- Serverless - Home
- Serverless - Introduction
- Serverless - Installation
- Serverless - Deploying Function
- Serverless - Regions, Memory-Size, Timeouts
- Serverless - Service
- Serverless - Scheduled Lambdas
- Serverless - API Gateway Triggered Lambdas
- Serverless - Include/Exclude
- Serverless - Plugins
- Serverless - Packaging Dependencies
- Serverless - Layer Creation
- Serverless - REST API with DynamoDB
- Serverless - Telegram Echo Bot
- Serverless Useful Resources
- Serverless - Quick Guide
- Serverless - Useful Resources
- Serverless - Discussion
Serverless - Layer Creation
What are layers?
Layers are a way of isolating code blocks. Say you want to import the NumPy library in your application. You trust the library and there's hardly any chance that you will be making changes in the source code of that library. Therefore, you won't like it if the source code of NumPy clutters your application workspace. Speaking very crudely, you would simply want NumPy to sit somewhere else, isolated from your application code. Layers allow you to do exactly that. You can simply bundle all your dependencies (NumPy, Pandas, SciPy, etc.) in a separate layer, and then simply reference that layer in your lambda function within serverless. And boom! All the libraries bundled within that layer can now be imported into your application. At the same time, your application workspace remains completely uncluttered. You simply see the application code to edit.

Photo by Iva Rajovic on Unsplash, indicative of code separation in layers
The really cool thing about layers is that they can be shared across functions. Say you deployed a lambda function with a python-requirements layer that contains NumPy and Pandas. Now, if another lambda function requires NumPy, you need not deploy a separate layer for this function. You can simply use the layer of the previous function and it will work well with the new function as well.
This will save you a lot of precious time during deployment. After all, you will be deploying only the application code. The dependencies are already present in an existing layer. Therefore,several developers keep the dependencies layer in a separate stack. They then use this layer in all other applications. This way, they don't need to deploy the dependencies again and again. After all, the dependencies are quite heavy. NumPy library itself is approx. 80 MB large. Deploying dependencies every time you make changes to your application code (which may measure just a few KBs) will be quite inconvenient.
And adding a dependencies layer is just one example. There are several other use-cases. For example, the example given on serverless.com concerns the creation of GIFs using the FFmpeg tool. In that example, they have stored the FFmpeg tool in a layer. In all, AWS Lambda allows us to add a maximum of 5 layers per function. The only condition is that the total size of the 5 layers and the application should be less than 250 MB.
Creating python-requirements layer
Now let's see how the layer containing all the dependencies can be created and deployed using serverless. To do that, we need the serverless-python-requirements plugin.This plugin only works with Serverless 1.34 and above. So you may want to upgrade your Serverless version if you have a version <1.34. You can install the plugin using −
sls plugin install -n serverless-python-requirements
Next, you add this plugin in the plugins section of your serverless.yml, and mention it's configurations in the custom section −
plugins:
- serverless-python-requirements
custom:
pythonRequirements:
dockerizePip: true
layer: true
Over here, dockerizePip − true enables the usage of docker and allows you to package all the dependencies in a docker container. We've discussed about packaging using docker in the previous chapter. layer − true tells serverless that the python requirements should be stored in a separate layer. Now, at this point, you may be wondering that how does serverless understand which dependencies to package? The answer, as mentioned in the plugins chapter, lies in the requirements.txt file.
Once the layer plugin and custom configurations have been defined, you can add the layer to your individual functions within serverless as follows −
functions:
hello:
handler: handler.hello
layers:
- { Ref: PythonRequirementsLambdaLayer }
The keyword PythonRequirementsLambdaLayer comes from the CloudFormation Reference.In general, it is derived from the layer's name. The syntax is 'LayerNameLambdaLayer' (TitleCased, without spaces). In our case, since the layer name is python requirements, the reference becomes PythonRequirementsLambdaLayer. If you aren't sure about the name of your lambda layer, you can get it in the following steps −
Run sls package
Open .serverless/cloudformation-template-update-stack.json
Search for 'LambdaLayer'
Using an existing layer from another function in the same region
Like I mentioned in the beginning, a really cool thing about layers is the ability to use existing layers in your function. This can be done easily by using the ARN of your existing layer.The syntax to add an existing layer to a function using the ARN is quite straightforward −
functions:
hello:
handler: handler.hello
layers:
- arn:aws:lambda:region:XXXXXX:layer:LayerName:Y
That's it. Now the layer with the specified ARN will work with your function. If the layer contains the NumPy library, you can simply go ahead and call import numpy in your 'hello' function. It will run without any error.
If you are wondering from where you can get the ARN, it is quite simple actually. Simply navigate to the function containing the layer in the AWS Console, and click on 'Layers'.
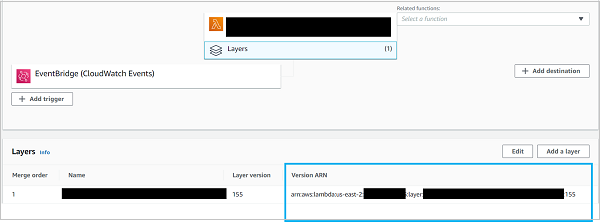
Of course, if the layer doesn't belong to your account, then it either needs to be publicly shared or shared specifically with your account. More on that later.
Also, keep in mind that the layer should be compatible with your application. Don't expect a layer compatible with node.js runtime to run with a function created in python3.6 runtime.
Non-requirements/ generic layers
As mentioned in the beginning, the layers serve the main function of isolating your code blocks. Therefore, they don't need to contain just dependencies. They can contain any piece of code that you specify. Calling layer: true within pythonRequirements within custom is a kind of a shortcut made possible by the serverless-python-requirements plugin. However, to create a generic layer, the syntax within serverless.yml, as explained in the serverless docs, is as follows −
layers:
hello:
path: layer-dir # required, path to layer contents on disk
name: ${opt:stage, self:provider.stage, 'dev'}-layerName # optional, Deployed Lambda layer name
description: Description of what the lambda layer does # optional, Description to publish to AWS
compatibleRuntimes: # optional, a list of runtimes this layer is compatible with
- python3.8
licenseInfo: GPLv3 # optional, a string specifying license information
# allowedAccounts: # optional, a list of AWS account IDs allowed to access this layer.
# - '*'
# note: uncommenting this will give all AWS users access to this layer unconditionally.
retain: false # optional, false by default. If true, layer versions are not deleted as new ones are created
The various configuration parameters are self-explanatory thanks to the comments provided. Except for the 'path', all other properties are optional. The path property is a path to a directory of your choice that you want to be isolated from your application code. It will be zipped up and published as your layer. For instance, in the example project on serverless, where they host the FFmpeg tool in a layer, they download the tool in a separate folder called 'layer' and specify that in the path property.
layers:
ffmpeg:
path: layer
As told before, we can add up to 5 layers within the layers − property.
To use these generic layers in your functions, again, you can use either the CloudFormation reference or specify the ARN.
Allowing other accounts to access layers
More accounts can be provided access to your layer by simply mentioning the account numbers in the 'allowedAccounts' property. For example −
layers:
testLayer:
path: testLayer
allowedAccounts:
- 999999999999 # a specific account ID
- 000123456789 # a different specific account ID
If you want the layer to be publicly accessible, you can add '*' in allowedAccounts −
layers:
testLayer:
path: testLayer
allowedAccounts:
- '*'
References
