
- SAP HANA - Overview
- In-Memory Computing Engine
- SAP HANA - Studio
- Studio Administration View
- SAP HANA - System Monitor
- SAP HANA - Information Modeler
- SAP HANA - Core Architecture
- SAP HANA Modeling
- SAP HANA - Modeling
- SAP HANA - Data Warehouse
- SAP HANA - Tables
- SAP HANA - Packages
- SAP HANA - Attribute View
- SAP HANA - Analytic View
- SAP HANA - Calculation View
- SAP HANA - Analytic Privileges
- SAP HANA - Information Composer
- SAP HANA - Export and Import
- SAP HANA Reporting
- SAP HANA - Reporting View
- Bi 4.0 Connectivity to HANA Views
- SAP HANA - Crystal Reports
- SAP HANA - Excel Integration
- SAP HANA Security
- SAP HANA - Security Overview
- User Administration & Management
- SAP HANA - Authentications
- SAP HANA - Authorization methods
- SAP HANA - License Management
- SAP HANA - Auditing
- SAP HANA Data Replication
- SAP HANA - Data Replication Overview
- SAP HANA - ETL Based Replication
- SAP HANA - Log Based Replication
- SAP HANA - DXC Method
- SAP HANA - CTL Method
- SAP HANA - MDX Provider
- SAP HANA Monitoring
- SAP HANA - Monitoring and Alerting
- SAP HANA - Persistent Layer
- SAP HANA - Backup & Recovery
- SAP HANA - High Availability
- SAP HANA - Log Configuration
- SAP HANA SQL
- SAP HANA - SQL Overview
- SAP HANA - Data Types
- SAP HANA - SQL Operators
- SAP HANA - SQL Functions
- SAP HANA - SQL Expressions
- SAP HANA - SQL Stored Procedures
- SAP HANA - SQL Sequences
- SAP HANA - SQL Triggers
- SAP HANA - SQL Synonym
- SAP HANA - SQL Explain Plans
- SAP HANA - SQL Data Profiling
- SAP HANA - SQL Script
- SAP HANA Useful Resources
- SAP HANA - Questions and Answers
- SAP HANA - Quick Guide
- SAP HANA - Useful Resources
- SAP HANA - Discussion
SAP HANA - In-Memory Computing Engine
An In-Memory database means all the data from source system is stored in a RAM memory. In a conventional Database system, all data is stored in hard disk. SAP HANA In-Memory Database wastes no time in loading the data from hard disk to RAM. It provides faster access of data to multicore CPUs for information processing and analysis.
Features of In-Memory Database
The main features of SAP HANA in-memory database are −
SAP HANA is Hybrid In-memory database.
It combines row based, column based and Object Oriented base technology.
It uses parallel processing with multicore CPU Architecture.
Conventional Database reads memory data in 5 milliseconds. SAP HANA In-Memory database reads data in 5 nanoseconds.
It means, memory reads in HANA database are 1 million times faster than a conventional database hard disk memory reads.
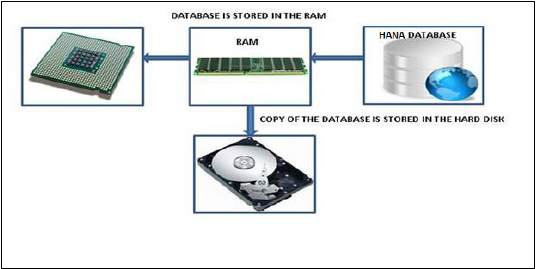
Analysts want to see current data immediately in real time and do not want to wait for data until it is loaded to SAP BW system. SAP HANA In-Memory processing allows loading of real time data with use of various data provisioning techniques.
Advantages of In-Memory Database
HANA database takes advantage of in-memory processing to deliver the fastest data-retrieval speeds, which is enticing to companies struggling with high-scale online transactions or timely forecasting and planning.
Disk-based storage is still the enterprise standard and price of RAM has been declining steadily, so memory-intensive architectures will eventually replace slow, mechanical spinning disks and will lower the cost of data storage.
In-Memory Column-based storage provides data compression up to 11 times, thus, reducing the storage space of huge data.
This speed advantages offered by RAM storage system are further enhanced by the use of multi-core CPUs, multiple CPUs per node and multiple nodes per server in a distributed environment.
