
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
How does pipelining improve performance in computer architecture?
Performance in an unpipelined processor is characterized by the cycle time and the execution time of the instructions. In the case of pipelined execution, instruction processing is interleaved in the pipeline rather than performed sequentially as in non-pipelined processors. Therefore the concept of the execution time of instruction has no meaning, and the in-depth performance specification of a pipelined processor requires three different measures: the cycle time of the processor and the latency and repetition rate values of the instructions.
The cycle time defines the time accessible for each stage to accomplish the important operations. The cycle time of the processor is specified by the worst-case processing time of the highest stage.
Latency defines the amount of time that the result of a specific instruction takes to become accessible in the pipeline for subsequent dependent instruction. Latency is given as multiples of the cycle time.
If the latency of a particular instruction is one cycle, its result is available for a subsequent RAW-dependent instruction in the next cycle. In this case, a RAW-dependent instruction can be processed without any delay. If the latency is more than one cycle, say n-cycles an immediately following RAW-dependent instruction has to be interrupted in the pipeline for n-1 cycles.
There are two different kinds of RAW dependency such as define-use dependency and load-use dependency and there are two corresponding kinds of latencies known as define-use latency and load-use latency.
The define-use latency of instruction is the time delay occurring after decoding and issue until the result of an operating instruction becomes available in the pipeline for subsequent RAW-dependent instructions. If the value of the define-use latency is one cycle, and immediately following RAW-dependent instruction can be processed without any delay in the pipeline.
The define-use delay of instruction is the time a subsequent RAW-dependent instruction has to be interrupted in the pipeline. The define-use delay is one cycle less than the define-use latency.
The term load-use latencyload-use latency is interpreted in connection with load instructions, such as in the sequence
load r1, x; ad r5, r1, r2;
In this example, the result of the load instruction is needed as a source operand in the subsequent ad. The notion of load-use latency and load-use delay is interpreted in the same way as define-use latency and define-use delay.
The latency of an instruction being executed in parallel is determined by the execute phase of the pipeline. It can illustrate this with the FP pipeline of the PowerPC 603 which is shown in the figure.
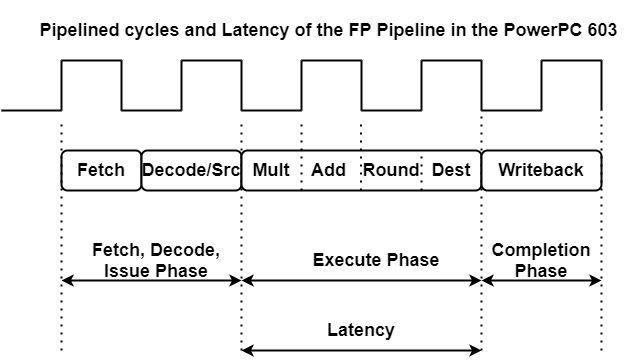
The Power PC 603 processes FP additions/subtraction or multiplication in three phases. Two cycles are needed for the instruction fetch, decode and issue phase. The subsequent execution phase takes three cycles. At the end of this phase, the result of the operation is forwarded (bypassed) to any requesting unit in the processor. Finally, in the completion phase, the result is written back into the architectural register file.

6K+ Views
