
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
Selected Reading
Implementing K-means clustering with SciPy by splitting random data in 3 clusters?
Yes, we can also implement a K-means clustering algorithm by splitting the random data in 3 clusters. Let us understand with the example below −
Example
#importing the required Python libraries:
import numpy as np
from numpy import vstack,array
from numpy.random import rand
from scipy.cluster.vq import whiten, kmeans, vq
from pylab import plot,show
#Random data generation:
data = vstack((rand(200,2) + array([.5,.5]),rand(150,2)))
#Normalizing the data:
data = whiten(data)
# computing K-Means with K = 3 (3 clusters)
centroids, mean_value = kmeans(data, 3)
print("Code book :<br>", centroids, "<br>")
print("Mean of Euclidean distances :", mean_value.round(4))
# mapping the centroids
clusters, _ = vq(data, centroids)
print("Cluster index :", clusters, "<br>")
#Plotting using numpy's logical indexing
plot(data[clusters==0,0],data[clusters==0,1],'ob',
data[clusters==1,0],data[clusters==1,1],'or',
data[clusters==2,0],data[clusters==2,1],'og')
plot(centroids[:,0],centroids[:,1],'sg',markersize=8)
show()
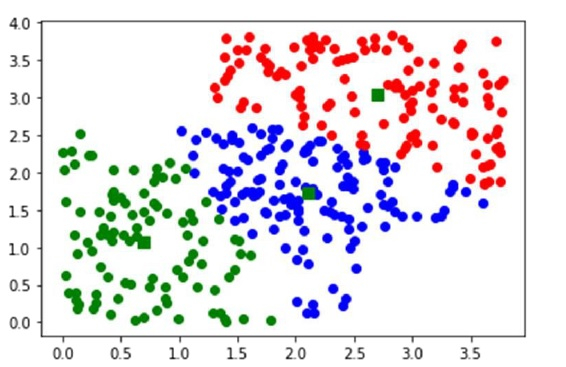
Output
Code book : [[2.10418081 1.73089074] [2.69953885 3.04708713] [0.6994524 1.06646081]] Mean of Euclidean distances : 0.7661 Cluster index : [1 1 0 1 1 1 1 0 0 0 1 1 1 1 1 0 1 1 1 0 1 1 1 1 1 0 1 0 1 0 1 0 0 0 0 0 1 0 1 1 0 1 0 0 0 0 0 1 1 1 1 1 1 1 1 0 0 1 1 1 0 1 1 0 1 0 1 1 0 0 0 1 1 0 0 0 1 0 1 0 1 1 1 0 0 1 0 1 0 1 1 0 1 1 0 1 0 0 0 1 1 1 1 1 1 0 0 1 1 1 0 0 0 1 0 0 1 1 1 0 1 1 1 1 1 0 1 0 1 1 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 1 0 1 0 1 0 1 1 0 1 0 1 1 1 1 1 0 0 0 1 1 1 1 0 1 1 1 1 0 1 0 1 1 0 0 1 1 0 0 0 1 1 0 1 1 1 1 0 1 0 0 1 1 1 1 2 2 0 0 2 2 2 2 0 2 2 2 2 2 2 2 2 0 0 0 0 2 2 2 2 2 0 2 2 2 0 2 2 0 2 0 0 2 2 0 0 0 0 2 2 2 0 2 2 0 2 0 2 0 0 2 0 2 2 0 2 2 2 0 0 2 2 2 2 2 2 0 2 2 2 2 2 0 0 2 2 2 2 0 2 2 2 0 2 0 2 0 2 2 2 0 0 0 0 2 2 2 0 2 2 2 2 2 0 2 2 2 0 2 2 0 2 1 2 0 2 2 2 0 2 2 0 0 0 2 0 0 0 0 2 2 2 0 2 2 2 2 0 2 2 2 2 0 0 2]

Updated on: 2021-12-14T08:48:44+05:30
270 Views

Advertisements