- ML - Home
- ML - Introduction
- ML - Getting Started
- ML - Basic Concepts
- ML - Ecosystem
- ML - Python Libraries
- ML - Applications
- ML - Life Cycle
- ML - Required Skills
- ML - Implementation
- ML - Challenges & Common Issues
- ML - Limitations
- ML - Reallife Examples
- ML - Data Structure
- ML - Mathematics
- ML - Artificial Intelligence
- ML - Neural Networks
- ML - Deep Learning
- ML - Getting Datasets
- ML - Categorical Data
- ML - Data Loading
- ML - Data Understanding
- ML - Data Preparation
- ML - Models
- ML - Supervised Learning
- ML - Unsupervised Learning
- ML - Semi-supervised Learning
- ML - Reinforcement Learning
- ML - Supervised vs. Unsupervised
- Machine Learning Data Visualization
- ML - Data Visualization
- ML - Histograms
- ML - Density Plots
- ML - Box and Whisker Plots
- ML - Correlation Matrix Plots
- ML - Scatter Matrix Plots
- Statistics for Machine Learning
- ML - Statistics
- ML - Mean, Median, Mode
- ML - Standard Deviation
- ML - Percentiles
- ML - Data Distribution
- ML - Skewness and Kurtosis
- ML - Bias and Variance
- ML - Hypothesis
- Regression Analysis In ML
- ML - Regression Analysis
- ML - Linear Regression
- ML - Simple Linear Regression
- ML - Multiple Linear Regression
- ML - Polynomial Regression
- Classification Algorithms In ML
- ML - Classification Algorithms
- ML - Logistic Regression
- ML - K-Nearest Neighbors (KNN)
- ML - Naïve Bayes Algorithm
- ML - Decision Tree Algorithm
- ML - Support Vector Machine
- ML - Random Forest
- ML - Confusion Matrix
- ML - Stochastic Gradient Descent
- Clustering Algorithms In ML
- ML - Clustering Algorithms
- ML - Centroid-Based Clustering
- ML - K-Means Clustering
- ML - K-Medoids Clustering
- ML - Mean-Shift Clustering
- ML - Hierarchical Clustering
- ML - Density-Based Clustering
- ML - DBSCAN Clustering
- ML - OPTICS Clustering
- ML - HDBSCAN Clustering
- ML - BIRCH Clustering
- ML - Affinity Propagation
- ML - Distribution-Based Clustering
- ML - Agglomerative Clustering
- Dimensionality Reduction In ML
- ML - Dimensionality Reduction
- ML - Feature Selection
- ML - Feature Extraction
- ML - Backward Elimination
- ML - Forward Feature Construction
- ML - High Correlation Filter
- ML - Low Variance Filter
- ML - Missing Values Ratio
- ML - Principal Component Analysis
- Reinforcement Learning
- ML - Reinforcement Learning Algorithms
- ML - Exploitation & Exploration
- ML - Q-Learning
- ML - REINFORCE Algorithm
- ML - SARSA Reinforcement Learning
- ML - Actor-critic Method
- ML - Monte Carlo Methods
- ML - Temporal Difference
- Deep Reinforcement Learning
- ML - Deep Reinforcement Learning
- ML - Deep Reinforcement Learning Algorithms
- ML - Deep Q-Networks
- ML - Deep Deterministic Policy Gradient
- ML - Trust Region Methods
- Quantum Machine Learning
- ML - Quantum Machine Learning
- ML - Quantum Machine Learning with Python
- Machine Learning Miscellaneous
- ML - Performance Metrics
- ML - Automatic Workflows
- ML - Boost Model Performance
- ML - Gradient Boosting
- ML - Bootstrap Aggregation (Bagging)
- ML - Cross Validation
- ML - AUC-ROC Curve
- ML - Grid Search
- ML - Data Scaling
- ML - Train and Test
- ML - Association Rules
- ML - Apriori Algorithm
- ML - Gaussian Discriminant Analysis
- ML - Cost Function
- ML - Bayes Theorem
- ML - Precision and Recall
- ML - Adversarial
- ML - Stacking
- ML - Epoch
- ML - Perceptron
- ML - Regularization
- ML - Overfitting
- ML - P-value
- ML - Entropy
- ML - MLOps
- ML - Data Leakage
- ML - Monetizing Machine Learning
- ML - Types of Data
- Machine Learning - Resources
- ML - Quick Guide
- ML - Cheatsheet
- ML - Interview Questions
- ML - Useful Resources
- ML - Discussion
Machine Learning Required Skills
Machine learning is a rapidly growing field that requires a combination of technical and soft skills to be successful. Machine learning is expanding its applications into different sectors, and choosing to become an expert in machine learning would be a wise career move. So make sure to learn all the skills that would help you improve your capabilities in pursuing machine learning as a career.
Here are some of the key skills required for machine learning −
- Programming Skills
- Statistics and Mathematics
- Data Structures
- Data Preprocessing
- Data Visualization
- Machine Learning Algorithms
- Neural Networks & Deep Learning
- Natural Language Processing
- Problem-solving Skills
- Communication Skills
- Business Acumen
The following image depicts some important skills required for machine learning −

Let us discuss each of the above skills required for machine learning in detail −
Programming Skills
Machine learning requires a solid foundation in programming skills, particularly in languages such as Python, R, and Java. Proficiency in programming allows data scientists to build, test, and deploy machine learning models.
Python is the most popular programming language due to its increased adoption of machine learning algorithms in recent years. It is ideal as it offers various libraries and packages like NumPy, Matplotlib, Sklearn, Seaborn, Keras, TensorFlow, etc., that ease the processes in machine learning. Following are some basics of Python that would help you understand machine learning algorithms −
- Basic data types, Dictionaries, Lists, Sets
- Loops and Conditional statements
- Functions
- List comprehensions
R programming is another popular programming language in the field of machine learning. It might not be as popular as Python, but it makes heavy machine learning tasks easier. Along with learning the fundamentals of the programming language, one should also gain knowledge of the packages that the programming language offers.
Statistics and Mathematics
A strong understanding of statistics and mathematics is essential for machine learning. Data scientists must be able to understand and apply statistical models, algorithms, and methods to analyze and interpret data.
Statistics is used to make inferences in data and draw conclusions. The formulas in statistics are used to interpret data for data-driven decisions. It is broadly categorized into descriptive and inferential statistics. Descriptive analysis involves simplifying and organizing data using concepts like mean, range, variance and standard deviation. Whereas inferential analysis involves considering smaller data to draw conclusions on large datasets using concepts like hypothesis testing, null & alternative testing, etc.
A lot of mathematical formulas are used to develop machine learning algorithms and also to set parameters and evaluate performance metrics. Some concepts of mathematics that are good to know are −
- Algebra − You don't have to be an expert in all the concepts; you just need to know the basics like variables, constants and functions, linear equations, and logarithms.
- Linear algebra− It is the study of vectors and linear mapping. Get a firm grip on fundamental concepts like vectors, matrices, and eigenvalues.
- Calculus− Understand the concepts of derivatives, integrals, and gradient descent, which help to develop advanced models that identify patterns and predict outcomes.
You might be wondering how mathematics is related to machine learning algorithms. Well, an example of it is that the formula for Linear regression(a type of supervised learning algorithm) is y=ax+b, which is a linear expression in algebra.
To give you a brief idea of what skills you need to acquire, let us discuss some examples
Mathematical Notation
Most of the machine learning algorithms are heavily based on mathematics. The level of mathematics that you need to know is probably just a beginner level. What is important is that you should be able to read the notation that mathematicians use in their equations. For example - if you can read the notation and comprehend what it means, you are ready for learning machine learning. If not, you may need to brush up your mathematics knowledge.
$$f_{AN}(net-\theta)=\begin{cases}\gamma & if\:net-\theta \geq \epsilon\\net-\theta & if - \epsilon
$$\displaystyle\\\max\limits_{\alpha}\begin{bmatrix}\displaystyle\sum\limits_{i=1}^m \alpha-\frac{1}{2}\displaystyle\sum\limits_{i,j=1}^m label^\left(\begin{array}{c}i\\ \end{array}\right)\cdot\:label^\left(\begin{array}{c}j\\ \end{array}\right)\cdot\:a_{i}\cdot\:a_{j}\langle x^\left(\begin{array}{c}i\\ \end{array}\right),x^\left(\begin{array}{c}j\\ \end{array}\right)\rangle \end{bmatrix}$$
$$f_{AN}(net-\theta)=\left(\frac{e^{\lambda(net-\theta)}-e^{-\lambda(net-\theta)}}{e^{\lambda(net-\theta)}+e^{-\lambda(net-\theta)}}\right)\;$$
Probability Theory
Probability is another important fundamental pre-requisite since machine learning is all about making machines learn how to predict. Major concepts in probability that one should be familiar with are random variables, probability density or distribution, etc.
Here is an example to test your current knowledge of probability theory: Classifying with conditional probabilities.
$$p(c_{i}|x,y)\;=\frac{p(x,y|c_{i})\;p(c_{i})\;}{p(x,y)\;}$$
With these definitions, we can define s Bayesian classification rule −
- If P(c1|x, y) > P(c2|x, y) , the class is c1 .
- If P(c1|x, y) < P(c2|x, y) , the class is c2 .
Optimization Problem
Here is an optimization function,
$$\displaystyle\\\max\limits_{\alpha}\begin{bmatrix}\displaystyle\sum\limits_{i=1}^m \alpha-\frac{1}{2}\displaystyle\sum\limits_{i,j=1}^m label^\left(\begin{array}{c}i\\ \end{array}\right)\cdot\:label^\left(\begin{array}{c}j\\ \end{array}\right)\cdot\:a_{i}\cdot\:a_{j}\langle x^\left(\begin{array}{c}i\\ \end{array}\right),x^\left(\begin{array}{c}j\\ \end{array}\right)\rangle \end{bmatrix}$$
Subject to the following constraints −
$$\alpha\geq0,and\:\displaystyle\sum\limits_{i-1}^m \alpha_{i}\cdot\:label^\left(\begin{array}{c}i\\ \end{array}\right)=0$$
If you can read and understand the above, you are all set.
Data Structures
Gaining good exposure on data structures would help solve real-world problems and build software products. Data structures help to tackle and understand complex problems in machine learning. Some concepts in data structures used in machine learning are arrays, stack, queue, binary trees, maps, etc.
Data Preprocessing
Preparing data for machine learning requires knowledge of data cleaning, data transformation, and data normalization. This involves identifying and correcting errors, missing values, and inconsistencies in the data.
Data Visualization
Data visualization is the process of creating graphical representations of data to help users understand and interpret complex data sets. Data scientists must be able to create effective visualizations that communicate insights from the data. Some data visualization tools that you have to be familiar with are Tableau, Power BI, and many more.
In many cases, you will need to understand the various types of visualization plots to understand your data distribution and interpret the results of the algorithm's output.
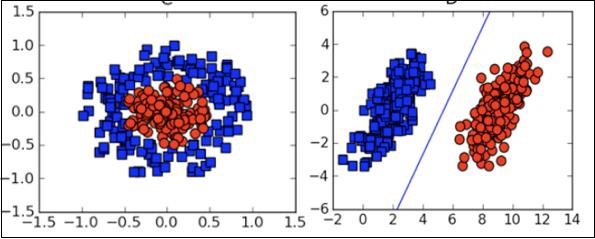
Besides the above theoretical aspects of machine learning, you need good programming skills to code those algorithms.
Machine Learning Algorithms
Machine learning requires knowledge of various algorithms, such as regression, decision trees, random forests, k-nearest neighbors, support vector machines, and neural networks. Understanding the strengths and weaknesses of these algorithms is critical for building effective machine learning models. Learning about all the algorithms would help understand where and how to apply algorithms.
Neural Networks & Deep Learning
Neural networks are algorithms designed to teach computers to possess the ability to function similarly to the human brain. It consists of interconnected nodes or neurons to learn from data.
Deep learning is a subfield of machine learning that involves training deep neural networks to analyze complex data sets. Deep learning requires a strong understanding of neural networks, convolutional neural networks, recurrent neural networks, and other related topics.
Natural Language Processing
Natural language processing (NLP) is a branch of artificial intelligence focusing on the interaction between computers and humans using natural language. NLP requires knowledge of techniques such as sentiment analysis, text classification, and named entity recognition.
Problem-solving Skills
Machine learning requires strong problem-solving skills, including the ability to identify problems, generate hypotheses, and develop solutions. Data scientists must be able to think creatively and logically to develop effective solutions to complex problems.
Communication Skills
Communication skills are essential for data scientists, as they must be able to explain complex technical concepts to non-technical stakeholders. Data scientists must be able to communicate the results of their analysis and the implications of their findings in a clear and concise manner.
Business Acumen
Machine learning is used to solve business problems, and therefore, understanding the business context and the ability to apply machine learning to business problems is essential.
Overall, machine learning requires a broad range of skills, including technical, mathematical, and soft skills. To be successful in this field, data scientists must be able to combine these skills to develop effective machine learning models that solve complex business problems.
