- Apache Kafka - Home
- Apache Kafka - Introduction
- Apache Kafka - Fundamentals
- Apache Kafka - Cluster Architecture
- Apache Kafka - Work Flow
- Apache Kafka - Installation Steps
- Apache Kafka - Basic Operations
- Simple Producer Example
- Consumer Group Example
- Integration With Storm
- Integration With Spark
- Real Time Application(Twitter)
- Apache Kafka - Tools
- Apache Kafka - Applications
Apache Kafka - Fundamentals
Before moving deep into the Kafka, you must aware of the main terminologies such as topics, brokers, producers and consumers. The following diagram illustrates the main terminologies and the table describes the diagram components in detail.
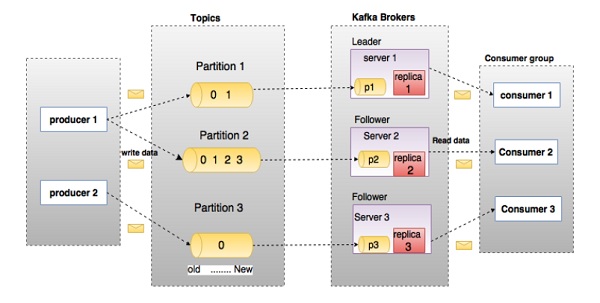
In the above diagram, a topic is configured into three partitions. Partition 1 has two offset factors 0 and 1. Partition 2 has four offset factors 0, 1, 2, and 3. Partition 3 has one offset factor 0. The id of the replica is same as the id of the server that hosts it.
Assume, if the replication factor of the topic is set to 3, then Kafka will create 3 identical replicas of each partition and place them in the cluster to make available for all its operations. To balance a load in cluster, each broker stores one or more of those partitions. Multiple producers and consumers can publish and retrieve messages at the same time.
| S.No | Components and Description |
|---|---|
| 1 | Topics A stream of messages belonging to a particular category is called a topic. Data is stored in topics. Topics are split into partitions. For each topic, Kafka keeps a mini-mum of one partition. Each such partition contains messages in an immutable ordered sequence. A partition is implemented as a set of segment files of equal sizes. |
| 2 | Partition Topics may have many partitions, so it can handle an arbitrary amount of data. |
| 3 |
Partition offset Each partitioned message has a unique sequence id called as |
| 4 |
Replicas of partition Replicas are nothing but |
| 5 |
Brokers
|
| 6 |
Kafka Cluster Kafkas having more than one broker are called as Kafka cluster. A Kafka cluster can be expanded without downtime. These clusters are used to manage the persistence and replication of message data. |
| 7 |
Producers Producers are the publisher of messages to one or more Kafka topics. Producers send data to Kafka brokers. Every time a producer pub-lishes a message to a broker, the broker simply appends the message to the last segment file. Actually, the message will be appended to a partition. Producer can also send messages to a partition of their choice. |
| 8 |
Consumers Consumers read data from brokers. Consumers subscribes to one or more topics and consume published messages by pulling data from the brokers. |
| 9 |
Leader
|
| 10 |
Follower Node which follows leader instructions are called as follower. If the leader fails, one of the follower will automatically become the new leader. A follower acts as normal consumer, pulls messages and up-dates its own data store. |
