run a JOIN across services. To answer complex queries (e.g., "Show all orders with customer names"), you need to aggregate via APIs or maintain pre-joined views in a read model.
Data Governance and Ownership Confusion
Who owns shared data like customer addresses or user profiles? Clear domain boundaries and data contracts are critical.
Increased Operational Overhead
More databases mean more infrastructure to manage, secure, monitor, and back up.
Patterns That Support Database per Service
API Composition
Build a service that aggregates data by calling multiple microservices in parallel.
Use case− Building a UI that needs customer info, order status, and shipping location.
[Client] → [Aggregator API] → [User + Order + Shipping services]
Pros − Fast, decoupled
Cons − Adds latency, complexity
CQRS (Command Query Responsibility Segregation)
Separate the write model (domain services and their DBs) from the read model (precomputed views or projections).
Use case− A dashboard needing rich, joined data that's hard to compute at runtime.
Event Sourcing / Change Data Capture
Use event logs or CDC tools to publish changes between services asynchronously.
Example − User Service emits "UserCreated" event → Order Service updates its local cache.
Pros − Enables eventual consistency
Cons − Adds complexity in event versioning and replay
Implementing the Pattern Effectively
Enforce Boundaries
Ensure no service accesses another's database−even read-only. Use firewall rules, credentials, and code reviews.
Define Ownership Clearly
Each piece of data should have one owner. If multiple services need the data, they should fetch or subscribe to updates from the owner.
Set Up Monitoring and Backups per DB
Each service should have its own backups, alerts, and performance metrics for their database.
Make Data Explicit in APIs
When exposing data from one service to another − add versioning, caching rules, and documentation.
When to Use (and Avoid) Database per Service
Use When
You want strong service boundaries
Services are independently deployable
Teams are autonomous and cross-functional
The system is large and will evolve over time
Avoid When
You're building a small app with a few services
The overhead of multiple databases isn't justified
All teams work closely and data changes infrequently
Real-World Examples
Uber
Uses event streams to replicate key data across services, maintaining autonomy and eventual consistency.
Amazon
Every service owns its data. Order history, cart data, user profiles-each lives in its own database. This isolation allows each team to deploy daily without fear of breaking someone else's system.
Netflix
Microservices at Netflix each own their state. For example, the recommendations engine may store its data in a graph database, while billing uses a traditional RDBMS.
Future Trends and Technologies
Distributed SQL databases (e.g., CockroachDB) offer a hybrid model: logical separation, shared infra.
Change Data Capture tools (e.g., Debezium) simplify syncing between services.
Serverless databases reduce operational overhead of managing many DBs.
Data mesh concepts extend the idea of data ownership and domain alignment to analytics platforms.
Key Takeaways
Don't share databases across services. Share data via APIs or events.
Expect duplication and design for it.
Choose the right tools for versioning, syncing, and querying.
Make ownership explicit−every data field should have a responsible service.
Java Microservices - Bulkhead Pattern
What Is the Bulkhead Pattern?
The Bulkhead pattern isolates parts of an application-services, consumers, or workloads-so that if one fails or becomes overloaded, it doesn't bring down anything else. In microservices, this means partitioning resources-like threads, memory, connection pools, or containers-per service or client to limit cascading failures.
Why Bulkheads Matter
Resilience to Cascading Failures
Without bulkheads, a bottleneck in one service-say Service A-can starve Service B of resources if they share the same pool (threads, connections), thereby triggering broad system failure.
Isolation from "Noisy Neighbors"
In shared environments, one overloaded service can hog CPU, memory, or DB connections, harming unrelated processes. Bulkheads restrict such noisy neighbors.
QoS and SLA Guarantees
By separating resource pools, you can prioritize critical workloads (e.g., payments) over non critical ones (e.g., analytics), maintaining service levels even under stress.
Elements of Bulkhead Design
What to Isolate
Thread pools per downstream service or workload (e.g., database, external API).
Connection pools to avoid sharing across different service calls.
Containers or processes with dedicated resource quotas.
Queues in asynchronous setups, often partitioned per message type or tenant.
Granularity and Boundaries
Service-level− allocate distinct pools per dependency.
Consumer-level− separate pools for different request sources.
Priority-based− critical workloads get their own reserved capacity.
How to Implement Bulkheads
In-Process with Libraries
Use libraries like Resilience4j for thread/semaphore isolation.
Example – Spring Boot + Resilience4j
application.yml snippet−
resilience4j.bulkhead:
instances:
orderServiceBulkhead:
maxConcurrentCalls: 5
maxWaitDuration: 10ms
Annotate−
@Bulkhead(name="orderServiceBulkhead", fallbackMethod="fallbackOrder")
@GetMapping("/orders/{id}")
public Order getOrder(...) {...}
Requests beyond 5 max out, triggering fallbackOrder()-services fail fast, not slow down.
Container Level Bulkheads
In Kubernetes, isolate services with resource limits−
resources:
requests:
cpu: "250m"; memory: "64Mi"
limits:
cpu: "1"; memory: "128Mi"
This prevents one service from exhausting cluster-wide compute.
Queue Level Partitioning
Each queue gets its own consumer group-throttles and isolation ensure error in one queue doesn't stall others.
Bulkhead in a Resilience Strategy
Combine 'bulkhead' with these patterns −
Circuit Breaker− prevent wasteful calls to unhealthy services.
Timeouts & Retries− bound resource usage and avoid blocking.
Fallbacks− graceful degradation when capacity is exhausted.
Together, they form a fault tolerant resilience pattern suite.
Observability & Monitoring
Essential for managing bulkheads−
Metrics− track thread/connection pool utilization. Tools: Resilience4j metrics, Actuator, Micrometer.
Alerts− notify when thread pool saturation or pool rejection counts spike.
Dashboards− track utilization and errors across bulkheads.
Monitoring ensures isolation works but also alerts when partitions starve or underperform.
Best Practices & Trade Offs
Tune Limits Carefully
Too low → unnecessary failures. Too high → isolation fails. Use production telemetry to guide.
Right Granularity
Partition per dependency is often enough. Too granular → complexity, underutilization.
Avoid Blocking Calls Across Bulkheads
Synchronous, cross bulkhead calls invert the pattern and risk deadlock.
Combine with Other Patterns
Bulkhead alone isn't enough-link it with circuit breakers, retries, and fallbacks for robust resilience.
Pitfalls & Anti-Patterns
Shared Backends
If multiple services share a DB connection pool, thread starvation still cascades.
Fan-out Synchronous Calls
Calling many downstream services in parallel within same pool breaks bulkhead benefits.
No Observability
Unseen saturation or failed fallbacks break trust. Monitor per bulkhead.
Over-Isolation
Too many tiny pools waste resources and complicate management−balance is key.
Neglecting Graceful Degradation
Fallbacks should provide degraded service instead of hard failures.
Real World Case Studies
Large Scale Deployments
Cloud providers like AWS Lambda inherently partition resource allocations per function-bulkheads by default.
E Commerce Services
Scenario− Order service, payment service, user service share thread pools.
Problem− Slow payment gateway exhausts all threads.
Solution− Apply bulkheads: each service gets its pool; payment slowdown fails over its own pool; order service remains healthy.
Sample Implementation in Java
@Configuration
public class BulkheadConfig {
@Bean
public ThreadPoolBulkheadRegistry bulkheadRegistry() {
BulkheadConfig config = BulkheadConfig.custom()
.maxConcurrentCalls(10)
.maxWaitDuration(Duration.ofMillis(50))
.build();
return ThreadPoolBulkheadRegistry.of(config);
}
}
@Service
public class ApiGateway {
private final ThreadPoolBulkhead paymentsBulkhead;
private final ThreadPoolBulkhead ordersBulkhead;
private final RestTemplate rest;
public ApiGateway(ThreadPoolBulkheadRegistry reg, RestTemplate rest) {
this.paymentsBulkhead = reg.bulkhead("payments");
this.ordersBulkhead = reg.bulkhead("orders");
this.rest = rest;
}
public CompletableFuture<Response> callPayments(Request req) {
return Bulkhead.decorateFuture(paymentsBulkhead,
() -> CompletableFuture.supplyAsync(() -> rest.getForObject(...))
).get();
}
public CompletableFuture<Response> callOrders(Request req) {
return Bulkhead.decorateFuture(ordersBulkhead, ...).get();
}
}
Each call is boxed in a future wrapped by its own bulkhead pool and will fail fast if saturated.
Bulkheads at Scale
Kubernetes− Separate deployments or pods per service, with CPU/memory quotas. For multi tenant systems, consider per-tenant namespaces with quotas.
Service Mesh + Sidecars− Implement per-route bulkheads within Envoy/Istio sidecars to offload isolation from application code.
Federated Bulkheads− In cell-based architectures, each cell provides its own bulkheads and remains isolated from failures in other cells.
When Bulkhead Isn't the Right Fit
Low concurrency, single workloads− Bulkheads add overhead where none is needed.
High-overhead vs ROI− Small systems can over-engineer−extra pools or containers may not justify the complexity.
Poorly defined boundaries− Without service/workload segregation, isolation can't be applied effectively.
FAQs
Q: Bulkhead vs Circuit Breaker: which first?
Use bulkheads to prevent resource exhaustion; use circuit breakers to stop calls to failing actors. Together, they function synergistically.
Q: How do I size pools?
Start small, monitor saturation, grow until failure rate/latency stays below thresholds.
Q: Bulkheads vs rate-limiting?
Rate limiting controls request entry, while bulkheads govern resource isolation internally. Use both for holistic resilience.
Q: How to monitor bulkheads?
Capture metrics: active/rejected calls, queue size, latency. Tools: Resilience4j's metrics + Prometheus + Grafana.
Summary
The Bulkhead pattern is foundational for resilient microservice architecture. By isolating resources−threads, connections, compute−per service, workload, or tenant, it prevents failures in one part from bringing down the entire system. Properly combined with circuit breakers, timeouts, retries, and fallback strategies, bulkheads strengthen production robustness. Real-world systems like AWS Lambda, Netflix, and large-scale Kubernetes clusters rely on these principles. However, bulkheads come with overhead, so balance isolation with efficiency for best results.
Java Microservices - Health Check API
Introduction
In a microservices architecture, we have to make sure each service instance can handle requests. Services might be up (healthy). They may also be down for unknown reason. Without detection, unhealthy services can still receive traffic, degrade performance, or fail unpredictably. This is where the Health Check API pattern comes in: a dedicated HTTP endpoint (e.g., GET /health) that actively verifies service viability. Infrastructure (Load Balancers, orchestrators) and monitoring tools use it to identify healthy instances-and take necessary action when they aren't.
Why You Need a Health Check API
Traffic Control
Load balancers and service registries rely on health status to stop routing to unhealthy instances.
Automated Monitoring & Alerts
Monitoring microservices poll health-check endpoints to trigger alerts or spin up new containers when services fail.
Deployment Safety
Health-checks guard against premature traffic to newly deployed instances that haven't fully initialized.
Anatomy of a Health Check API
Endpoint URL
Common patterns−
/health − general status
/health/live or /healthz − liveness (is the process alive?)
/health/ready − readiness (can serve requests?
/health/started − startup (fully initialized) (tutorialspoint.com, openliberty.io)
HTTP Method & Status Codes
Use GET
200 OK if healthy; 503 Service Unavailable (or 500) if unhealthy
Avoid caching− include headers like Cache-Control: no-cache
Payload Structure
A lightweight JSON response listing each check and its result
Example
{
"status": "UP",
"checks": [
{ "name": "db", "status": "UP", "responseTimeMs": 34 },
{ "name": "cache", "status": "DOWN", "error": "ConnectionTimeout" }
]
}
What to Check
Divide checks into −
Process Health
Is the service running?
Is the event loop or thread pool responsive?
Resource Health
Disk space, CPU, memory, thread availability.
Dependencies
Databases, caches, messaging systems, external APIs.
Ping downstream services or open DB connections.
Application Logic
Basic app-level operations, e.g., can user login, is config valid.
Best practice− Keep individual checks fast and non-blocking.
Types of Health Checks
Liveness
Simple− is the service process alive?
Used by Kubernetes to restart frozen or crashed containers.
Readiness
Can the service respond to traffic?
Checks dependency availability, connection pools, and app readiness.
Prevents routing to incompletely initialized services.
Startup
Determines when the service is fully initialized.
Prevents readiness/liveness failures during boot.
Composite
Aggregate liveness and readiness for simplified monitoring.
Implementation Strategies
Frameworks & Tooling
Spring Boot Actuator (/actuator/health)
MicroProfile Health for Java− /health, /health/live, /health/ready
Open Liberty built-in health support
Custom Implementation
Set up REST endpoints; run checks with timeout and return aggregated JSON & code
Use circuit breakers or caching for expensive dependency checks.
Integration with Infrastructure
Deploy startup, liveness, readiness URLs to Kubernetes, AWS ALB, Consul, Istio
Configure polling intervals and thresholds
Best Practices
Keep It Lean
Avoid overly broad, slow checks
Load balancers need quick binary decisions.
Automate & Monitor
Poll health endpoints frequently (e.g. every 30 seconds)
Set alerts on app status or check failure
Pitfalls to Avoid
Confusing with Ping− A simple ping says nothing about deeper dependencies.
Heavy Checks in Liveness− Overburdening liveness checks can slow restarts.
Caching Responses− Health endpoints must reflect real-time state.
Insufficient Timeout− Health endpoint shouldn't hang on slow resources.
Unprotected Endpoints− Exposes system details−secure access.
Unnamed Checks− Use descriptive names and timestamps in responses.
Polling Too Infrequently− Hourly checks may miss rapid failures.
Code Samples
Spring Boot + Actuator
In you Spring boot application, in the pom.xml file, add the following dependency−
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> <version>3.5.3</version> </dependency>
In your, application.yml, add the following snippet−
management:
endpoints:
web:
exposure:
include: health,info
health:
db:
enabled: true
After running the application, go to: http://localhost:8080/actuator to see metrics of the application.
Infrastructure Integration
Kubernetes
livenessProbe− /health/live restarts dead containers
readinessProbe− /health/ready gates traffic until healthy
Cloud Load Balancers & Service Meshes
Use health endpoints for routing decisions
API Gateways (e.g. APISIX)
Performs active and passive health checks.
Monitoring & Alerting
Tools like Prometheus can scrape health endpoints
Send alerts on status changes
Real World Patterns
Banking Scenario
Login, transfer, billing microservices each expose health-checks. If a transfer service fails, routing shifts, alerts fire, auto recovery kicks in.
Container Ecosystem
Two-tier health-check strategy−
Liveness probe = fast ping
Readiness probe = full dependency checks.
Health Check in Observability
The Health Check API is part of a broader observability stack−
Logs Distributed tracing Metrics Exception tracking
Ideally, health endpoints feed into dashboards, triggers, and alert systems to detect anomalies early.
When Health Check Isn't Enough
If your system relies on caching, message queues, bulk operations, or multi-step transactions, deeper observability is needed-like distributed tracing, APM, and golden-path tests-but health-checks remain a crucial first line.
Summary
Health Check API provides real-time insight into service availability.
Supports traffic routing, orchestration, and alerting.
Separate liveness/readiness/startup endpoints.
Ensure lightweight, fast, secure, and well-logged checks.
Avoid caching, overloading, and slow feedback.
Combine with broader observability tools for maximum resilience.
The Health Check API may appear simple, but it's foundational. It underpins all upstream systems−load balancers, orchestrators, and alert platforms−empowering autonomous, resilient microservice ecosystems. When done right, it significantly enhances reliability and maintainability.
Java Microservices - Retry Pattern
Introduction
In distributed systems and microservices, network failures, timeouts, and temporary faults are common. These failures are often temporary and may succeed on subsequent attempts. The Retry Pattern is a resilience technique where a failed request is automatically retried after a brief delay before finally giving up.
This pattern significantly increases the fault tolerance of microservices by allowing them to recover from temporary issues without immediate failure.
Motivation and Problem Statement
Let's consider a real-world example−
A payment microservice calls a third-party payment gateway API. Occasionally, the request fails due to−
Temporary network issues
DNS lookup failure
Gateway throttling
If the service fails outright, it may disrupt customer experience. Instead, if it retries the request a few times, the operation could succeed on the second or third attempt, improving reliability.
Key Challenges
Unpredictable failures in remote services
Overreaction to minor or short-lived glitches
Impact on user experience and system stability
When and Where to Apply
Use the Retry Pattern when −
Failures are transient and recoverable (e.g., timeouts, 5xx errors, temporary unavailability)
The operation is idempotent (i.e., calling it multiple times won't corrupt data or cause unwanted side effects)
The remote system is well-known and typically stable
Avoid retries when −
The failure is permanent (e.g., 404 Not Found, 401 Unauthorized)
The call is non-idempotent (e.g., money transfer or email sending)
Retry may flood an already overloaded system
Core Concepts and Principles
Retry Policy
A retry policy defines how retry attempts are made. Key parameters −
Max retries − How many times to retry (e.g., 3 attempts)
Delay − Time between retries (e.g., 200ms)
Backoff strategy − Fixed, exponential, or randomized
Retry on − Specific exceptions or HTTP statuses
Backoff Strategy
Fixed Delay − Wait a constant time between retries
Exponential Backoff − Delay increases exponentially
Exponential Backoff with Jitter − Adds randomness to avoid retry storms
Design Considerations
When designing a retry mechanism −
Ensure idempotency
Set timeouts on retries to avoid hanging requests
Log each retry attempt
Use circuit breaker in conjunction to avoid retrying during complete outages
Implement fallbacks for graceful degradation
Retry Diagram (described in text)
A retry loop can be illustrated as−
Request → Failure → Retry → Failure → Retry → Give up → Fallback/Error
Implementation Strategies
Strategy 1 − Manual Retry Logic
A developer can wrap method calls in a loop with sleep/delay and exception handling.
int maxAttempts = 3;
int attempt = 0;
while (attempt < maxAttempts) {
try {
callExternalService();
break;
} catch (Exception e) {
attempt++;
Thread.sleep(200); // Delay before retry
}
}
Strategy 2 − Framework-Based Retry
Use libraries like −
Spring Retry
Resilience4j Retry
These offer declarative retry behavior with advanced configuration.
Example Implementation: Spring Boot + Resilience4j
Dependency
<dependency> <groupId>io.github.resilience4j</groupId> <artifactId>resilience4j-spring-boot3</artifactId> <version>2.0.2</version> </dependency>
Configuration (application.yml)
resilience4j.retry:
instances:
myServiceRetry:
max-attempts: 3
wait-duration: 500ms
retry-exceptions:
- java.io.IOException
Annotated Method
@Retry(name = "myServiceRetry", fallbackMethod = "fallbackMethod")
public String callExternalService() {
// Call to external API
}
Fallback Method
public String fallbackMethod(Exception e) {
return "Service temporarily unavailable";
}
Challenges and Pitfalls
Common Mistakes
Retrying non-idempotent operations
Not limiting max attempts
Retrying instantly without backoff
Not using timeouts − can lead to thread exhaustion
Cascading retries across services causing overload
Best Practices
Always limit the number of retries
Retry only on transient and known recoverable failures
Log retry attempts and metrics for observability
Prefer framework-level retries over custom code when possible
Tools and Libraries
| Sr.No. | Tool | Purpose |
|---|---|---|
| 1 | Spring Retry | Declarative retry support in Spring Boot |
| 2 | Resilience4j Retry | Lightweight, modern retry + resilience |
| 3 | Polly (.NET) | Retry handling in .NET applications |
| 4 | Retry4j | Fluent, configurable retry logic in Java |
| 5 | Backoff (Python) | Retry utilities with exponential backoff |
Java Microservices - Fallback Pattern
Introduction
In modern distributed systems like microservices architectures, remote calls between services are common. Unfortunately, these calls are prone to failure, latency due to various reasons like −
Network glitches
Service overload
Infrastructure failures
Dependency crashes
In such situations, failing fast or displaying an error is not always the best user experience. This is where the Fallback Pattern comes into play − it helps ensure graceful degradation by providing a default or alternative response when the primary service fails.
Motivation and Problem Statement
Let's imagine a simple e-commerce platform with the following services −
ProductService
InventoryService
RecommendationService
Suppose RecommendationService is down. If a customer tries to view a product, and this service doesn't respond, the user experience degrades. However, the core functionality − viewing the product − should not fail just because one non-critical component failed.
Problems Without Fallback
Entire service or API fails because a dependent service is unavailable.
Poor customer experience due to error pages.
Increased support tickets/user dissatisfaction.
Solution− Fallback
Instead of erroring out, we can provide −
Partial or best-effort responses
Static default recommendations
"Service temporarily unavailable" messages
What Is the Fallback Pattern?
The Fallback Pattern is a resiliency pattern in which a microservice automatically provides an alternative response or takes corrective action when a primary operation fails.
When and Where to Use the Fallback Pattern
Suitable Scenarios
Optional features like recommendations, personalization, or analytics
Dependency on third-party APIs
Known unstable services
Circuit breaker trips
Avoid Using When
The fallback data is misleading or risky (e.g., financial transactions)
No safe default or alternative is available
The operation is business-critical and must be retried or alerted
Fallback Pattern in Action
Imagine the following interaction −
Client → ProductService → InventoryService (Fails)
|- Fallback: Show "Inventory info not available"
Example Responses
"We're experiencing delays, please try again later."
"Recommendations are temporarily unavailable."
This keeps the user interface functional even during failures.
Design Considerations
While implementing a fallback, keep in mind−
Is the fallback accurate and safe to use?
Is the fallback temporary or a long-term solution?
Should fallback responses be logged or alerted?
How does fallback behavior affect system stability?
Real-World Use Cases
Streaming Platforms
Show default thumbnails when video metadata service is slow.
Display cached user watch history.
E-commerce
Fallback to default product recommendations when product-recommendation service is down.
Use cached stock levels when inventory service fails.
Mobile Applications
Offline fallback UI when network is unavailable
Cached results from previous sessions
Implementation − Spring Boot + Resilience4j
Step 1: Add Dependencies
<dependency> <groupId>io.github.resilience4j</groupId> <artifactId>resilience4j-spring-boot3</artifactId> <version>2.0.2</version> </dependency>
Step 2: Create a Service with Fallback
import io.github.resilience4j.circuitbreaker.annotation.CircuitBreaker;
import io.github.resilience4j.retry.annotation.Retry;
import io.github.resilience4j.timelimiter.annotation.TimeLimiter;
@Service
public class RecommendationService {
@CircuitBreaker(name = "recommendationCB", fallbackMethod = "fallbackRecommendations")
public List<String> getRecommendations(String userId) {
// Simulate API call
if (Math.random() > 0.5) {
throw new RuntimeException("Service Down");
}
return List.of("Book1", "Book2");
}
public List<String> fallbackRecommendations(String userId, Throwable t) {
// Default fallback
return List.of("Top Sellers", "Trending Now");
}
}
Configuration (Optional) ( snippet of 'application.yml')
resilience4j.circuitbreaker:
instances:
recommendationCB:
registerHealthIndicator: true
slidingWindowSize: 5
failureRateThreshold: 50
Common Mistakes and Challenges
Poor Fallback Choices
Returning misleading or outdated fallback data can break the business logic or user trust.
Overuse of Fallbacks
Fallbacks are not a substitute for fixing actual issues. Overusing them can hide systemic problems.
Lack of Monitoring
Not tracking fallback usage may lead to undetected outages.
Not Testing Fallbacks
Fallbacks need to be tested regularly under failure scenarios.
Best Practices
Design fallbacks that maintain business value without compromising data integrity.
Log fallback triggers for monitoring and alerting.
Make fallback responses idempotent and safe.
Use circuit breakers in combination to reduce load on failing services.
Tools and Frameworks
| Sr.No. | Tool | Usage |
|---|---|---|
| 1 | Resilience4j | Circuit breaker, fallback, retry, rate limiter |
| 2 | Spring Cloud Circuit Breaker | Abstraction layer for various fallback tools |
| 3 | Failsafe (Java) | Lightweight fault tolerance library |
| 4 | Polly (.NET) | Retry and fallback handling in .NET |
| 5 | Istio / Service Mesh | Fallbacks at the network layer via routing rules |
Conclusion
The Fallback Pattern is a critical tool in the microservices developer's toolbox. It helps services maintain partial functionality in the face of failure and enhances user experience, system resilience, and fault isolation.
By thoughtfully designing and testing fallback responses, developers can ensure graceful degradation and protect their systems from cascading failures.
