- Apache Tika - Home
- Apache Tika - Overview
- Apache Tika - Architecture
- Apache Tika - Environment
- Apache Tika - Referenced API
- Apache Tika - File Formats
- Apache Tika - Document Type Detection
- Apache Tika - Content Extraction
- Apache Tika - Metadata Extraction
- Apache Tika - Language Detection
- Apache Tika - GUI
Apache Tika Examples
- Apache Tika - Extracting PDF
- Apache Tika - Extracting ODF
- Apache Tika - Extracting MS-Office Files
- Apache Tika - Extracting Text Document
- Apache Tika - Extracting HTML Document
- Apache Tika - Extracting XML Document
- Apache Tika - Extracting .class File
- Apache Tika - Extracting JAR File
- Apache Tika - Extracting Image File
- Apache Tika - Extracting mp4 Files
- Apache Tika - Extracting mp3 Files
Apache Tika Resources
Selected Reading
Apache Tika - Extracting HTML Document
Example - Extracting Content and Metadata from a HTML Document
Given below is the program to extract content and metadata from a HTML Document.
TikaDemo.java
package com.tutorialspoint.tika;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class TikaDemo {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("D:/projects/example.html"));
ParseContext pcontext = new ParseContext();
//Html parser
AutoDetectParser htmlparser = new AutoDetectParser();
htmlparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}
Output
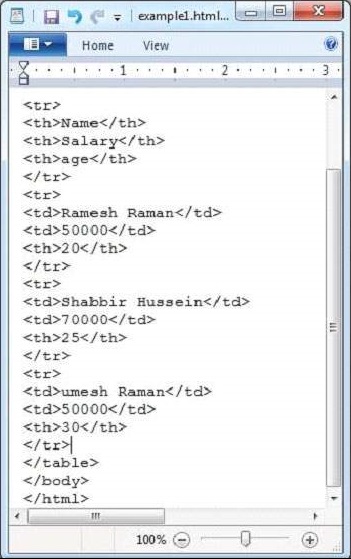
Given below is the snapshot of example.html file.
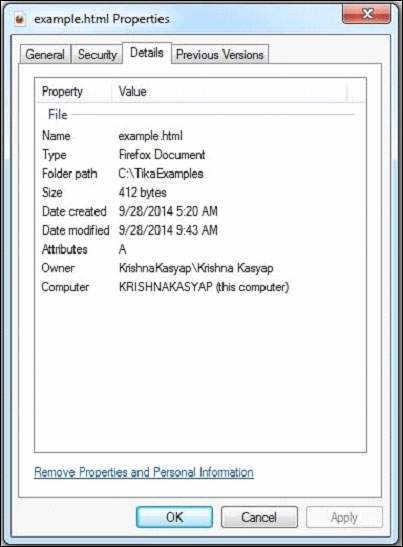
The HTML document has the following properties −
After executing the above program you will get the following output.
Contents of the document: Name Salary Age Ramesh 50000 20 Shabbir 70000 25 Umesh 50000 30 Metadata of the document: X-TIKA:Parsed-By: org.apache.tika.parser.DefaultParser dc:title: HTML Table Header X-TIKA:Parsed-By-Full-Set: org.apache.tika.parser.DefaultParser Content-Encoding: windows-1252 X-TIKA:detectedEncoding: windows-1252 X-TIKA:encodingDetector: UniversalEncodingDetector Content-Type: text/html; charset=windows-1252

Advertisements