
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
Ensemble Classifier | Data Mining
Introduction
Ensemble Classifiers are class models that combine the predictive power of several models to generate more powerful models than individual ones. A group of classifiers is learned and the final is selected using the voting mechanism.
Data mining is the process of exploring and analyzing large datasets to find and explore important patterns, relationships, and information. The extracted information can then be used to solve business problems, predict trends and generate strategic plans by organizations. Ensemble classifiers are used in data mining to perform such tasks.
Why do we need ensemble classifiers?
Ensemble models(classifiers) can solve many problems and have several advantages over other singular methods. They are
Prediction accuracy is increased
The accuracy of the final model is higher even if the basis models fail to classify accurately.
They can be paralyzed and enables efficient resource management
Can improve on the errors produced by previous models and generate efficient models.
Types of Ensemble Classifiers in data mining
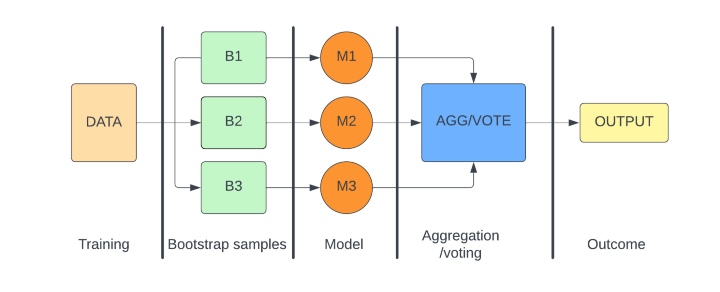
Bagging
The bagging method is known as Bootstrapped Aggregation. In the bagging method, from the original dataset, a bootstrapped subsample of data is taken and a classifier such as a decision tree is trained on it. The bootstrapping is done with replacement for other subsamples. After each of the subsamples is trained with a decision tree classifier, an algorithm is used to aggregate the results and produce a final model. This is mostly done using a majority voting mechanism. Also average can be done to generate the final result which is generally better than the individual models.
Bagging helps to reduce the variance in the model and can be used with parallel operations.
Examples of bagging classifiers are Random Forest Classifiers and Extra Tree Classifiers.
Boosting
Boosting method makes use of string and weak learners. The final model is built on several weak learners. The weak learners produce accuracy which is slightly better than random predictions and do not produce accurate results and are prone to errors and the prediction power is low. Since boosting the weak learners is used sequentially, a particular learner tries to reduce the error generated by the previous weak learner and improve accuracy. When several such learners are used they work together sequentially to produce fairly better results at the end comprising the final model.
Boosting helps to reduce the bias in the models. It cannot be used with parallel operations.
Examples of boosting methods include AdaBoost, CatBoost, and GBDT Classifiers.
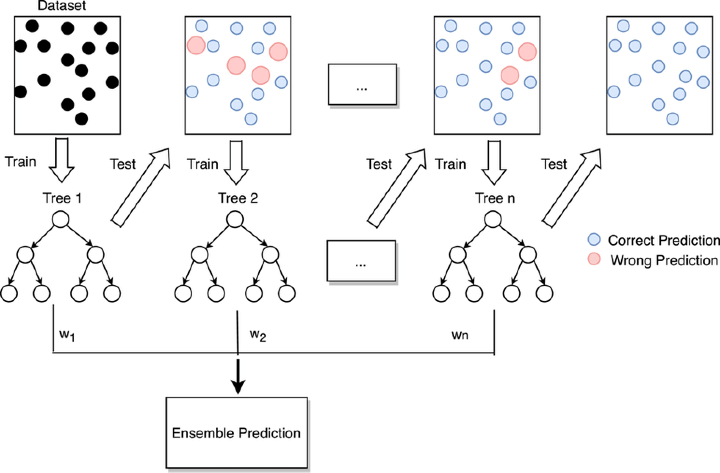
In the diagram above we have taken a dataset with train and test data.Initially we train a weak learner w1(Decision Tree Tree1)on this data. In the next step we consider the errors produced by the first model and try to improve upon the errors produced in the test by the second weak learner w2 which is trained on the errors produced by the previous model. Weak learner w2 is a trained decision tree Tree 2. This process is continued till n steps , till we reach an optimal accuracy or maximum number of steps n.
Limitations of Ensemble Classifiers
The interpretability of ensemble classifiers is low. They are hard to explain.
It requires choosing the correct base models as that can lead to low predictive accuracy than each base model.
It is a bit expensive and can consume significant time and resources in training.
Conclusion
Ensemble methods of classification became highly popular due to the use of multiple models by leveraging their predictive powers thereby producing better results in terms of accuracy. They are useful in many industries for data mining and other related applications however there are some businesses where the use of ensemble classifiers is limited, where interpretability is the key factor.

2K+ Views
