- OBIEE - Home
- OBIEE - Data Warehouse
- OBIEE - Dimensional Modeling
- OBIEE - Schema
- OBIEE - Basics
- OBIEE - Components
- OBIEE - Architecture
- OBIEE - Repositories
- OBIEE - Business Layer
- OBIEE - Presentation Layer
- OBIEE - Testing Repository
- OBIEE - Multiple Logical Table
- OBIEE - Calculation Measures
- OBIEE - Dimension Hierarchies
- OBIEE - Level-Based Measures
- OBIEE - Aggregates
- OBIEE - Variables
- OBIEE - Dashboards
- OBIEE - Filters
- OBIEE - Views
- OBIEE - Prompts
- OBIEE - Security
- OBIEE - Administration
OBIEE Schema
Schema is a logical description of the entire database. It includes the name and description of records of all types including all associated data-items and aggregates. Much like a database, DW also requires to maintain a schema. Database uses relational model, while DW uses Star, Snowflake, and Fact Constellation schema (Galaxy schema).
Star Schema
In a Star Schema, there are multiple dimension tables in de-normalized form that are joined to only one fact table. These tables are joined in a logical manner to meet some business requirement for analysis purpose. These schemas are multidimensional structures which are used to create reports using BI reporting tools.
Dimensions in Star schemas contain a set of attributes and Fact tables contain foreign keys for all dimensions and measurement values.
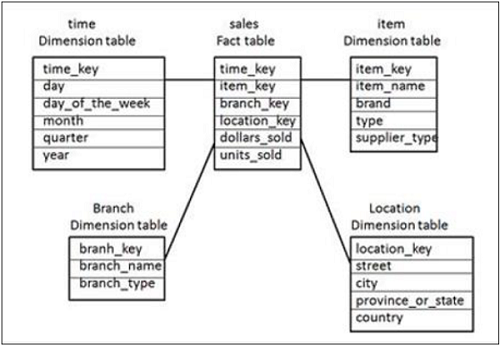
In the above Star Schema, there is a fact table Sales Fact at the center and is joined to 4 dimension tables using primary keys. Dimension tables are not further normalized and this joining of tables is known as Star Schema in DW.
Fact table also contains measure values − dollar_sold and units_sold.
Snowflakes Schema
In a Snowflakes Schema, there are multiple dimension tables in normalized form that are joined to only one fact table. These tables are joined in a logical manner to meet some business requirement for analysis purpose.
Only difference between a Star and Snowflakes schema is that dimension tables are further normalized. The normalization splits up the data into additional tables. Due to normalization in the Snowflake schema, the data redundancy is reduced without losing any information and therefore it becomes easy to maintain and saves storage space.
In above Snowflakes Schema example, Product and Customer table are further normalized to save storage space. Sometimes, it also provides performance optimization when you execute a query that requires processing of rows directly in normalized table so it doesnt process rows in primary Dimension table and comes directly to Normalized table in Schema.
Granularity
Granularity in a table represents the level of information stored in the table. High granularity of data means that data is at or near the transaction level, which has more detail. Low granularity means that data has low level of information.
A fact table is usually designed at a low level of granularity. This means that we need to find the lowest level of information that can be stored in a fact table. In date dimension, the granularity level could be year, month, quarter, period, week, and day.
The process of defining granularity consists of two steps −
- Determining the dimensions that are to be included.
- Determining the location to place the hierarchy of each dimension of information.
Slowly Changing Dimensions
Slowly changing dimensions refer to changing value of an attribute over time. It is one of the common concepts in DW.
Example
Andy is an employee of XYZ Inc. He was first located in New York City in July 2015. Original entry in the employee lookup table has the following record −
| Employee ID | 10001 |
|---|---|
| Name | Andy |
| Location | New York |
At a later date, he has relocated to LA, California. How should XYZ Inc. now modify its employee table to reflect this change?
This is known as "Slowly Changing Dimension" concept.
There are three ways to solve this type of problem −
Solution 1
The new record replaces the original record. No trace of the old record exists.
Slowly Changing Dimension, the new information simply overwrites the original information. In other words, no history is kept.
| Employee ID | 10001 |
|---|---|
| Name | Andy |
| Location | LA, California |
Benefit − This is the easiest way to handle the Slowly Changing Dimension problem as there is no need to keep track of the old information.
Disadvantage − All historical information is lost.
Use − Solution 1 should be used when it is not required for DW to keep track of historical information.
Solution 2
A new record is entered into the Employee dimension table. So the employee, Andy, is treated as two people.
A new record is added to the table to represent the new information and both the original and new record will be present. The new record gets its own primary key as follows −
| Employee ID | 10001 | 10002 |
|---|---|---|
| Name | Andy | Andy |
| Location | New York | LA, California |
Benefit − This method allows us to store all the historical information.
Disadvantage − Size of the table grows faster. When the number of rows for the table is very high, space and performance of table can be a concern.
Use − Solution 2 should be used when it is necessary for DW to keep historical data.
Solution 3
The original record in Employee dimension is modified to reflect the change.
There will be two columns to indicate the particular attribute, one indicates original value and other indicates the new value. There will also be a column that indicates when the current value becomes active.
| Employee ID | Name | Original Location | New Location | Date Moved |
|---|---|---|---|---|
| 10001 | Andy | New York | LA, California | July 2015 |
Benefits − This does not increase the size of the table, since new information is updated. This allows us to keep historical information.
Disadvantage − This method doesnt keep all history when an attribute value is changed more than once.
Use − Solution 3 should only be used when it is required for DW to keep information of historical changes.
Normalization
Normalization is the process of decomposing a table into less redundant smaller tables without losing any information. So Database normalization is the process of organizing the attributes and tables of a database to minimize data redundancy (duplicate data).
Purpose of Normalization
It is used to eliminate certain types of data (redundancy/ replication) to improve consistency.
It provides maximum flexibility to meet future information needs by keeping tables corresponding to object types in their simplified forms.
It produces a clearer and readable data model.
Advantages
- Data integrity.
- Enhances data consistency.
- Reduces data redundancy and space required.
- Reduces update cost.
- Maximum flexibility in responding to ad-hoc queries.
- Reduces the total number of rows per block.
Disadvantages
Slow performance of queries in database because joins have to be performed to retrieve relevant data from several normalized tables.
You have to understand the data model in order to perform proper joins among several tables.
Example
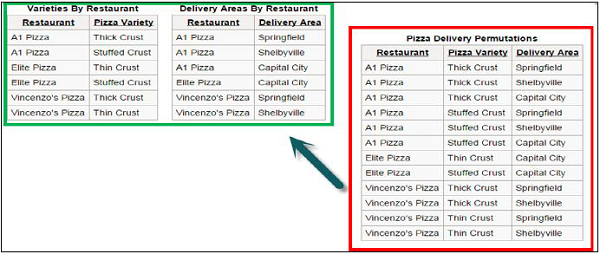
In the above example, the table inside the green block represents a normalized table of the one inside the red block. The table in green block is less redundant and also with less number of rows without losing any information.
