- Apache Tika - Home
- Apache Tika - Overview
- Apache Tika - Architecture
- Apache Tika - Environment
- Apache Tika - Referenced API
- Apache Tika - File Formats
- Apache Tika - Document Type Detection
- Apache Tika - Content Extraction
- Apache Tika - Metadata Extraction
- Apache Tika - Language Detection
- Apache Tika - GUI
Apache Tika Examples
- Apache Tika - Extracting PDF
- Apache Tika - Extracting ODF
- Apache Tika - Extracting MS-Office Files
- Apache Tika - Extracting Text Document
- Apache Tika - Extracting HTML Document
- Apache Tika - Extracting XML Document
- Apache Tika - Extracting .class File
- Apache Tika - Extracting JAR File
- Apache Tika - Extracting Image File
- Apache Tika - Extracting mp4 Files
- Apache Tika - Extracting mp3 Files
Apache Tika Resources
Selected Reading
Apache Tika - Extracting PDF
Example - Extracting Content and Metadata from a PDF Document
Given below is the program to extract content and metadata from a PDF.
TikaDemo.java
package com.tutorialspoint.tika;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.pdf.PDFParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class TikaDemo {
public static void main(final String[] args) throws IOException,TikaException {
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("D:/projects/example.pdf"));
ParseContext pcontext = new ParseContext();
//parsing the document using PDF parser
PDFParser pdfparser = new PDFParser();
pdfparser.parse(inputstream, handler, metadata,pcontext);
//getting the content of the document
System.out.println("Contents of the PDF:" + handler.toString());
//getting metadata of the document
System.out.println("Metadata of the PDF:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name+ " : " + metadata.get(name));
}
}
}
Output
Given below is the snapshot of example.pdf
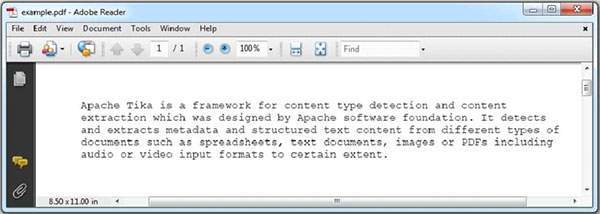
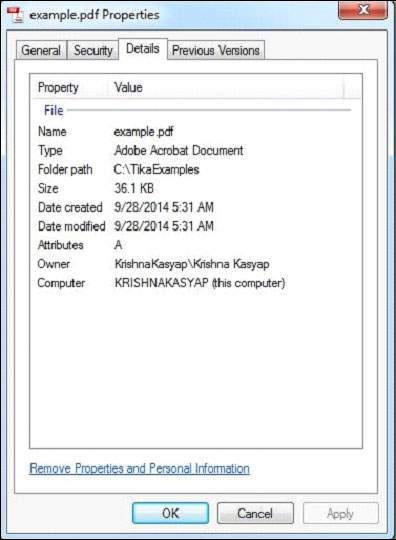
The PDF we are passing has the following properties −
After compiling the program, you will get the output as shown below.
Contents of the PDF: Apache Tika is a framework for content type detection and content extraction which was designed by Apache software foundation. It detects and extracts metadata and structured text content from different types of documents such as spreadsheets, text documents, images or PDFs including audio or video input formats to certain extent. Metadata of the PDF: pdf:unmappedUnicodeCharsPerPage : 0 pdf:PDFVersion : 1.7 xmp:CreatorTool : Microsoft® Word 2021 pdf:hasXFA : false access_permission:modify_annotations : true dc:creator : Mahesh Parashar pdf:num3DAnnotations : 0 dcterms:created : 2025-10-27T10:36:34Z dcterms:modified : 2025-10-27T10:36:34Z dc:format : application/pdf; version=1.7 xmpMM:DocumentID : uuid:463AA685-EDF0-40CC-8712-344DB211B4F7 pdf:docinfo:creator_tool : Microsoft® Word 2021 pdf:overallPercentageUnmappedUnicodeChars : 0.0 access_permission:fill_in_form : true pdf:docinfo:modified : 2025-10-27T10:36:34Z pdf:hasCollection : false pdf:encrypted : false pdf:containsNonEmbeddedFont : false xmp:CreateDate : 2025-10-27T10:36:34Z pdf:hasMarkedContent : true pdf:ocrPageCount : 0 Content-Type : application/pdf access_permission:can_print_faithful : true xmp:ModifyDate : 2025-10-27T10:36:34Z pdf:docinfo:creator : Mahesh Parashar dc:language : en pdf:producer : Microsoft® Word 2021 xmp:pdf:Producer : Microsoft® Word 2021 pdf:totalUnmappedUnicodeChars : 0 access_permission:extract_for_accessibility : true access_permission:assemble_document : true xmpTPg:NPages : 1 pdf:hasXMP : true pdf:charsPerPage : 331 access_permission:extract_content : true access_permission:can_print : true xmp:dc:creator : Mahesh Parashar access_permission:can_modify : true pdf:docinfo:producer : Microsoft® Word 2021 pdf:docinfo:created : 2025-10-27T10:36:34Z pdf:containsDamagedFont : false

Advertisements