- Apache Flume - Home
- Apache Flume - Introduction
- Data Transfer in Hadoop
- Apache Flume - Architecture
- Apache Flume - Data Flow
- Apache Flume - Environment
- Apache Flume - configuration
- Apache Flume - Fetching Twitter Data
- Sequence Generator Source
- Apache Flume - NetCat Source
Apache Flume - Data Flow
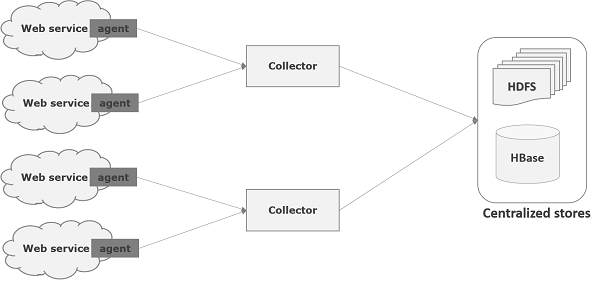
Flume is a framework which is used to move log data into HDFS. Generally events and log data are generated by the log servers and these servers have Flume agents running on them. These agents receive the data from the data generators.
The data in these agents will be collected by an intermediate node known as Collector. Just like agents, there can be multiple collectors in Flume.
Finally, the data from all these collectors will be aggregated and pushed to a centralized store such as HBase or HDFS. The following diagram explains the data flow in Flume.
Multi-hop Flow
Within Flume, there can be multiple agents and before reaching the final destination, an event may travel through more than one agent. This is known as multi-hop flow.
Fan-out Flow
The dataflow from one source to multiple channels is known as fan-out flow. It is of two types −
Replicating − The data flow where the data will be replicated in all the configured channels.
Multiplexing − The data flow where the data will be sent to a selected channel which is mentioned in the header of the event.
Fan-in Flow
The data flow in which the data will be transferred from many sources to one channel is known as fan-in flow.
Failure Handling
In Flume, for each event, two transactions take place: one at the sender and one at the receiver. The sender sends events to the receiver. Soon after receiving the data, the receiver commits its own transaction and sends a received signal to the sender. After receiving the signal, the sender commits its transaction. (Sender will not commit its transaction till it receives a signal from the receiver.)
