- Agile Data Science - Home
- Agile Data Science - Introduction
- Methodology Concepts
- Agile Data Science - Process
- Agile Tools & Installation
- Data Processing in Agile
- SQL versus NoSQL
- NoSQL & Dataflow programming
- Collecting & Displaying Records
- Data Visualization
- Data Enrichment
- Working with Reports
- Role of Predictions
- Extracting features with PySpark
- Building a Regression Model
- Deploying a predictive system
- Agile Data Science - SparkML
- Fixing Prediction Problem
- Improving Prediction Performance
- Creating better scene with agile & data science
- Implementation of Agile
Agile Data Science - Introduction
Agile data science is an approach of using data science with agile methodology for web application development. It focusses on the output of the data science process suitable for effecting change for an organization. Data science includes building applications that describe research process with analysis, interactive visualization and now applied machine learning as well.
The major goal of agile data science is to −
document and guide explanatory data analysis to discover and follow the critical path to a compelling product.
Agile data science is organized with the following set of principles −
Continuous Iteration
This process involves continuous iteration with creation tables, charts, reports and predictions. Building predictive models will require many iterations of feature engineering with extraction and production of insight.
Intermediate Output
This is the track list of outputs generated. It is even said that failed experiments also have output. Tracking output of every iteration will help creating better output in the next iteration.
Prototype Experiments
Prototype experiments involve assigning tasks and generating output as per the experiments. In a given task, we must iterate to achieve insight and these iterations can be best explained as experiments.
Integration of data
The software development life cycle includes different phases with data essential for −
customers
developers, and
the business
The integration of data paves way for better prospects and outputs.
Pyramid data value
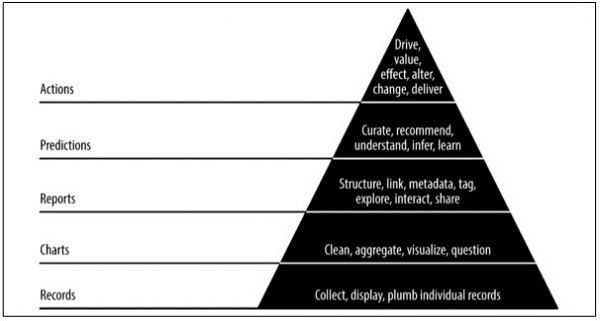
The above pyramid value described the layers needed for Agile data science development. It starts with a collection of records based on the requirements and plumbing individual records. The charts are created after cleaning and aggregation of data. The aggregated data can be used for data visualization. Reports are generated with proper structure, metadata and tags of data. The second layer of pyramid from the top includes prediction analysis. The prediction layer is where more value is created but helps in creating good predictions that focus on feature engineering.
The topmost layer involves actions where the value of data is driven effectively. The best illustration of this implementation is Artificial Intelligence.
