- Weka - Home
- Weka - Introduction
- What is Weka?
- Weka - Installation
- Weka - Launching Explorer
- Weka - Loading Data
- Weka - File Formats
- Weka - Preprocessing the Data
- Weka - Classifiers
- Weka - Clustering
- Weka - Association
- Weka - Feature Selection
- Weka Useful Resources
- Weka - Quick Guide
- Weka - Useful Resources
- Weka - Discussion
Weka - Loading Data
In this chapter, we start with the first tab that you use to preprocess the data. This is common to all algorithms that you would apply to your data for building the model and is a common step for all subsequent operations in WEKA.
For a machine learning algorithm to give acceptable accuracy, it is important that you must cleanse your data first. This is because the raw data collected from the field may contain null values, irrelevant columns and so on.
In this chapter, you will learn how to preprocess the raw data and create a clean, meaningful dataset for further use.
First, you will learn to load the data file into the WEKA explorer. The data can be loaded from the following sources −
- Local file system
- Web
- Database
In this chapter, we will see all the three options of loading data in detail.
Loading Data from Local File System
Just under the Machine Learning tabs that you studied in the previous lesson, you would find the following three buttons −
- Open file ...
- Open URL ...
- Open DB ...
Click on the Open file ... button. A directory navigator window opens as shown in the following screen −
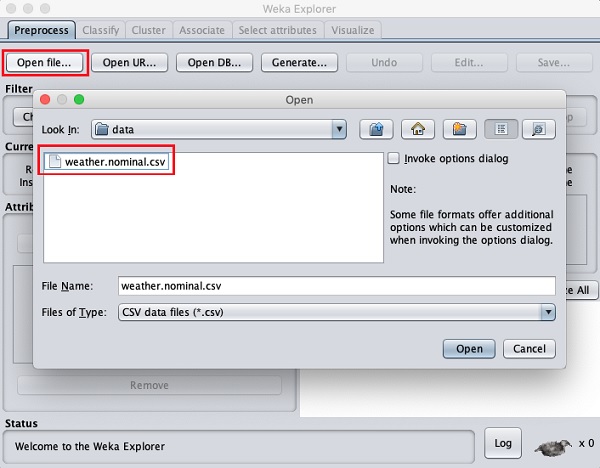
Now, navigate to the folder where your data files are stored. WEKA installation comes up with many sample databases for you to experiment. These are available in the data folder of the WEKA installation.
For learning purpose, select any data file from this folder. The contents of the file would be loaded in the WEKA environment. We will very soon learn how to inspect and process this loaded data. Before that, let us look at how to load the data file from the Web.
Loading Data from Web
Once you click on the Open URL ... button, you can see a window as follows −
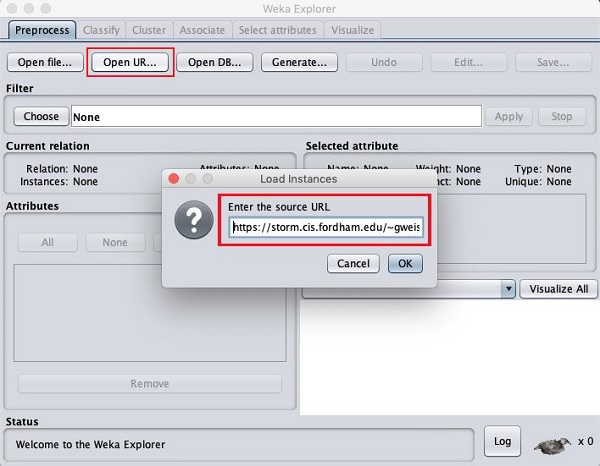
We will open the file from a public URL Type the following URL in the popup box −
https://storm.cis.fordham.edu/~gweiss/data-mining/weka-data/weather.nominal.arff
You may specify any other URL where your data is stored. The Explorer will load the data from the remote site into its environment.
Loading Data from DB
Once you click on the Open DB ... button, you can see a window as follows −
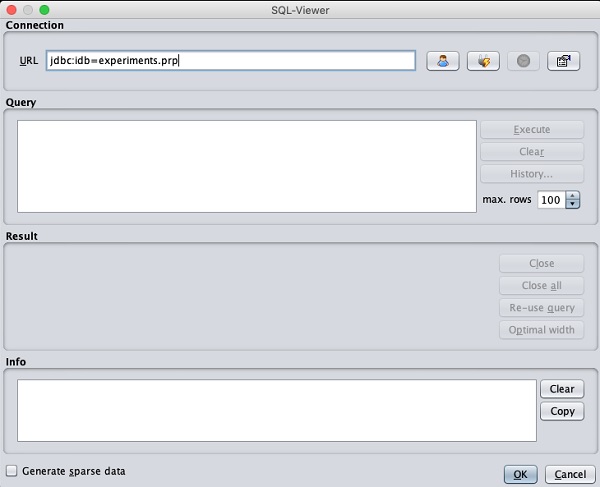
Set the connection string to your database, set up the query for data selection, process the query and load the selected records in WEKA.
