
- SAP HANA - Overview
- In-Memory Computing Engine
- SAP HANA - Studio
- Studio Administration View
- SAP HANA - System Monitor
- SAP HANA - Information Modeler
- SAP HANA - Core Architecture
- SAP HANA Modeling
- SAP HANA - Modeling
- SAP HANA - Data Warehouse
- SAP HANA - Tables
- SAP HANA - Packages
- SAP HANA - Attribute View
- SAP HANA - Analytic View
- SAP HANA - Calculation View
- SAP HANA - Analytic Privileges
- SAP HANA - Information Composer
- SAP HANA - Export and Import
- SAP HANA Reporting
- SAP HANA - Reporting View
- Bi 4.0 Connectivity to HANA Views
- SAP HANA - Crystal Reports
- SAP HANA - Excel Integration
- SAP HANA Security
- SAP HANA - Security Overview
- User Administration & Management
- SAP HANA - Authentications
- SAP HANA - Authorization methods
- SAP HANA - License Management
- SAP HANA - Auditing
- SAP HANA Data Replication
- SAP HANA - Data Replication Overview
- SAP HANA - ETL Based Replication
- SAP HANA - Log Based Replication
- SAP HANA - DXC Method
- SAP HANA - CTL Method
- SAP HANA - MDX Provider
- SAP HANA Monitoring
- SAP HANA - Monitoring and Alerting
- SAP HANA - Persistent Layer
- SAP HANA - Backup & Recovery
- SAP HANA - High Availability
- SAP HANA - Log Configuration
- SAP HANA SQL
- SAP HANA - SQL Overview
- SAP HANA - Data Types
- SAP HANA - SQL Operators
- SAP HANA - SQL Functions
- SAP HANA - SQL Expressions
- SAP HANA - SQL Stored Procedures
- SAP HANA - SQL Sequences
- SAP HANA - SQL Triggers
- SAP HANA - SQL Synonym
- SAP HANA - SQL Explain Plans
- SAP HANA - SQL Data Profiling
- SAP HANA - SQL Script
- SAP HANA Useful Resources
- SAP HANA - Questions and Answers
- SAP HANA - Quick Guide
- SAP HANA - Useful Resources
- SAP HANA - Discussion
SAP HANA Interview Questions
Dear readers, these SAP HANA Interview Questions have been designed specially to get you acquainted with the nature of questions you may encounter during your interview for the subject of SAP HANA. As per my experience good interviewers hardly plan to ask any particular question during your interview, normally questions start with some basic concept of the subject and later they continue based on further discussion and what you answer −
HANA supports both type of data store in database. Row store is used when you need to use Select statement and no aggregations are performed.
Column store is used to perform aggregations and HANA Modeling is supported only on Column based tables.
There are total 11 vendors for SAP HANA hardware appliances. Most common are −
- Dell
- IBM
- HP
- Cisco
- Lenovo
HANA studio is an eclipsed based tool and provides support for development and administration in HANA system. You can perform HANA Modeling on the top of tables in database, Data provisioning, HANA Administration and various other activities using HANA studio.
SAP HANA Studio client is available for Windows XP, Windows Vista, and Windows 7 for 32 bit and 64 bit operating system.
In-Memory concept of SAP HANA means that all the data is stored in RAM memory. A conventional database transfer data from memory in 5 milliseconds however SAP HANA In-memory takes 5 nanoseconds to read data.
SAP HANA uses multicore CPU architecture and stores data in row and column based storage in HANA database.
Only operating system that is supported by HANA is Suse Linux Enterprise Server SP1/SP2 (SLES SP1/2).
Consider below table- FCTSales
| Country | Product | Units Sold |
| England | iphone 6 | 107 |
| India | Samsung Note 6 | 250 |
| US | Lenovo A110 | 110 |
Row Based Storage −
- England
- Iphone6
- 107
- India
- Samsung Note 6
- 250
- US
- Lenovo A110
- 110
Column Based Storage −
- England
- India
- US
- Iphone6
- Samsung Note6
- Lenovo A110
- 107
- 250
- 110
Where to use Row based storage?
Select * from FCTSales where Country=US
Where to use Column based storage?
Select SUM(Units_sold) from FCTSales where Product=Lenovo A110
- Index Server
- Name Server
- Statistical Server
- Preprocessor Server
- XS Engine
- SAP Host Agent
- LM structure
- SAP Solution Manager Diagnostic Agent
Index server contains engine to process data in HANA database. These data engines are responsible to handle all SQL/MDX statement in HANA system. Index server also contains Session and Transaction Manager which is responsible to manage all running and completed transactions.
Persistence layer provides inbuilt mechanism for disaster recovery in HANA system. It ensures that database is restored to most recent state in case of a system failure.
Persistence layer also manages data, transaction and configuration logs and backup of these files. Backups of data and log files are performed at save points and is normally scheduled every 5-10 minutes.
- Temporary License key
- Permanent License Key
Temporary License keys are automatically installed when you install the HANA database. These keys are valid only for 90 days and you should request permanent license keys from SAP market place before expiry of this 90 days period after installation.
Permanent License keys are valid till the predefine expiration date. License keys specify amount of memory licensed to target HANA installation.
There are two types of permanent License keys for HANA system −
Unenforced − If unenforced license key is installed and consumption of HANA system exceeds the license amount of memory, operation of SAP HANA is not affected in this case.
Enforced − If Enforced license key is installed and consumption of HANA system exceeds the license amount of memory, HANA system gets locked. If this situation occurs, HANA system has to be restarted or a new license key should be requested and installed.
Grant SELECT privileges on schemas of the used data foundation tables to user "_SYS_REPO"
GRANT SELECT ON SCHEMA "<SCHEMA_NAME>" TO _SYS_REPO WITH GRANT OPTION
Backup −
It is used to perform for backup and recovery in SAP HANA system. You can check backup configuration details, run manual backup, to check last successful back performed, etc. for data and log backup.
Catalog −
This contains RDBMS objects like schemas, tables, views, procedures, etc. You can open SQL editor and design database objects
Content −
This is used to maintain design time repository
You can create new packages and design Information views in HANA system. Various views can be created under content tab to meet business requirement and to perform analytical reports on the top of the Modeling views.
Provisioning −
This is used for Smart data access to connect to other databases like HADOOP, TERADATA and SYBASE
Security −
This is used to define users and to assign roles. You can define various privileges on different users using Security tab. You can assign Database and Package privileges to different users to control the data access.
Open Data Preview −
This is used to see the data stored in an object- table or a modeling view. When you open data preview, you get three options −
- Raw Data
- Distinct Values
- Analysis
Open Definition −
This is used to see the structure of the table − column name, column data type, keys, etc.
Go to Administration → alerts
In Administration tab, you can check system overview, landscape, volumes, configuration, system information, etc.
SAP HANA cockpit is a SAP Fiori Launchpad site that allows you with a single point-of-access to a range of Web-based applications for the online administration of SAP HANA. You access the SAP HANA cockpit through a Web browser.
To open SAP HANA Cockpit → Right click on HANA system in Studio → configuration and monitoring → open SAP HANA cockpit
Catalog −
This contains RDBMS objects like schemas, tables, views, procedures, etc. You can open SQL editor and design database objects.
Content −
This is used to maintain design time repository. You can create new packages and design Information views in HANA system. Various views can be created under content tab to meet business requirement and to perform analytical reports on the top of the Modeling views.
Analytic View
Copy option allows you to copy an existing Information view and to make changes to it.
Derived option allows to create a copy of an existing view and you cant make any changes to it.
Data Foundation − to add column base tables.
Star Join − to add other type of views.
Semantic − to define user parameters and to define measures and dimensions.
- Measure and Attribute
- Hierarchies
- Parameters/Variables
- New Calculated Column
New calculated column is defined as a column added on the fly in Analysis tab when a view is activated. This column doesnt exist at database level or in Data Foundation or Star Join level.
You can select Switch to Performance Analysis Mode. This allows you to do Performance Analysis by validating correct join type and Cardinality.
It simplify the design process as allows you to select multiple measures from multiple fact tables.
You can implement 3NF using Star Join.
Variables are used as an explicit SQL filter directive for view consumers to filter the view data, based on attribute column values specified in variable UI prompt of a BI Client. When you go to data preview, variables allow users to pass the value of attribute defined in the variable.
You can select a single value, range or range in selection type.
- Join
- Union
- Project
- Aggregation
- Rank.
Projection
There is a diamond mark on view name if it is not active.
No. In a Calculation view with Star Join, you can only use Dim Calculation views.
Analytic Privileges are used to limit access on HANA Information views. You can assign different types of right to different users on different component of a View in Analytic Privileges.
Using Analytic Privileges, you can add Region attribute and values to Attribute Restrictions and Time duration is defined in Privilege validity.
Analytic Privilege can be added to user profile in User and Roles under Security tab.
- SAP LT Replication SLT
- SAP Data Services
- Direct Extract Connection DXC
- Load
- Replicate
- Suspend
- Resume
On your source SAP system A1 you want to setup a trusted RFC to target system B1. When it is done it would mean that when you are logged onto A1 and your user has enough Authorization in B1, you can use the RFC connection and logon to B1 without having to re-enter user and password.
SM59 to create a trusted RFC
Ltr to configure the connection
Go to SAP HANA Modeler Perspective → Data Provisioning.
You have to select SAP Applications in data store type and SAP HANA in Database drop down list.
Replication job can be performed in Data Services Management Console. You have to go to status tab and select the repository where job is created → Batch Job Status.
There you can find different tabs- Trace, Monitor, Error and Performance Monitor.
To enable auditing of batch job, this can be done in job execution parameters.
Go to status tab and select the repository where job is created → Batch Job configuration → Add Schedule.
Here you can find job execution parameters while adding a schedule for the job.
Owner represents schema name where tables will be moved using batch job.
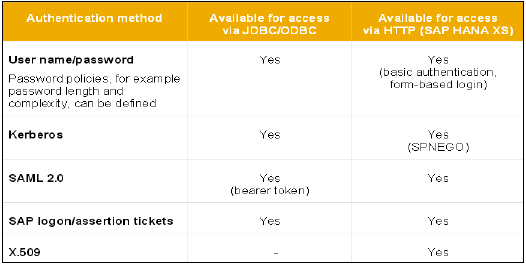
Below is the list of authentication methods supported by SAP HANA −
- User name/Password
- Kerberos
- SAML 2.0
- SAP Logon tickets
- X.509
Restricted users are those users who access HANA system with some applications and they dont have SQL privileges on HANA system. When these users are created they dont have any access initially.
If we compare restricted users with Standard users −
Restricted users cant create objects in HANA database or their own Schemas.
They dont have access to view any data in database as they dont have generic Public role added to profile like standard users.
They can connect to HANA database only using HTTP/HTTPS.
Only database users with the system privilege ROLE ADMIN are allowed to create users and roles in HANA studio.
- System Privilege
- Object Privilege
- Analytic Privilege
- Package Privilege
- Application Privilege
- Privilege on roles
Audit Admin
Go to Security option in HANA system → Auditing

Under Global Settings→set Auditing status as enabled. You can also choose different Audit trail targets.
MDX Provider is used to connect MS Excel to SAP HANA database system. It provides driver to connect HANA system to Excel and is further used for data modelling. You can use Microsoft Office Excel 2010/2013 for connectivity with HANA for both 32 bit and 64 bit Windows.
This can be done in File Based data backup settings. In Backup tab, go to Configuration → Limit Maximum file Size check box and enter the file size.
Most Recent State − Used for recovering the database to the time as close as possible to the current time. For this recovery the data backup and log backup have to be available since last data backup and log area are required to perform the above type recovery.
Point in Time − Used for recovering the database to the specific point in time. For this recovery the data backup and log backup have to be available since last data backup and log area are required to perform the above type recovery.
Specific Data Backup − Used for recovering the database to a specified data backup. Specific data backup is required for the above type of recovery option.
Specific Log Position − This recovery type is an advanced option that can be used in exceptional cases where a previous recovery failed.
Note − To run recovery wizard you should have administrator privileges on HANA system.
- SAP Lumira
- Analysis edition for OLAP
- SAP Crystal Reports
- Design Studio
- Change and Transport system
- Delivery Unit
- Developer Mode
- SAP support mode
Delivery Unit
Delivery unit is a single Unit which can be mapped to multiple packages and can be exported as single entity so that all the packages assigned to Delivery Unit can be treated as single unit.
Go to File → Import, You will see below option
This is used to import data from a flat file like .xls or.csv file. Click on Next → Choose Target System → Define Import Properties.
Select Source file by browsing local system. It also gives an option if you want to keep the header row. It also gives an option to create a new table under existing Schema or if you want to import data from a file to an existing table.
What is Next ?
Further you can go through your past assignments you have done with the subject and make sure you are able to speak confidently on them. If you are fresher then interviewer does not expect you will answer very complex questions, rather you have to make your basics concepts very strong.
Second it really doesn't matter much if you could not answer few questions but it matters that whatever you answered, you must have answered with confidence. So just feel confident during your interview. We at tutorialspoint wish you best luck to have a good interviewer and all the very best for your future endeavor. Cheers :-)
