
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
Data Mining Process
The process of extracting the data from a huge dataset that can be used for analysis and benefit of the organization. Data mining process generally involves the following steps ?
Business understanding
Business understanding and client objective is necessary. Clients needs are to be defined and then using the scenario,data mining goals are defined.
Data understanding
Data is collected from different sources and explored to understand the properties and characteristics of data.
Data preparation
The data that is being collected are now selected, cleaned, transformed, preprocessed and constructed so as to make it ready for analysis. This process takes most of the project time.
Modeling
Mathematical models and algorithms are used to get data. Modeling Tcechniques or models are assessed by stakeholders to get used for dataset to obtain resutled data.
Evaluation
Result or patterns identified are evaluated to check whether it is up to mark for business objective.
Deployment
A Deployment plan is created for and reports are made to help improve business in decision making.
Data Mining Process
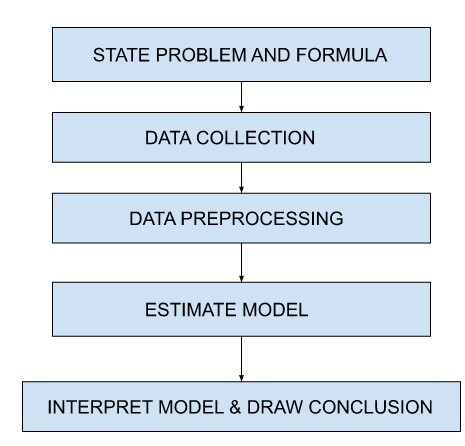
State problem and formulate hypothesis
In this part, the problem from a group is taken and initial hypothesis is applied. There is an in-depth conversation between data mining expert and application expert to formulate hypotheses and is continued during whole data mining process.
Data Collection
This step take care of how the data is collected from various sources. There are two scenarios in which the data is collected. First is when an expert controls the data generation process which is well designed and understood. Second is when experts cannot influence data generation process and an observational approach are used which randomly generates data. Data collection procedure implicit sampling distribution partially or unknown in some cases. To utilise the estimated model in final results, it is necessary to know how the data collection contradicts its distribution as the data would be used for modeling, the ultimate interpretation of result and estimating a model.
Data Preprocessing
In this process, raw data is converted into an understandable format and made ready for further analysis. The motive is to improve data quality and make it up to mark for specific tasks.
It usually have minimum two tasks ?
Outlier detection and removal
Outliers are nonspecific data which cannot be used for observation. It contains errors and abnormal values which can harm the model. It is handled by either detecting and removing outliers or by using robust modeling which are non-sensitive for outliers.
Scaling and encoding
Variable scaling and encoding are used and we need to scale them and convey equivalent weight which helps the analysis. Application-specific encoding provides smaller information by achieving dimensionality reduction.
Estimate model
This phase helps to select data mining techniques that are best suitable. Implementation is first done on different models and then the simplest one is selected for further process.
Interpret model and draw conclusions
Simple models are accountable but are less accurate. New generation data mining models are expected to provide high accuracy by using high dimensional models. Some specific techniques are used to validate results by interpreting these models.
Conclusion
This article consists of data mining process which involves steps such as business understanding, data understanding, data preparation, modeling, evaluation and deployment. The data mining process consists of 5 parts. First is State problem and formulate hypothesis which problem is taken and hypothesis is applied. Second is Data collection which help in collecting data from different sources. Third is Data preprocessing which convert data into understandable form by using outlier detection/removal, scaling and encoding. Fourth is Estimate model which help select appropriate simple model for analysis. Fifth is Interpret model and draw conclusions which refers to use model for interpretation and draw conclusion which provide high accuracy.

11K+ Views
