
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
Choosing a Classifier Based on a Training Set Data Size
For machine learning models to perform at their best, selecting the right classifier algorithm is essential. Due to the large range of approaches available, selecting the best classification algorithm could be challenging. It's important to consider a range of factors when selecting an algorithm since different algorithms work better with different types of data. One of these factors is the quantity of training data. On how effectively the classification system performs, a large training data set can have a substantial impact.
The performance of the classifier generally increases with the size of the training data set. This isn't always the case, though, since some classifiers may perform better with fewer training sets. Selecting the best method for a specific use case involves being aware of how various classifiers function with various data sizes. We'll talk about some of the most well-liked machine learning classifiers in this post and how the size of the training set affects how well they function.
1. Naive Bayes Classifier
Naive Bayes is a well-known classification technique that determines if a data point belongs to a certain class by applying Bayes' theorem. It is predicated on the idea that a feature's inclusion in a class is unrelated to the inclusion of any other feature. Due to the independence premise, the method can efficiently determine the probabilities of each character given a class, multiply those probabilities, and then get the probability of the class given the data.
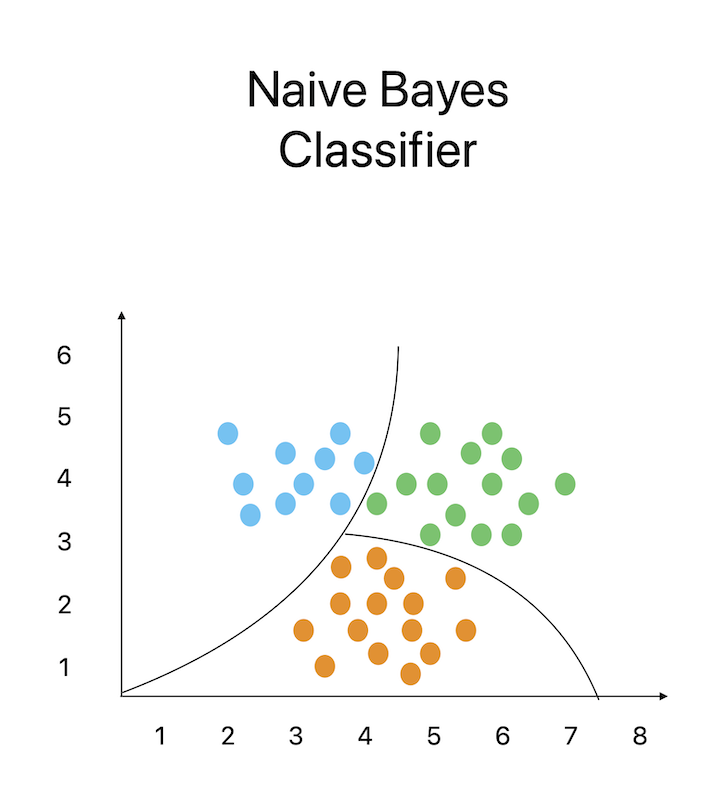
Naive Bayes is particularly useful for text classification tasks like spam filtering and sentiment analysis when the data is sparse and has a high number of features. As it can nevertheless produce reliable predictions about the relationships between classes and attributes in the lack of enough data, it is particularly suitable for small training sets. In terms of performance, Naive Bayes may be highly efficient with small training sets and produce reliable findings with minimal data. A few Naive Bayes applications include document classification, sentiment analysis, and email spam screening.
2. Decision Tree Classifier
Decision trees are a common categorization approach that employs a hierarchical structure of nodes to represent decisions and their results. Starting with the root node, which stands for the entire dataset, the algorithm performs a series of judgments depending on the values of the input attributes, dividing the data into subsets that are more homogenous with regard to the target variable. As the algorithm reaches the tree's leaves, which stand in for the final anticipated class, the splitting process is complete.
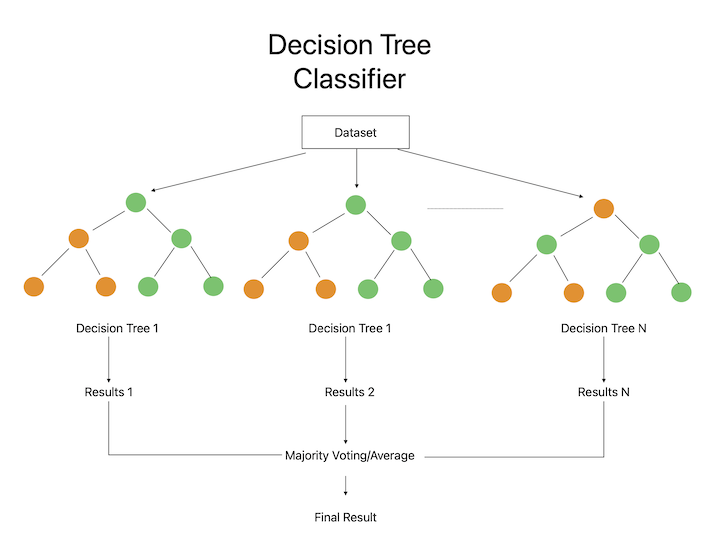
Decision trees are especially helpful for situations when there are few characteristics in the data as they can quickly identify the most crucial aspects and their connections to the target variable. They can also perform well with minimal training sets because they can find straightforward decision rules that are good at generalizing to new data. When working with complicated datasets that contain a lot of characteristics, they might, nevertheless, be vulnerable to overfitting. Credit risk analysis, client segmentation, and medical diagnosis are a few examples of decision tree applications.
3. Random Forest Classifier
The well-known categorization approach known as random forest combines a number of decision trees. By using a random subset of the input characteristics and training data, the method builds a huge number of decision trees. The final projection is then created using the sum of all the trees' projections.
Random forest is particularly useful for situations where the data contains a significant number of features since it can identify the most important qualities and capture the non-linear connections between the attributes and the target variable. It can also perform well with large training sets due to its tolerance for missing values and noisy data as well as its capacity to scale to high-dimensional data. Some use applications for random forests include generating recommendation systems, categorizing photos, and identifying fraud.
4. Support Vector Machine Classifier
A well-liked classification technique called Support Vector Machine (SVM) finds the hyperplane that optimizes the distance between the classes in order to classify data. The decision boundary separating the two classes in a binary classification job is represented by the hyperplane. The method operates by projecting the input data into a high-dimensional space, where a linear classifier can locate the hyperplane.
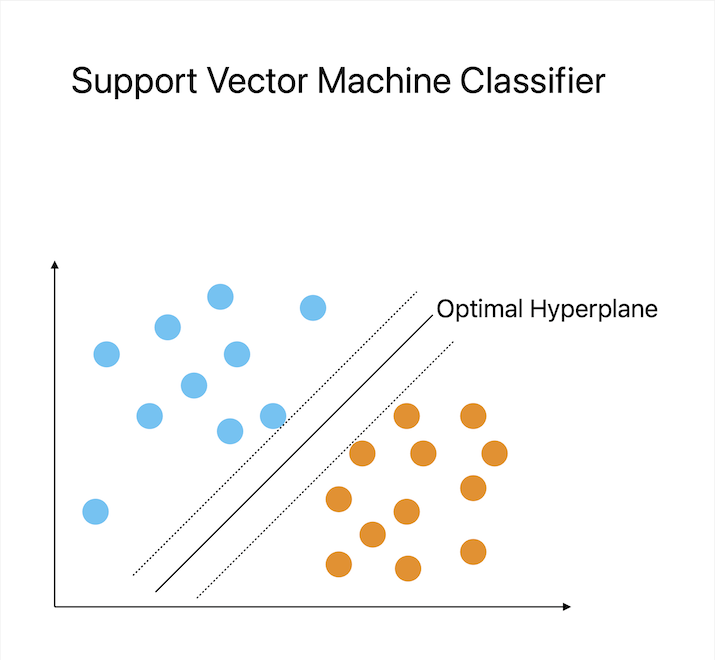
SVM is very helpful for jobs when the classes are clearly differentiated and the data comprises a moderate to high amount of characteristics. As it can recognize the most crucial properties and disregard unimportant ones, it can also perform well with training sets that range from modest to big. Via the application of kernel functions, SVM is also good at addressing non-linear correlations between the features and the target variable. Image classification, text classification, and bioinformatics are a few examples of SVM application cases.
5. Neural Network Classifier
Neural networks are machine learning algorithms inspired by the structure and function of the human brain. Many linked nodes (also known as neurons) that are arranged into layers make up a neural network. The first layer of nodes processes the input data before moving on to process the output of the one before it, and so on, with the last layer producing the network's output. During training, an optimization method like backpropagation is used to learn the weights and biases of the connections between the nodes.
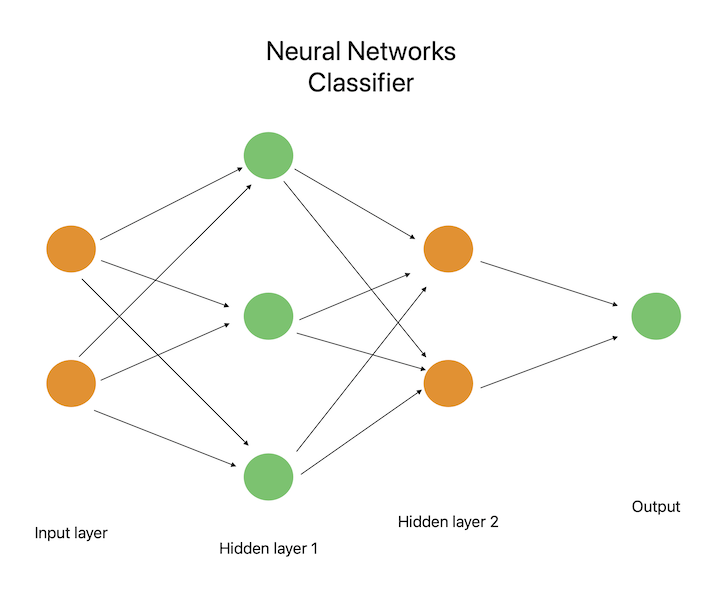
For applications that need complex and multidimensional input, including voice and picture recognition, neural networks are incredibly helpful. They also do well with big training sets because they can learn from a lot of data and recognize intricate non-linear relationships between the characteristics and the target variable. Natural language processing, speech recognition, autonomous driving, and picture categorization are some of the uses of neural networks.
Conclusion
In conclusion, the size of the training set may significantly affect how well a classifier system performs. Large training sets can increase generalization and accuracy whereas larger training sets can prevent overfitting and poor generalization. Certain algorithms, however, may work better with smaller or bigger training sets depending on the sort of data they are used with. To discover the best setup for a given job, it is crucial to experiment with a variety of algorithms and training set sizes.

1K+ Views
