- Distributed Database Environments
- DDBMS - Design Strategies
- DDBMS - Distribution Transparency
- DDBMS - Database Control
- Query Optimization
- Relational Algebra Query
- Query Optimization Centralized
- Query Optimization in Distributed
- Concurrency Control
- Transaction Processing Systems
- DDBMS - Controlling Concurrency
- DDBMS - Deadlock Handling
- Failure and Recovery
- DDBMS - Replication Control
- DDBMS - Failure & Commit
- DDBMS - Database Recovery
- Distributed Commit Protocols
- Distributed DBMS Security
- Database Security & Cryptography
- Security in Distributed Databases
- Distributed DBMS Resources
- DDBMS - Quick Guide
- DDBMS - Useful Resources
- DDBMS - Discussion
Query Optimization in Distributed Systems
This chapter discusses query optimization in distributed database system.
Distributed Query Processing Architecture
In a distributed database system, processing a query comprises of optimization at both the global and the local level. The query enters the database system at the client or controlling site. Here, the user is validated, the query is checked, translated, and optimized at a global level.
The architecture can be represented as −
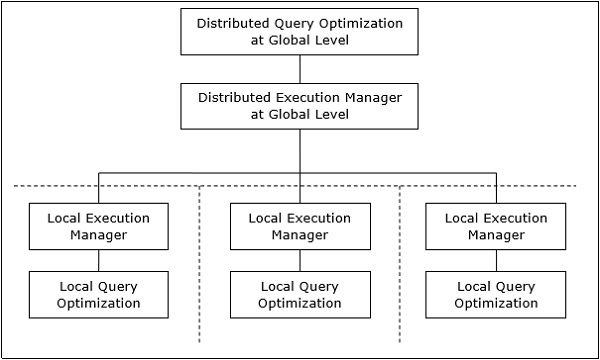
Mapping Global Queries into Local Queries
The process of mapping global queries to local ones can be realized as follows −
The tables required in a global query have fragments distributed across multiple sites. The local databases have information only about local data. The controlling site uses the global data dictionary to gather information about the distribution and reconstructs the global view from the fragments.
If there is no replication, the global optimizer runs local queries at the sites where the fragments are stored. If there is replication, the global optimizer selects the site based upon communication cost, workload, and server speed.
The global optimizer generates a distributed execution plan so that least amount of data transfer occurs across the sites. The plan states the location of the fragments, order in which query steps needs to be executed and the processes involved in transferring intermediate results.
The local queries are optimized by the local database servers. Finally, the local query results are merged together through union operation in case of horizontal fragments and join operation for vertical fragments.
For example, let us consider that the following Project schema is horizontally fragmented according to City, the cities being New Delhi, Kolkata and Hyderabad.
PROJECT
| PId | City | Department | Status |
Suppose there is a query to retrieve details of all projects whose status is Ongoing.
The global query will be &inus;
$$\sigma_{status} = {\small "ongoing"}^{(PROJECT)}$$
Query in New Delhis server will be −
$$\sigma_{status} = {\small "ongoing"}^{({NewD}_-{PROJECT})}$$
Query in Kolkatas server will be −
$$\sigma_{status} = {\small "ongoing"}^{({Kol}_-{PROJECT})}$$
Query in Hyderabads server will be −
$$\sigma_{status} = {\small "ongoing"}^{({Hyd}_-{PROJECT})}$$
In order to get the overall result, we need to union the results of the three queries as follows −
$\sigma_{status} = {\small "ongoing"}^{({NewD}_-{PROJECT})} \cup \sigma_{status} = {\small "ongoing"}^{({kol}_-{PROJECT})} \cup \sigma_{status} = {\small "ongoing"}^{({Hyd}_-{PROJECT})}$
Distributed Query Optimization
Distributed query optimization requires evaluation of a large number of query trees each of which produce the required results of a query. This is primarily due to the presence of large amount of replicated and fragmented data. Hence, the target is to find an optimal solution instead of the best solution.
The main issues for distributed query optimization are −
- Optimal utilization of resources in the distributed system.
- Query trading.
- Reduction of solution space of the query.
Optimal Utilization of Resources in the Distributed System
A distributed system has a number of database servers in the various sites to perform the operations pertaining to a query. Following are the approaches for optimal resource utilization −
Operation Shipping − In operation shipping, the operation is run at the site where the data is stored and not at the client site. The results are then transferred to the client site. This is appropriate for operations where the operands are available at the same site. Example: Select and Project operations.
Data Shipping − In data shipping, the data fragments are transferred to the database server, where the operations are executed. This is used in operations where the operands are distributed at different sites. This is also appropriate in systems where the communication costs are low, and local processors are much slower than the client server.
Hybrid Shipping − This is a combination of data and operation shipping. Here, data fragments are transferred to the high-speed processors, where the operation runs. The results are then sent to the client site.
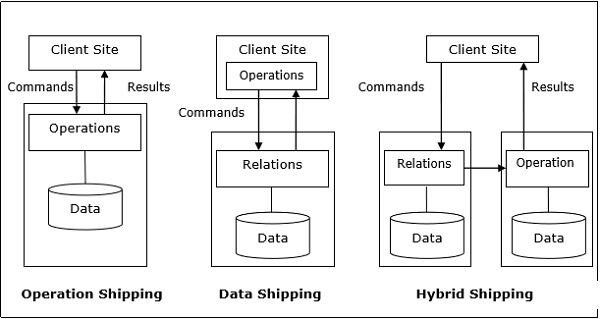
Query Trading
In query trading algorithm for distributed database systems, the controlling/client site for a distributed query is called the buyer and the sites where the local queries execute are called sellers. The buyer formulates a number of alternatives for choosing sellers and for reconstructing the global results. The target of the buyer is to achieve the optimal cost.
The algorithm starts with the buyer assigning sub-queries to the seller sites. The optimal plan is created from local optimized query plans proposed by the sellers combined with the communication cost for reconstructing the final result. Once the global optimal plan is formulated, the query is executed.
Reduction of Solution Space of the Query
Optimal solution generally involves reduction of solution space so that the cost of query and data transfer is reduced. This can be achieved through a set of heuristic rules, just as heuristics in centralized systems.
Following are some of the rules −
Perform selection and projection operations as early as possible. This reduces the data flow over communication network.
Simplify operations on horizontal fragments by eliminating selection conditions which are not relevant to a particular site.
In case of join and union operations comprising of fragments located in multiple sites, transfer fragmented data to the site where most of the data is present and perform operation there.
Use semi-join operation to qualify tuples that are to be joined. This reduces the amount of data transfer which in turn reduces communication cost.
Merge the common leaves and sub-trees in a distributed query tree.
