
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
Top 7 Clustering Algorithms Data Scientists Should Know?
Clustering algorithms are a type of machine learning algorithm that can be used to find groups of similar data points in a dataset. These algorithms are useful for a variety of applications, such as data compression, anomaly detection, and topic modeling. In some cases, clustering algorithms can be used to find hidden patterns or relationships in a dataset that might not be immediately apparent. By grouping similar data points together, clustering algorithms can help to simplify and make sense of large and complex datasets. In this post, we will look closely at Clustering algorithms and the top seven algorithms that data scientists should be familiar with.
What is Clustering Algorithms?
Clustering algorithms are a sort of unsupervised machine learning method that is used to locate groups of data points that are similar within a dataset. These algorithms do not require labeled data and instead seek patterns and correlations in the data itself. Data compression, anomaly detection, and topic modeling are just a few of the applications that employ clustering algorithms.
Common clustering algorithms include k-means clustering, hierarchical clustering, and density?based clustering. These algorithms divide the dataset into groups, or clusters, depending on the similarity of the data points inside each cluster. The purpose of clustering algorithms is to locate the most relevant and valuable data groups, which can assist to simplify and make sense of vast and complicated datasets.
Top 7 Clustering Algorithms Data Scientists should know
Data scientists can employ a variety of clustering methods, and the best approach to utilize will depend on the particular problem at hand. Among the most well?liked clustering algorithms are ?
1. K-means Clustering
K-means Clustering is a popular clustering method that seeks to divide a set of data points into a predetermined number of groups. It does this by allocating each data point repeatedly to the cluster with the closest mean and then changing the mean of each cluster depending on the points assigned to it. This procedure is continued until the clusters converge, after which the algorithm returns the final clusters.
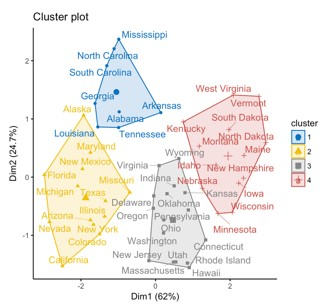
One of the primary benefits of K-means clustering is its simplicity and ease of implementation, making it a popular choice among data scientists. It is also computationally efficient, making it suitable for huge datasets. However, one of K-means clustering's weaknesses is that it assumes the clusters have a spherical form, which may not necessarily be the case in real-world data.
2. Hierarchical Clustering
Hierarchical clustering is a cluster analysis approach that seeks to create a hierarchy of groups. Clusters are built?in hierarchical clustering with a specified ordering from top to bottom. This indicates that clusters at higher levels of the hierarchy are more broad and inclusive, whereas clusters at lower levels are more specialized and exclusive.
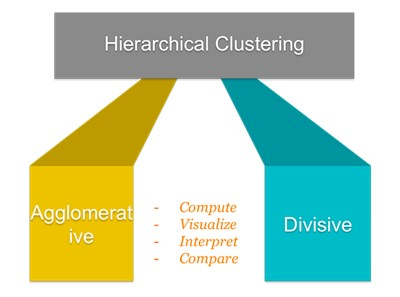
The basic principle behind hierarchical clustering is to group related data points into clusters, then into bigger and more generic clusters, until all data points are clustered into a single cluster at the top of the hierarchy. This method enables the clustering algorithm to capture the underlying structure of the data and uncover patterns and correlations that may not be obvious from the raw data.
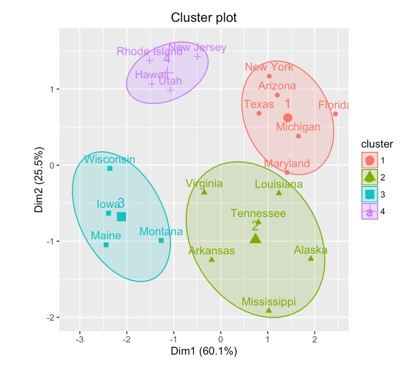
3. Density-based Clustering
Density?based clustering is a cluster analysis approach that identifies clusters with a high density in a dataset. The process in density-based clustering begins by selecting a collection of points in the dataset that are surrounded by a significant number of other points.
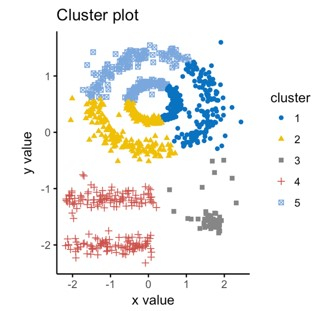
These points are regarded to be part of a dense zone, and the algorithm will next attempt to extend this region to encompass all of the cluster's points. This method enables the algorithm to find clusters of any shape, making it well-suited to datasets with no apparent and recognizable structure. DBSCAN and HDBSCAN are two examples of density-based clustering algorithms.
4. Fuzzy Clustering
Fuzzy clustering, also known as fuzzy clustering, is a cluster analysis technique that allows a data point to belong to many clusters. Each data point in fuzzy clustering is assigned a membership value that reflects how much it belongs to each cluster. This implies that instead of being totally assigned to just one cluster as in traditional (hard) clustering methods, a data point might be partially assigned to numerous clusters.
This is beneficial when the data points do not clearly belong to one of the clusters or when the clusters themselves are not well?defined. The Fuzzy C?Means (FCM) and Gustafson?Kessel (GK) algorithms are two examples of fuzzy clustering algorithms.
5. Model-based Clustering
Model-based clustering is a cluster analysis technique that involves fitting a statistical model to the data in order to discover clusters. The procedure in model-based clustering first specifies a probabilistic model for the data, such as a combination of Gaussian distributions.
After then, the algorithm employs an optimization technique to choose the set of model parameters that best fits the data. This method enables the algorithm to capture the underlying structure of the data and find clusters that may not be obvious from the raw data. The Expectation-Maximization (EM) technique and the Bayesian Gaussian mixture model are two examples of model-based clustering algorithms.
6. EM Clustering
The Expectation?Maximization (EM) algorithm, often known as EM clustering, is a cluster analysis method that uses a probabilistic approach to discover clusters in a dataset. The EM method is an iterative technique that begins by guessing at the parameters of the statistical model that represents the data. The parameters are then used to calculate the chance that each data point belongs to each cluster. This is referred to as the expectation stage.
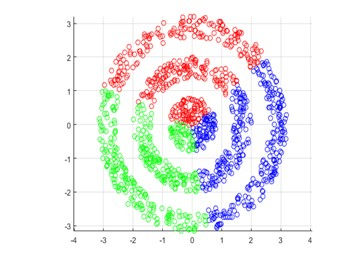
The algorithm then utilizes these likelihoods to update the model parameters, a process known as maximizing. This approach is done until the model parameters converge to a stable solution. EM clustering is especially beneficial for datasets with a complicated underlying structure, for which typical clustering approaches may not function well.
7. DBSCAN
DBSCAN (Density?based Spatial Clustering of Applications with Noise) is a well-known density-based clustering technique. It is a sort of clustering method that identifies clusters with a high density in a dataset. DBSCAN operates by locating points in the dataset that are surrounded by a significant number of other points.
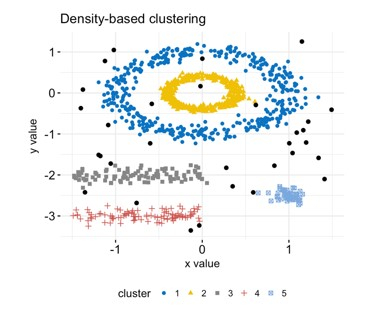
These points are regarded to be part of a dense zone, and the algorithm will next attempt to extend this region to encompass all of the cluster's points. The algorithm can find clusters of any shape thanks to this method, which makes it a good fit for datasets without a definite and well-defined structure. The DBSCAN technique is used in many different applications since it is scalable and effective.
Conclusion
To sum up, clustering algorithms are an effective tool for data scientists to find patterns and connections in a dataset. These methods are applicable to a wide range of data and clustering applications and employ various strategies to group comparable data points into clusters. The selection of the best clustering method will rely on the individual features of the dataset and the objectives of the study. There are several types of clustering algorithms, each with unique strengths and limitations. In order to choose the best clustering method for your study, it is critical that you, as a data scientist, have a solid grasp of the various clustering algorithms and their capabilities.

729 Views
