- Natural Language Toolkit - Home
- Natural Language Toolkit - Introduction
- Natural Language Toolkit - Getting Started
- Natural Language Toolkit - Tokenizing Text
- Training Tokenizer & Filtering Stopwords
- Looking up words in Wordnet
- Stemming & Lemmatization
- Natural Language Toolkit - Word Replacement
- Synonym & Antonym Replacement
- Corpus Readers and Custom Corpora
- Basics of Part-of-Speech (POS) Tagging
- Natural Language Toolkit - Unigram Tagger
- Natural Language Toolkit - Combining Taggers
- Natural Language Toolkit - More NLTK Taggers
- Natural Language Toolkit - Parsing
- Chunking & Information Extraction
- Natural Language Toolkit - Transforming Chunks
- Natural Language Toolkit - Transforming Trees
- Natural Language Toolkit - Text Classification
- Natural Language Toolkit Resources
- Natural Language Toolkit - Quick Guide
- Natural Language Toolkit - Useful Resources
- Natural Language Toolkit - Discussion
Basics of Part-of-Speech (POS) Tagging
What is POS tagging?
Tagging, a kind of classification, is the automatic assignment of the description of the tokens. We call the descriptor s tag, which represents one of the parts of speech (nouns, verb, adverbs, adjectives, pronouns, conjunction and their sub-categories), semantic information and so on.
On the other hand, if we talk about Part-of-Speech (POS) tagging, it may be defined as the process of converting a sentence in the form of a list of words, into a list of tuples. Here, the tuples are in the form of (word, tag). We can also call POS tagging a process of assigning one of the parts of speech to the given word.
Following table represents the most frequent POS notification used in Penn Treebank corpus −
| Sr.No | Tag | Description |
|---|---|---|
| 1 | NNP | Proper noun, singular |
| 2 | NNPS | Proper noun, plural |
| 3 | PDT | Pre determiner |
| 4 | POS | Possessive ending |
| 5 | PRP | Personal pronoun |
| 6 | PRP$ | Possessive pronoun |
| 7 | RB | Adverb |
| 8 | RBR | Adverb, comparative |
| 9 | RBS | Adverb, superlative |
| 10 | RP | Particle |
| 11 | SYM | Symbol (mathematical or scientific) |
| 12 | TO | to |
| 13 | UH | Interjection |
| 14 | VB | Verb, base form |
| 15 | VBD | Verb, past tense |
| 16 | VBG | Verb, gerund/present participle |
| 17 | VBN | Verb, past |
| 18 | WP | Wh-pronoun |
| 19 | WP$ | Possessive wh-pronoun |
| 20 | WRB | Wh-adverb |
| 21 | # | Pound sign |
| 22 | $ | Dollar sign |
| 23 | . | Sentence-final punctuation |
| 24 | , | Comma |
| 25 | : | Colon, semi-colon |
| 26 | ( | Left bracket character |
| 27 | ) | Right bracket character |
| 28 | " | Straight double quote |
| 29 | ' | Left open single quote |
| 30 | " | Left open double quote |
| 31 | ' | Right close single quote |
| 32 | " | Right open double quote |
Example
Let us understand it with a Python experiment −
import nltk from nltk import word_tokenize sentence = "I am going to school" print (nltk.pos_tag(word_tokenize(sentence)))
Output
[('I', 'PRP'), ('am', 'VBP'), ('going', 'VBG'), ('to', 'TO'), ('school', 'NN')]
Why POS tagging?
POS tagging is an important part of NLP because it works as the prerequisite for further NLP analysis as follows −
- Chunking
- Syntax Parsing
- Information extraction
- Machine Translation
- Sentiment Analysis
- Grammar analysis & word-sense disambiguation
TaggerI - Base class
All the taggers reside in NLTKs nltk.tag package. The base class of these taggers is TaggerI, means all the taggers inherit from this class.
Methods − TaggerI class have the following two methods which must be implemented by all its subclasses −
tag() method − As the name implies, this method takes a list of words as input and returns a list of tagged words as output.
evaluate() method − With the help of this method, we can evaluate the accuracy of the tagger.
The Baseline of POS Tagging
The baseline or the basic step of POS tagging is Default Tagging, which can be performed using the DefaultTagger class of NLTK. Default tagging simply assigns the same POS tag to every token. Default tagging also provides a baseline to measure accuracy improvements.
DefaultTagger class
Default tagging is performed by using DefaultTagging class, which takes the single argument, i.e., the tag we want to apply.
How does it work?
As told earlier, all the taggers are inherited from TaggerI class. The DefaultTagger is inherited from SequentialBackoffTagger which is a subclass of TaggerI class. Let us understand it with the following diagram −
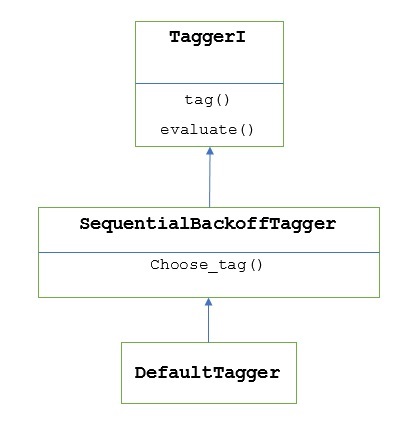
As being the part of SeuentialBackoffTagger, the DefaultTagger must implement choose_tag() method which takes the following three arguments.
- Tokens list
- Current tokens index
- Previous tokens list, i.e., the history
Example
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
exptagger.tag(['Tutorials','Point'])
Output
[('Tutorials', 'NN'), ('Point', 'NN')]
In this example, we chose a noun tag because it is the most common types of words. Moreover, DefaultTagger is also most useful when we choose the most common POS tag.
Accuracy evaluation
The DefaultTagger is also the baseline for evaluating accuracy of taggers. That is the reason we can use it along with evaluate() method for measuring accuracy. The evaluate() method takes a list of tagged tokens as a gold standard to evaluate the tagger.
Following is an example in which we used our default tagger, named exptagger, created above, to evaluate the accuracy of a subset of treebank corpus tagged sentences −
Example
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
from nltk.corpus import treebank
testsentences = treebank.tagged_sents() [1000:]
exptagger.evaluate (testsentences)
Output
0.13198749536374715
The output above shows that by choosing NN for every tag, we can achieve around 13% accuracy testing on 1000 entries of the treebank corpus.
Tagging a list of sentences
Rather than tagging a single sentence, the NLTKs TaggerI class also provides us a tag_sents() method with the help of which we can tag a list of sentences. Following is the example in which we tagged two simple sentences
Example
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
exptagger.tag_sents([['Hi', ','], ['How', 'are', 'you', '?']])
Output
[
[
('Hi', 'NN'),
(',', 'NN')
],
[
('How', 'NN'),
('are', 'NN'),
('you', 'NN'),
('?', 'NN')
]
]
In the above example, we used our earlier created default tagger named exptagger.
Un-tagging a sentence
We can also un-tag a sentence. NLTK provides nltk.tag.untag() method for this purpose. It will take a tagged sentence as input and provides a list of words without tags. Let us see an example −
Example
import nltk
from nltk.tag import untag
untag([('Tutorials', 'NN'), ('Point', 'NN')])
Output
['Tutorials', 'Point']
