- Natural Language Toolkit - Home
- Natural Language Toolkit - Introduction
- Natural Language Toolkit - Getting Started
- Natural Language Toolkit - Tokenizing Text
- Training Tokenizer & Filtering Stopwords
- Looking up words in Wordnet
- Stemming & Lemmatization
- Natural Language Toolkit - Word Replacement
- Synonym & Antonym Replacement
- Corpus Readers and Custom Corpora
- Basics of Part-of-Speech (POS) Tagging
- Natural Language Toolkit - Unigram Tagger
- Natural Language Toolkit - Combining Taggers
- Natural Language Toolkit - More NLTK Taggers
- Natural Language Toolkit - Parsing
- Chunking & Information Extraction
- Natural Language Toolkit - Transforming Chunks
- Natural Language Toolkit - Transforming Trees
- Natural Language Toolkit - Text Classification
- Natural Language Toolkit Resources
- Natural Language Toolkit - Quick Guide
- Natural Language Toolkit - Useful Resources
- Natural Language Toolkit - Discussion
Natural Language Toolkit - Parsing
Parsing and its relevance in NLP
The word Parsing whose origin is from Latin word pars (which means part), is used to draw exact meaning or dictionary meaning from the text. It is also called Syntactic analysis or syntax analysis. Comparing the rules of formal grammar, syntax analysis checks the text for meaningfulness. The sentence like Give me hot ice-cream, for example, would be rejected by parser or syntactic analyzer.
In this sense, we can define parsing or syntactic analysis or syntax analysis as follows −
It may be defined as the process of analyzing the strings of symbols in natural language conforming to the rules of formal grammar.
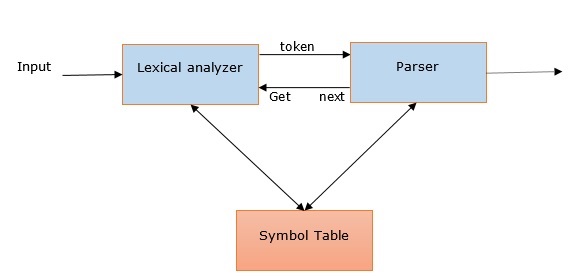
We can understand the relevance of parsing in NLP with the help of following points −
Parser is used to report any syntax error.
It helps to recover from commonly occurring error so that the processing of the remainder of program can be continued.
Parse tree is created with the help of a parser.
Parser is used to create symbol table, which plays an important role in NLP.
Parser is also used to produce intermediate representations (IR).
Deep Vs Shallow Parsing
| Deep Parsing | Shallow Parsing |
|---|---|
| In deep parsing, the search strategy will give a complete syntactic structure to a sentence. | It is the task of parsing a limited part of the syntactic information from the given task. |
| It is suitable for complex NLP applications. | It can be used for less complex NLP applications. |
| Dialogue systems and summarization are the examples of NLP applications where deep parsing is used. | Information extraction and text mining are the examples of NLP applications where deep parsing is used. |
| It is also called full parsing. | It is also called chunking. |
Various types of parsers
As discussed, a parser is basically a procedural interpretation of grammar. It finds an optimal tree for the given sentence after searching through the space of a variety of trees. Let us see some of the available parsers below −
Recursive descent parser
Recursive descent parsing is one of the most straightforward forms of parsing. Following are some important points about recursive descent parser −
It follows a top down process.
It attempts to verify that the syntax of the input stream is correct or not.
It reads the input sentence from left to right.
One necessary operation for recursive descent parser is to read characters from the input stream and matching them with the terminals from the grammar.
Shift-reduce parser
Following are some important points about shift-reduce parser −
It follows a simple bottom-up process.
It tries to find a sequence of words and phrases that correspond to the right-hand side of a grammar production and replaces them with the left-hand side of the production.
The above attempt to find a sequence of word continues until the whole sentence is reduced.
In other simple words, shift-reduce parser starts with the input symbol and tries to construct the parser tree up to the start symbol.
Chart parser
Following are some important points about chart parser −
It is mainly useful or suitable for ambiguous grammars, including grammars of natural languages.
It applies dynamic programing to the parsing problems.
Because of dynamic programing, partial hypothesized results are stored in a structure called a chart.
The chart can also be re-used.
Regexp parser
Regexp parsing is one of the mostly used parsing technique. Following are some important points about Regexp parser −
As the name implies, it uses a regular expression defined in the form of grammar on top of a POS-tagged string.
It basically uses these regular expressions to parse the input sentences and generate a parse tree out of this.
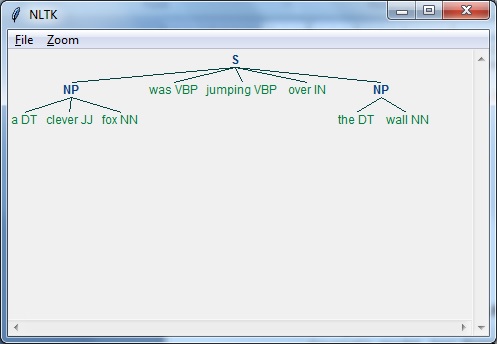
Example
Following is a working example of Regexp Parser −
import nltk
sentence = [
("a", "DT"),
("clever", "JJ"),
("fox","NN"),
("was","VBP"),
("jumping","VBP"),
("over","IN"),
("the","DT"),
("wall","NN")
]
grammar = "NP:{<DT>?<JJ>*<NN>}"
Reg_parser = nltk.RegexpParser(grammar)
Reg_parser.parse(sentence)
Output = Reg_parser.parse(sentence)
Output.draw()
Output
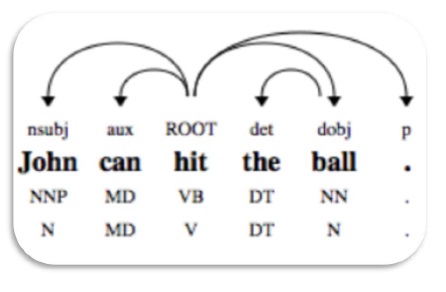
Dependency Parsing
Dependency Parsing (DP), a modern parsing mechanism, whose main concept is that each linguistic unit i.e. words relates to each other by a direct link. These direct links are actually dependencies in linguistic. For example, the following diagram shows dependency grammar for the sentence John can hit the ball.
NLTK Package
We have following the two ways to do dependency parsing with NLTK −
Probabilistic, projective dependency parser
This is the first way we can do dependency parsing with NLTK. But this parser has the restriction of training with a limited set of training data.
Stanford parser
This is another way we can do dependency parsing with NLTK. Stanford parser is a state-of-the-art dependency parser. NLTK has a wrapper around it. To use it we need to download following two things −
Language model for desired language. For example, English language model.
Example
Once you downloaded the model, we can use it through NLTK as follows −
from nltk.parse.stanford import StanfordDependencyParser
path_jar = 'path_to/stanford-parser-full-2014-08-27/stanford-parser.jar'
path_models_jar = 'path_to/stanford-parser-full-2014-08-27/stanford-parser-3.4.1-models.jar'
dep_parser = StanfordDependencyParser(
path_to_jar = path_jar, path_to_models_jar = path_models_jar
)
result = dep_parser.raw_parse('I shot an elephant in my sleep')
depndency = result.next()
list(dependency.triples())
Output
[ ((u'shot', u'VBD'), u'nsubj', (u'I', u'PRP')), ((u'shot', u'VBD'), u'dobj', (u'elephant', u'NN')), ((u'elephant', u'NN'), u'det', (u'an', u'DT')), ((u'shot', u'VBD'), u'prep', (u'in', u'IN')), ((u'in', u'IN'), u'pobj', (u'sleep', u'NN')), ((u'sleep', u'NN'), u'poss', (u'my', u'PRP$')) ]
