
 Data Structure
Data Structure Networking
Networking RDBMS
RDBMS Operating System
Operating System Java
Java MS Excel
MS Excel iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C Programming
C Programming C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP
- Selected Reading
- UPSC IAS Exams Notes
- Developer's Best Practices
- Questions and Answers
- Effective Resume Writing
- HR Interview Questions
- Computer Glossary
- Who is Who
Explain hard reset with an example in Git
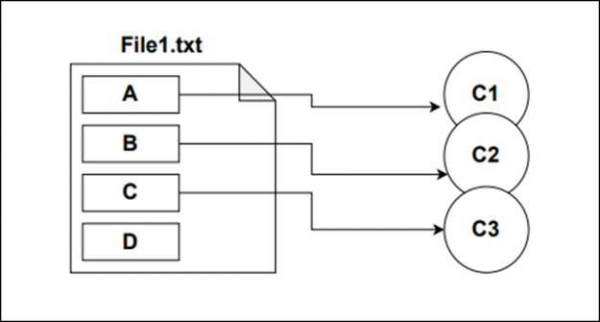
The diagram shows a file named File1.txt within the git repository. A, B, C and D represent lines that are added to the file. The diagram indicates that a commit is performed after adding each line A, B and C. c1 is the commit performed after adding line A, c2 is the commit after adding line B and C3 represents the commit after adding line C. Now add line D. This change is available in the working directory and this change is staged but yet to be committed.
Now if we perform a hard reset to move the HEAD pointer of the master branch two steps back (c1), then we will lose all the changes in the staging area and the working directory. In our case line D which is a part of the working directory will be removed.
Step 1 − Create a repository add File1.txt with content -A, commit the changes as shown
$ git init Initialized empty Git repository in E:/tut_repo/.git/ $ dell@DESKTOP-N961NR5 MINGW64 /e/tut_repo (master) $ echo A>File1.txt $ dell@DESKTOP-N961NR5 MINGW64 /e/tut_repo (master) $ git add . $ dell@DESKTOP-N961NR5 MINGW64 /e/tut_repo (master) $ git commit -m 'A' [master (root-commit) 8679e6b] A 1 file changed, 1 insertion(+) create mode 100644 File1.txt
Step 2 − Do 2 more commits with contents B and C as discussed above in diagram
$ dell@DESKTOP-N961NR5 MINGW64 /e/tut_repo (master) $ echo B>>File1.txt $ dell@DESKTOP-N961NR5 MINGW64 /e/tut_repo (master) $ cat File1.txt A B $ dell@DESKTOP-N961NR5 MINGW64 /e/tut_repo (master) $ git add . $ dell@DESKTOP-N961NR5 MINGW64 /e/tut_repo (master) $ git commit -m 'B' [master 6780ed4] B 1 file changed, 1 insertion(+) $ dell@DESKTOP-N961NR5 MINGW64 /e/tut_repo (master) $ echo C>>File1.txt $ dell@DESKTOP-N961NR5 MINGW64 /e/tut_repo (master) $ cat File1.txt A B C $ dell@DESKTOP-N961NR5 MINGW64 /e/tut_repo (master) $ git add . $ dell@DESKTOP-N961NR5 MINGW64 /e/tut_repo (master) $ git commit -m 'C' [master 287a5a1] C 1 file changed, 1 insertion(+) $ dell@DESKTOP-N961NR5 MINGW64 /e/tut_repo (master) $ git log --oneline 287a5a1 (HEAD -> master) C 6780ed4 B 8679e6b A
Step 3 − Make a change in the working directory to add content D and stage the changes.
$ dell@DESKTOP-N961NR5 MINGW64 /e/tut_repo (master) $ echo D>>File1.txt $ dell@DESKTOP-N961NR5 MINGW64 /e/tut_repo (master) $ cat File1.txt A B C D $ dell@DESKTOP-N961NR5 MINGW64 /e/tut_repo (master) $ git add . $ dell@DESKTOP-N961NR5 MINGW64 /e/tut_repo (master) $ git status -s M File1.txt
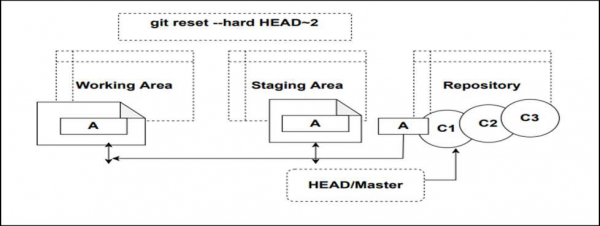
Step 4 − Now let’s reset the HEAD two commits back HEAD~2, which is our first commit. Now when we reset the commit let’s see if the changes staged are lost or not.
$ dell@DESKTOP-N961NR5 MINGW64 /e/tut_repo (master) $ git reset --hard HEAD~2 HEAD is now at 8679e6b A $ dell@DESKTOP-N961NR5 MINGW64 /e/tut_repo (master) $ cat File1.txt A $ dell@DESKTOP-N961NR5 MINGW64 /e/tut_repo (master) $ git log --oneline 8679e6b (HEAD -> master) A
When we reset the HEAD to our first commit, we observe that Git copies the snapshot of the contents of the first commit that is Content A to the staging area and the working directory. Due to this Content D that was staged before the reset is lost and overwritten by Content A. This is shown in the below diagram.

258 Views
