- Apache Kafka - Home
- Apache Kafka - Introduction
- Apache Kafka - Fundamentals
- Apache Kafka - Cluster Architecture
- Apache Kafka - Work Flow
- Apache Kafka - Installation Steps
- Apache Kafka - Basic Operations
- Simple Producer Example
- Consumer Group Example
- Integration With Storm
- Integration With Spark
- Real Time Application(Twitter)
- Apache Kafka - Tools
- Apache Kafka - Applications
Apache Kafka - Cluster Architecture
Take a look at the following illustration. It shows the cluster diagram of Kafka.
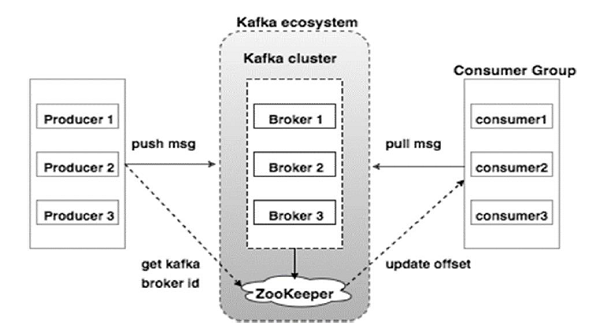
The following table describes each of the components shown in the above diagram.
| S.No | Components and Description |
|---|---|
| 1 |
Broker Kafka cluster typically consists of multiple brokers to maintain load balance. Kafka brokers are stateless, so they use ZooKeeper for maintaining their cluster state. One Kafka broker instance can handle hundreds of thousands of reads and writes per second and each bro-ker can handle TB of messages without performance impact. Kafka broker leader election can be done by ZooKeeper. |
| 2 |
ZooKeeper ZooKeeper is used for managing and coordinating Kafka broker. ZooKeeper service is mainly used to notify producer and consumer about the presence of any new broker in the Kafka system or failure of the broker in the Kafka system. As per the notification received by the Zookeeper regarding presence or failure of the broker then pro-ducer and consumer takes decision and starts coordinating their task with some other broker. |
| 3 |
Producers Producers push data to brokers. When the new broker is started, all the producers search it and automatically sends a message to that new broker. Kafka producer doesnt wait for acknowledgements from the broker and sends messages as fast as the broker can handle. |
| 4 |
Consumers Since Kafka brokers are stateless, which means that the consumer has to maintain how many messages have been consumed by using partition offset. If the consumer acknowledges a particular message offset, it implies that the consumer has consumed all prior messages. The consumer issues an asynchronous pull request to the broker to have a buffer of bytes ready to consume. The consumers can rewind or skip to any point in a partition simply by supplying an offset value. Consumer offset value is notified by ZooKeeper. |
