- ML - Home
- ML - Introduction
- ML - Getting Started
- ML - Basic Concepts
- ML - Ecosystem
- ML - Python Libraries
- ML - Applications
- ML - Life Cycle
- ML - Required Skills
- ML - Implementation
- ML - Challenges & Common Issues
- ML - Limitations
- ML - Reallife Examples
- ML - Data Structure
- ML - Mathematics
- ML - Artificial Intelligence
- ML - Neural Networks
- ML - Deep Learning
- ML - Getting Datasets
- ML - Categorical Data
- ML - Data Loading
- ML - Data Understanding
- ML - Data Preparation
- ML - Models
- ML - Supervised Learning
- ML - Unsupervised Learning
- ML - Semi-supervised Learning
- ML - Reinforcement Learning
- ML - Supervised vs. Unsupervised
- Machine Learning Data Visualization
- ML - Data Visualization
- ML - Histograms
- ML - Density Plots
- ML - Box and Whisker Plots
- ML - Correlation Matrix Plots
- ML - Scatter Matrix Plots
- Statistics for Machine Learning
- ML - Statistics
- ML - Mean, Median, Mode
- ML - Standard Deviation
- ML - Percentiles
- ML - Data Distribution
- ML - Skewness and Kurtosis
- ML - Bias and Variance
- ML - Hypothesis
- Regression Analysis In ML
- ML - Regression Analysis
- ML - Linear Regression
- ML - Simple Linear Regression
- ML - Multiple Linear Regression
- ML - Polynomial Regression
- Classification Algorithms In ML
- ML - Classification Algorithms
- ML - Logistic Regression
- ML - K-Nearest Neighbors (KNN)
- ML - Naïve Bayes Algorithm
- ML - Decision Tree Algorithm
- ML - Support Vector Machine
- ML - Random Forest
- ML - Confusion Matrix
- ML - Stochastic Gradient Descent
- Clustering Algorithms In ML
- ML - Clustering Algorithms
- ML - Centroid-Based Clustering
- ML - K-Means Clustering
- ML - K-Medoids Clustering
- ML - Mean-Shift Clustering
- ML - Hierarchical Clustering
- ML - Density-Based Clustering
- ML - DBSCAN Clustering
- ML - OPTICS Clustering
- ML - HDBSCAN Clustering
- ML - BIRCH Clustering
- ML - Affinity Propagation
- ML - Distribution-Based Clustering
- ML - Agglomerative Clustering
- Dimensionality Reduction In ML
- ML - Dimensionality Reduction
- ML - Feature Selection
- ML - Feature Extraction
- ML - Backward Elimination
- ML - Forward Feature Construction
- ML - High Correlation Filter
- ML - Low Variance Filter
- ML - Missing Values Ratio
- ML - Principal Component Analysis
- Reinforcement Learning
- ML - Reinforcement Learning Algorithms
- ML - Exploitation & Exploration
- ML - Q-Learning
- ML - REINFORCE Algorithm
- ML - SARSA Reinforcement Learning
- ML - Actor-critic Method
- ML - Monte Carlo Methods
- ML - Temporal Difference
- Deep Reinforcement Learning
- ML - Deep Reinforcement Learning
- ML - Deep Reinforcement Learning Algorithms
- ML - Deep Q-Networks
- ML - Deep Deterministic Policy Gradient
- ML - Trust Region Methods
- Quantum Machine Learning
- ML - Quantum Machine Learning
- ML - Quantum Machine Learning with Python
- Machine Learning Miscellaneous
- ML - Performance Metrics
- ML - Automatic Workflows
- ML - Boost Model Performance
- ML - Gradient Boosting
- ML - Bootstrap Aggregation (Bagging)
- ML - Cross Validation
- ML - AUC-ROC Curve
- ML - Grid Search
- ML - Data Scaling
- ML - Train and Test
- ML - Association Rules
- ML - Apriori Algorithm
- ML - Gaussian Discriminant Analysis
- ML - Cost Function
- ML - Bayes Theorem
- ML - Precision and Recall
- ML - Adversarial
- ML - Stacking
- ML - Epoch
- ML - Perceptron
- ML - Regularization
- ML - Overfitting
- ML - P-value
- ML - Entropy
- ML - MLOps
- ML - Data Leakage
- ML - Monetizing Machine Learning
- ML - Types of Data
- Machine Learning - Resources
- ML - Quick Guide
- ML - Cheatsheet
- ML - Interview Questions
- ML - Useful Resources
- ML - Discussion
Machine Learning - Ecosystem
Python has become one of the most popular programming languages for machine learning due to its simplicity, versatility, and extensive ecosystem of libraries and tools. There are various programming languages such as Java, C++, Lisp, Julia, Python, etc., that can be used in machine learning. Among them, Python programming language has gained a huge popularity.
Here, we will explore the Python ecosystem for machine learning and highlight some of the most popular libraries and frameworks.
Python Machine Learning Ecosystem
The machine learning ecosystem refers to the collection of tools and technologies that are used to develop the machine learning applications. Python provides various libraries and tools that form the components of Python machine learning ecosystem. These useful components make Python an important language for Machine Learning & Data Science. Though there are many such components, let us discuss some of the importance components of Python ecosystem here −
- Programming Language: Python
- Integrated Development Environment
- Python Libraries
Programming Language: Python
The programming languages such are the important components of any development ecosystem. Python programming language is extensively used in machine learning and data science.
Let's discuss why Python is the best choice for machine learning.
Why Python for Machine Learning?
According to Stack OverFlow Developer Survey 2023, Python is third most popular programming language as well as the most popular language for machine learning and data science. The following are the features of Python that makes it the preferred choice of language for data science −
Extensive set of packages
Python has an extensive and powerful set of packages which are ready to be used in various domains. It also has packages like numpy, scipy, pandas, scikit-learn etc. which are required for machine learning and data science.
Easy prototyping
Another important feature of Python that makes it the choice of language for data science is the easy and fast prototyping. This feature is useful for developing new algorithm.
Collaboration feature
The field of data science basically needs good collaboration and Python provides many useful tools that make this extremely.
One language for many domains
A typical data science project includes various domains like data extraction, data manipulation, data analysis, feature extraction, modelling, evaluation, deployment and updating the solution. As Python is a multi-purpose language, it allows the data scientist to address all these domains from a common platform.
Strengths and Weaknesses of Python
Every programming language has some strengths as well as weaknesses, so does Python too.
Strengths
According to studies and surveys, Python is the fifth most important language as well as the most popular language for machine learning and data science. It is because of the following strengths that Python has −
Easy to learn and understand − The syntax of Python is simpler; hence it is relatively easy, even for beginners also, to learn and understand the language.
Multi-purpose language − Python is a multi-purpose programming language because it supports structured programming, object-oriented programming as well as functional programming.
Huge number of modules − Python has huge number of modules for covering every aspect of programming. These modules are easily available for use hence making Python an extensible language.
Support of open source community − As being open source programming language, Python is supported by a very large developer community. Due to this, the bugs are easily fixed by the Python community. This characteristic makes Python very robust and adaptive.
Scalability − Python is a scalable programming language because it provides an improved structure for supporting large programs than shell-scripts.
Weakness
Although Python is a popular and powerful programming language, it has its own weakness of slow execution speed.
The execution speed of Python is slow as compared to compiled languages because Python is an interpreted language. This can be the major area of improvement for Python community.
Installing Python
For working in Python, we must first have to install it. You can perform the installation of Python in any of the following two ways −
Installing Python individually
Using Pre-packaged Python distribution − Anaconda
Let us discuss these each in detail.
Installing Python Individually
If you want to install Python on your computer, then then you need to download only the binary code applicable for your platform. Python distribution is available for Windows, Linux and Mac platforms.
The following is a quick overview of installing Python on the above-mentioned platforms −
On Unix and Linux platform
With the help of following steps, we can install Python on Unix and Linux platform −
First, go to www.python.org/downloads/.
Next, click on the link to download zipped source code available for Unix/Linux.
Now, Download and extract files.
-
Next, we can edit the Modules/Setup file if we want to customize some options.
Next, write the command run ./configure script
make
make install
On Windows platform
With the help of following steps, we can install Python on Windows platform −
First, go to www.python.org/downloads/.
Next, click on the link for Windows installer python-XYZ.msi file. Here XYZ is the version we wish to install.
Now, we must run the file that is downloaded. It will take us to the Python install wizard, which is easy to use. Now, accept the default settings and wait until the install is finished.
On Macintosh platform
For Mac OS X, Homebrew, a great and easy to use package installer is recommended to install Python 3. In case if you don't have Homebrew, you can install it with the help of following command −
$ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
It can be updated with the command below −
$ brew update
Now, to install Python3 on your system, we need to run the following command −
$ brew install python3
Using Pre-packaged Python Distribution: Anaconda
Anaconda is a packaged compilation of Python which have all the libraries widely used in Data science. We can follow the following steps to setup Python environment using Anaconda −
Step 1 − First, we need to download the required installation package from Anaconda distribution. The link for the same is www.anaconda.com/distribution/. You can choose from Windows, Mac and Linux OS as per your requirement.
Step 2 − Next, select the Python version you want to install on your machine. The latest Python version is 3.7. There you will get the options for 64-bit and 32-bit Graphical installer both.
Step 3 − After selecting the OS and Python version, it will download the Anaconda installer on your computer. Now, double click the file and the installer will install Anaconda package.
Step 4 − For checking whether it is installed or not, open a command prompt and type Python.
Integrated Development Environment
An Integrated Development Environment (IDE) is a software tool that combines standard developer tools into a single user-friendly interface (Graphical User interface). There are many popular IDEs that are used in machine learning and data science related development. Some of them are as follow −
- Jupyter Notebook
- PyCharm
- Visual Studio Code
- Spyder
- Sublime Text
- Atom
- Thonny
- Google Colab Notebook
Here, we will discuss in detail about the Jupyter notebook. You can visit to the respective official websites for the particular IDEs for more details such how to download, install and use them.
Jupyter Notebook
Jupyter notebooks basically provides an interactive computational environment for developing Python based Data Science applications. They are formerly known as ipython notebooks. The following are some of the features of Jupyter notebooks that makes it one of the best components of Python ML ecosystem −
Jupyter notebooks can illustrate the analysis process step by step by arranging the stuff like code, images, text, output etc. in a step by step manner.
It helps a data scientist to document the thought process while developing the analysis process.
One can also capture the result as the part of the notebook.
With the help of jupyter notebooks, we can share our work with a peer also.
Installation and Execution
If you are using Anaconda distribution, then you need not install jupyter notebook separately as it is already installed with it. You just need to go to Anaconda Prompt and type the following command −
C:\>jupyter notebook
After pressing enter, it will start a notebook server at localhost:8888 of your computer. It is shown in the following screen shot −
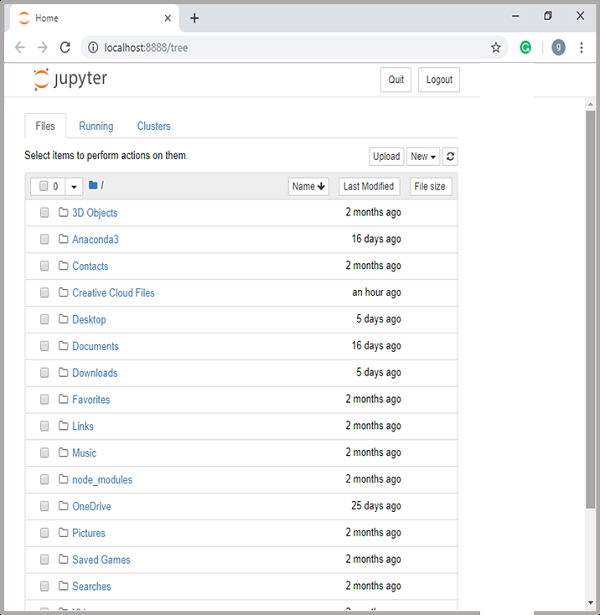
Now, after clicking the New tab, you will get a list of options. Select Python 3 and it will take you to the new notebook for start working in it. You will get a glimpse of it in the following screenshots −
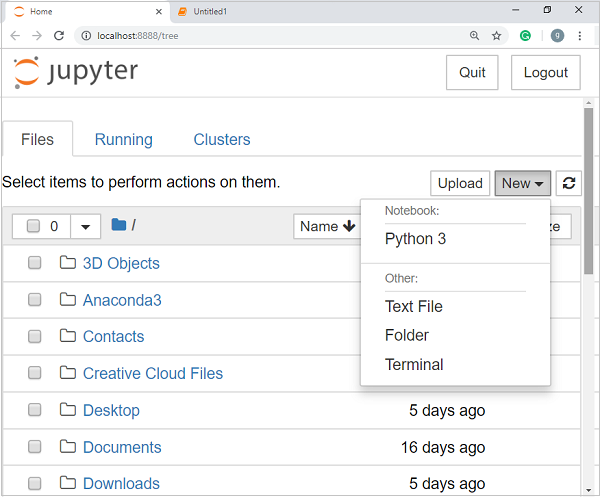
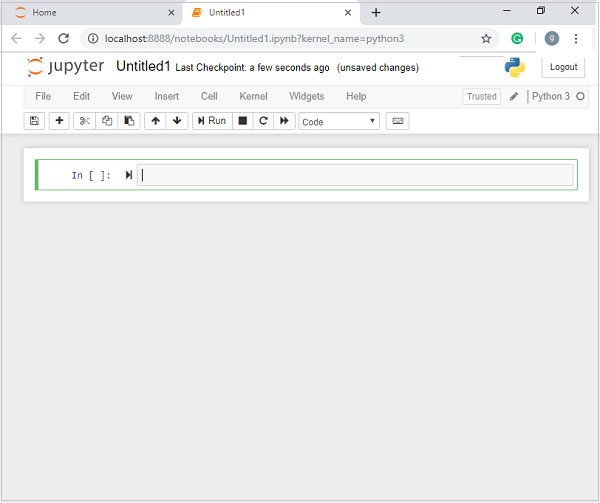
On the other hand, if you are using standard Python distribution then jupyter notebook can be installed using popular python package installer, pip.
pip3 install jupyter
Types of Cells in Jupyter Notebook
The following are the three types of cells in a jupyter notebook −
Code cells − As the name suggests, we can use these cells to write code. After writing the code/content, it will send it to the kernel that is associated with the notebook.
Markdown cells − We can use these cells for notating the computation process. They can contain the stuff like text, images, Latex equations, HTML tags etc.
Raw cells − The text written in them is displayed as it is. These cells are basically used to add the text that we do not wish to be converted by the automatic conversion mechanism of jupyter notebook.
For more detailed study of jupyter notebook, you can go to the link www.tutorialspoint.com/jupyter/index.htm.
Python Libraries and Packages
Python ecosystem has a huge collection of libraries and packages that help developers to build easily and quickly machine learning models. We have discussed here some of them as follows −
NumPy
NumPy is a fundamental library for scientific computing in Python. It provides support for large, multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on them.
NumPy is a critical component of the Python machine learning ecosystem, as it provides the underlying data structure and numerical operations required for many machine learning algorithms. Below is the command to install NumPy −
pip3 install numpy
Pandas
Pandas is a powerful library for data manipulation and analysis. It provides a range of functions for importing, cleaning, and transforming data, along with powerful tools for grouping and aggregating data.
Pandas is particularly useful for data preprocessing in machine learning, as it allows for efficient data handling and manipulation. Below is the command to install Pandas −
pip3 install pandas
Scikit-learn
Scikit-learn is a popular machine learning library in Python, providing a range of algorithms for classification, regression, clustering, and more. It also includes tools for data preprocessing, feature selection, and model evaluation. Scikit-learn is widely used in the machine learning community due to its ease of use, performance, and extensive documentation.
Below is the command to install Scikit-learn −
pip3 install scikit-learn
TensorFlow
TensorFlow is an open-source library for machine learning developed by Google. It provides support for building and training deep learning models, along with tools for distributed computing and deployment. TensorFlow is a powerful tool for building complex machine learning models, particularly in the areas of computer vision and natural language processing. Below is the command to install TensorFlow −
pip install tensorflow
PyTorch
PyTorch is another popular deep learning library in Python. Developed by Facebook, it provides a range of tools for building and training neural networks, along with support for dynamic computation graphs and GPU acceleration.
PyTorch is particularly useful for researchers and developers who need a flexible and powerful deep learning framework. Below is the command to install PyTorch −
pip install torch
Keras
Keras is a high-level neural network library that runs on top of TensorFlow and other lower-level frameworks. It provides a simple and intuitive API for building and training deep learning models, making it an excellent choice for beginners and researchers who need to quickly prototype and experiment with different models. Below is the command to install Keras −
pip3 install keras
OpenCV
OpenCV is a computer vision library that provides tools for image and video processing, along with support for machine learning algorithms. It is widely used in the computer vision community for tasks such as object detection, image segmentation, and facial recognition. Below is the command to install OpenCV −
pip3 install opencv-python
In addition to these libraries, there are many other tools and frameworks in the Python ecosystem for machine learning, including XGBoost, LightGBM, spaCy, and NLTK.
The Python ecosystem for machine learning is constantly evolving, with new libraries and tools being developed all the time.
Whether you are a beginner or an experienced machine learning practitioner, Python provides a rich and flexible environment for developing and deploying machine learning models.
Here, it is also important to note that some libraries may require additional dependencies or system-specific requirements. In such cases, it is recommended to consult the library's documentation for installation instructions and requirements.
