- Distributed Database Environments
- DDBMS - Design Strategies
- DDBMS - Distribution Transparency
- DDBMS - Database Control
- Query Optimization
- Relational Algebra Query
- Query Optimization Centralized
- Query Optimization in Distributed
- Concurrency Control
- Transaction Processing Systems
- DDBMS - Controlling Concurrency
- DDBMS - Deadlock Handling
- Failure and Recovery
- DDBMS - Replication Control
- DDBMS - Failure & Commit
- DDBMS - Database Recovery
- Distributed Commit Protocols
- Distributed DBMS Security
- Database Security & Cryptography
- Security in Distributed Databases
- Distributed DBMS Resources
- DDBMS - Quick Guide
- DDBMS - Useful Resources
- DDBMS - Discussion
Distributed DBMS - Database Recovery
In order to recuperate from database failure, database management systems resort to a number of recovery management techniques. In this chapter, we will study the different approaches for database recovery.
The typical strategies for database recovery are −
In case of soft failures that result in inconsistency of database, recovery strategy includes transaction undo or rollback. However, sometimes, transaction redo may also be adopted to recover to a consistent state of the transaction.
In case of hard failures resulting in extensive damage to database, recovery strategies encompass restoring a past copy of the database from archival backup. A more current state of the database is obtained through redoing operations of committed transactions from transaction log.
Recovery from Power Failure
Power failure causes loss of information in the non-persistent memory. When power is restored, the operating system and the database management system restart. Recovery manager initiates recovery from the transaction logs.
In case of immediate update mode, the recovery manager takes the following actions −
Transactions which are in active list and failed list are undone and written on the abort list.
Transactions which are in before-commit list are redone.
No action is taken for transactions in commit or abort lists.
In case of deferred update mode, the recovery manager takes the following actions −
Transactions which are in the active list and failed list are written onto the abort list. No undo operations are required since the changes have not been written to the disk yet.
Transactions which are in before-commit list are redone.
No action is taken for transactions in commit or abort lists.
Recovery from Disk Failure
A disk failure or hard crash causes a total database loss. To recover from this hard crash, a new disk is prepared, then the operating system is restored, and finally the database is recovered using the database backup and transaction log. The recovery method is same for both immediate and deferred update modes.
The recovery manager takes the following actions −
The transactions in the commit list and before-commit list are redone and written onto the commit list in the transaction log.
The transactions in the active list and failed list are undone and written onto the abort list in the transaction log.
Checkpointing
Checkpoint is a point of time at which a record is written onto the database from the buffers. As a consequence, in case of a system crash, the recovery manager does not have to redo the transactions that have been committed before checkpoint. Periodical checkpointing shortens the recovery process.
The two types of checkpointing techniques are −
- Consistent checkpointing
- Fuzzy checkpointing
Consistent Checkpointing
Consistent checkpointing creates a consistent image of the database at checkpoint. During recovery, only those transactions which are on the right side of the last checkpoint are undone or redone. The transactions to the left side of the last consistent checkpoint are already committed and neednt be processed again. The actions taken for checkpointing are −
- The active transactions are suspended temporarily.
- All changes in main-memory buffers are written onto the disk.
- A checkpoint record is written in the transaction log.
- The transaction log is written to the disk.
- The suspended transactions are resumed.
If in step 4, the transaction log is archived as well, then this checkpointing aids in recovery from disk failures and power failures, otherwise it aids recovery from only power failures.
Fuzzy Checkpointing
In fuzzy checkpointing, at the time of checkpoint, all the active transactions are written in the log. In case of power failure, the recovery manager processes only those transactions that were active during checkpoint and later. The transactions that have been committed before checkpoint are written to the disk and hence need not be redone.
Example of Checkpointing
Let us consider that in system the time of checkpointing is tcheck and the time of system crash is tfail. Let there be four transactions Ta, Tb, Tc and Td such that −
Ta commits before checkpoint.
Tb starts before checkpoint and commits before system crash.
Tc starts after checkpoint and commits before system crash.
Td starts after checkpoint and was active at the time of system crash.
The situation is depicted in the following diagram −
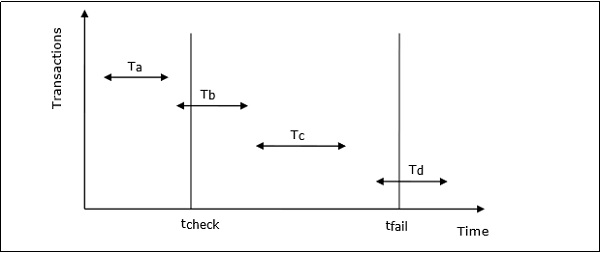
The actions that are taken by the recovery manager are −
- Nothing is done with Ta.
- Transaction redo is performed for Tb and Tc.
- Transaction undo is performed for Td.
Transaction Recovery Using UNDO / REDO
Transaction recovery is done to eliminate the adverse effects of faulty transactions rather than to recover from a failure. Faulty transactions include all transactions that have changed the database into undesired state and the transactions that have used values written by the faulty transactions.
Transaction recovery in these cases is a two-step process −
UNDO all faulty transactions and transactions that may be affected by the faulty transactions.
REDO all transactions that are not faulty but have been undone due to the faulty transactions.
Steps for the UNDO operation are −
If the faulty transaction has done INSERT, the recovery manager deletes the data item(s) inserted.
If the faulty transaction has done DELETE, the recovery manager inserts the deleted data item(s) from the log.
If the faulty transaction has done UPDATE, the recovery manager eliminates the value by writing the before-update value from the log.
Steps for the REDO operation are −
If the transaction has done INSERT, the recovery manager generates an insert from the log.
If the transaction has done DELETE, the recovery manager generates a delete from the log.
If the transaction has done UPDATE, the recovery manager generates an update from the log.
