- Generative AI - Home
- Generative AI Basics
- Generative AI Basics
- Generative AI Evolution
- ML and Generative AI
- Generative AI Models
- Discriminative vs Generative Models
- Types of Gen AI Models
- Probability Distribution
- Probability Density Functions
- Maximum Likelihood Estimation
- Generative AI Networks
- How GANs Work?
- GAN - Architecture
- Conditional GANs
- StyleGAN and CycleGAN
- Training a GAN
- GAN Applications
- Generative AI Transformer
- Transformers in Gen AI
- Architecture of Transformers in Gen AI
- Input Embeddings in Transformers
- Multi-Head Attention
- Positional Encoding
- Feed Forward Neural Network
- Residual Connections in Transformers
- Generative AI Autoencoders
- Autoencoders in Gen AI
- Autoencoders Types and Applications
- Implement Autoencoders Using Python
- Variational Autoencoders
- Generative AI and ChatGPT
- A Generative AI Model
- Generative AI Miscellaneous
- Gen AI for Manufacturing
- Gen AI for Developers
- Gen AI for Cybersecurity
- Gen AI for Software Testing
- Gen AI for Marketing
- Gen AI for Educators
- Gen AI for Healthcare
- Gen AI for Students
- Gen AI for Industry
- Gen AI for Movies
- Gen AI for Music
- Gen AI for Cooking
- Gen AI for Media
- Gen AI for Communications
- Gen AI for Photography
How do Generative Adversarial Networks (GAN) Work?
Generative Adversarial Networks (GAN) is a powerful approach to generative modeling. GANs are based on deep neural network architecture that generates a new complex output that looks like the original training data.
GANs typically utilize architectures such as convolutional neural networks (CNN). In fact, ChatGPT, like other LLMs (Large Language Models) based on deep learning, is a remarkable application of GAN. This chapter covers all you need to know about GAN and its working.
What is a Generative Adversarial Network?
A Generative Adversarial Network (GAN) is a type of artificial intelligence framework that is used for unsupervised learning. GANs are made up of two neural networks: a Generator and a Discriminator. GANs use adversarial training to produce artificial data that resembles the actual data.
GANs can be divided to have three components −
- Generative − This component focuses on learning how to generate new data by understanding the underlying patterns in the dataset.
- Adversarial − In simple terms, "adversarial" means setting two things in opposition. In GANs, the generated data is compared to real data from the dataset. This is done using a model trained to distinguish between real and fake data. This model is known as discriminator.
- Networks − To enable the learning process, GANs uses deep neural networks.
Before getting into how GANs work, let's first discuss its two primary parts: the Generator model and the Discriminator model.
The Generator Model
The goal of the generator model is to generate new data samples that are intended to resemble real data from the dataset.
- It takes random input data as input and transforms it into synthetic data samples.
- Once transformed, the other goal of the generator is to produce data that is identical to real data when presented to the discriminator.
- The generator is implemented as a neural network model. Depending on the type of data being generated, it uses fully connected layers like Dense or Convolutional layers.
The Discriminator Model
The goal of the discriminator model is to evaluate the input data and tries to distinguish between real data samples from the dataset and fake data samples generated by the generator model.
- It takes input data and predicts whether it is real or fake.
- Another goal of the discriminator model is to correctly classify the source of the input data as real or fake.
- Like the generator model, the discriminator model is also implemented as a neural network model. It also uses Dense or Convolutional layers.
During the training of a GAN, both the generator and the discriminator are trained simultaneously but in adverse ways, i.e., in competition with each other.
How does a GAN Work?
To understand how a GAN works, first take a look at this diagram that shows how the different components of a GAN function to generate new data samples that closely resemble with real data −
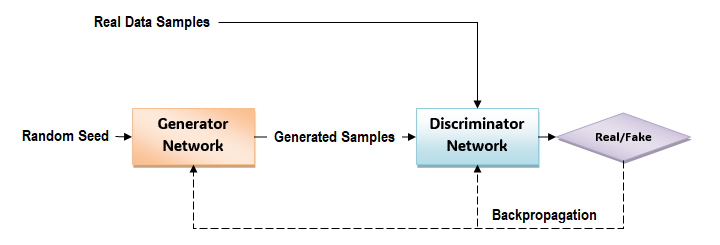
GANs have two main components: a generator network and a discriminative network. Given below are the steps involved in the working of a GAN −
Initialization
The GAN consists of two neural networks: the Generator (say G) and the Discriminator (say D).
- The goal of the generator is to generate new data samples like images or text that closely resemble the real data from the dataset.
- The discriminator, playing the role of a critic, has the goal to distinguish between the real data and the data generated by the generator.
Training Loop
The training loop involves alternating between training the generator and the discriminator.
Training the Discriminator
While training the discriminator, for each iteration −
- First, select a batch of real data samples from the dataset.
- Next, enerate a batch of fake data samples using the current generator.
- Once generated, train the discriminator on both the real and fake data samples.
- Finally, the discriminator learns to distinguish between real and fake data by adjusting its weights to minimize its classification error.
Training the Generator
While training the generator, for each iteration −
- First, generate a batch of fake data samples using the generator.
- Next, train the generator to produce fake data that the discriminator classifies as the real data. To do this, we need to pass the fake data through the discriminator and update the generator's weights based on the discriminator's classification error.
- Finally, the generator will learn to produce more realistic fake data by adjusting its weights to maximize the discriminator's error when classifying its generated samples.
Adversarial Training
As the training progresses, both the generator and discriminator improve their performance in an adversarial manner, i.e., in opposition.
The generator gets better at creating fake data that resembles real data, while the discriminator gets better at distinguishing between real and fake data.
With the help of this adversarial relationship between the generator and discriminator, both the networks try to improve continuously until the generator generates data that is identical to the real data.
Evaluation
Once the training is over, the generator can be used to generate new data samples that resemble the real data from the dataset.
We can evaluate the quality of the generated data either by inspecting samples visually or using quantitative measures like similarity scores or classifier accuracy.
Fine-Tuning and Optimization
Depending on the application, you can fine-tune the trained GAN model to improve its performance or adapt it to specific tasks or datasets.
Conclusion
Generative Adversarial Networks (GANs) is one of the most prominent and widely used generative models. In this chapter, we explained the basics of a GAN and how it works using neural networks to produce artificial data that resembles actual data.
The steps that are involved in the working of a GAN include: Initialization, Training Loop, Training the Discriminator, Training the Generator, Adversarial Training, Evaluation, and Fine tuning and Optimization.