
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
Explain the evaluation of relational algebra expression(DBMS)
SQL queries are decomposed into query blocks. One query block contains a single SELECT-FROM-WHERE expression, as well as GROUP BY and HAVING clause (if any). Nested queries are split into separate query blocks.
Example
Consider an example given below −
Select lastname, firstname from employee where salary>(select max(salary) from employee where deptname =CSE ; C=(select max(salary) from employee where deptname=CSE); // inner block Select lastname, firstname from employee where salary>c; //outer block
Where C represents the result returned from the inner block.
The relation algebra for the inner block is ?max(salary) (σdname=CSE(employee))
The relation algebra for the outer blocks is Πlastname, firstname(σsalary>c(employee))
The query optimizer would then choose an execution or evaluation plan for each block.
Evaluation of relational algebra expressions
Materialized evaluation − Evaluate one operation at a time. Evaluate the expression in a bottom-up manner and stores intermediate results to temporary files.
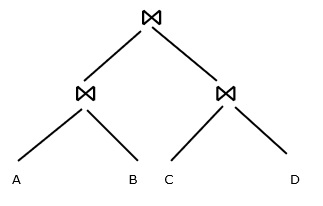
Store the result of A ? B in a temporary file.
Store the result of C ? D in a temporary file.
Finally, join the results stored in temporary files.
The overall cost=sum of costs of individual operations + cost of writing intermediate results to disk, cost of writing results to results to temporary files and reading them back is quite high.
Pipelined evaluation − Evaluate several operations simultaneously. Result of one operation is passed to the next operation. Evaluate the expression in a bottom-up manner and don’t store intermediate results to temporary files.
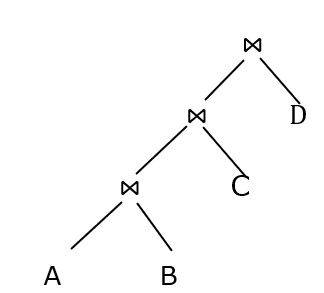
Don’t store the result of A ? B in a temporary file. Instead the result is passed directly for projection with C and so on.

12K+ Views
