- Weka - Home
- Weka - Introduction
- What is Weka?
- Weka - Installation
- Weka - Launching Explorer
- Weka - Loading Data
- Weka - File Formats
- Weka - Preprocessing the Data
- Weka - Classifiers
- Weka - Clustering
- Weka - Association
- Weka - Feature Selection
- Weka Useful Resources
- Weka - Quick Guide
- Weka - Useful Resources
- Weka - Discussion
Weka - Launching Explorer
In this chapter, let us look into various functionalities that the explorer provides for working with big data.
When you click on the Explorer button in the Applications selector, it opens the following screen −
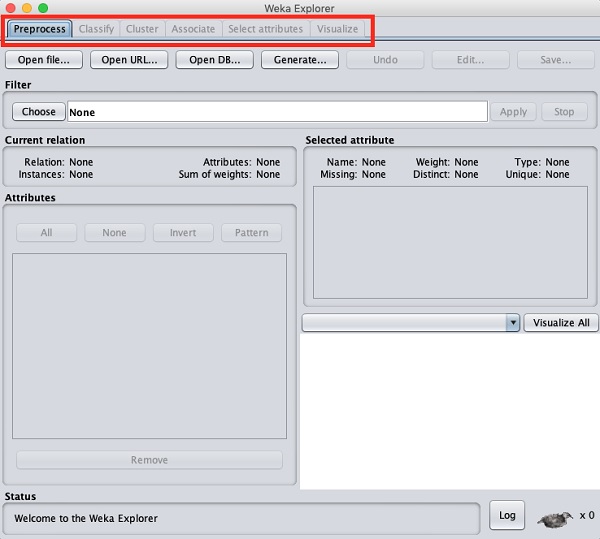
On the top, you will see several tabs as listed here −
- Preprocess
- Classify
- Cluster
- Associate
- Select Attributes
- Visualize
Under these tabs, there are several pre-implemented machine learning algorithms. Let us look into each of them in detail now.
Preprocess Tab
Initially as you open the explorer, only the Preprocess tab is enabled. The first step in machine learning is to preprocess the data. Thus, in the Preprocess option, you will select the data file, process it and make it fit for applying the various machine learning algorithms.
Classify Tab
The Classify tab provides you several machine learning algorithms for the classification of your data. To list a few, you may apply algorithms such as Linear Regression, Logistic Regression, Support Vector Machines, Decision Trees, RandomTree, RandomForest, NaiveBayes, and so on. The list is very exhaustive and provides both supervised and unsupervised machine learning algorithms.
Cluster Tab
Under the Cluster tab, there are several clustering algorithms provided - such as SimpleKMeans, FilteredClusterer, HierarchicalClusterer, and so on.
Associate Tab
Under the Associate tab, you would find Apriori, FilteredAssociator and FPGrowth.
Select Attributes Tab
Select Attributes allows you feature selections based on several algorithms such as ClassifierSubsetEval, PrinicipalComponents, etc.
Visualize Tab
Lastly, the Visualize option allows you to visualize your processed data for analysis.
As you noticed, WEKA provides several ready-to-use algorithms for testing and building your machine learning applications. To use WEKA effectively, you must have a sound knowledge of these algorithms, how they work, which one to choose under what circumstances, what to look for in their processed output, and so on. In short, you must have a solid foundation in machine learning to use WEKA effectively in building your apps.
In the upcoming chapters, you will study each tab in the explorer in depth.
