- Weka - Home
- Weka - Introduction
- What is Weka?
- Weka - Installation
- Weka - Launching Explorer
- Weka - Loading Data
- Weka - File Formats
- Weka - Preprocessing the Data
- Weka - Classifiers
- Weka - Clustering
- Weka - Association
- Weka - Feature Selection
- Weka Useful Resources
- Weka - Quick Guide
- Weka - Useful Resources
- Weka - Discussion
Weka - File Formats
WEKA supports a large number of file formats for the data. Here is the complete list −
- arff
- arff.gz
- bsi
- csv
- dat
- data
- json
- json.gz
- libsvm
- m
- names
- xrff
- xrff.gz
The types of files that it supports are listed in the drop-down list box at the bottom of the screen. This is shown in the screenshot given below.
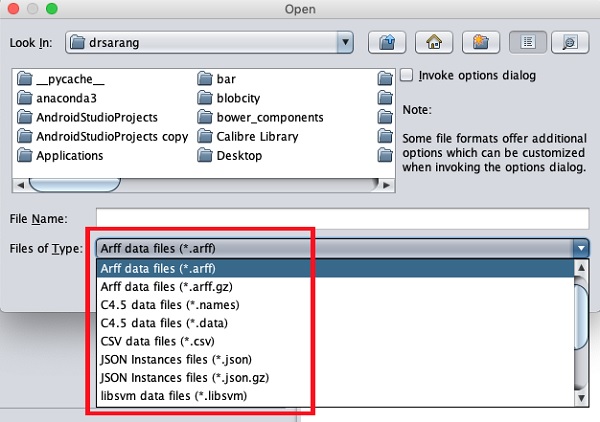
As you would notice it supports several formats including CSV and JSON. The default file type is Arff.
Arff Format
An Arff file contains two sections - header and data.
- The header describes the attribute types.
- The data section contains a comma separated list of data.
As an example for Arff format, the Weather data file loaded from the WEKA sample databases is shown below −

From the screenshot, you can infer the following points −
The @relation tag defines the name of the database.
The @attribute tag defines the attributes.
The @data tag starts the list of data rows each containing the comma separated fields.
The attributes can take nominal values as in the case of outlook shown here −
@attribute outlook (sunny, overcast, rainy)
The attributes can take real values as in this case −
@attribute temperature real
You can also set a Target or a Class variable called play as shown here −
@attribute play (yes, no)
The Target assumes two nominal values yes or no.
Other Formats
The Explorer can load the data in any of the earlier mentioned formats. As arff is the preferred format in WEKA, you may load the data from any format and save it to arff format for later use. After preprocessing the data, just save it to arff format for further analysis.
Now that you have learned how to load data into WEKA, in the next chapter, you will learn how to preprocess the data.
