- Natural Language Toolkit - Home
- Natural Language Toolkit - Introduction
- Natural Language Toolkit - Getting Started
- Natural Language Toolkit - Tokenizing Text
- Training Tokenizer & Filtering Stopwords
- Looking up words in Wordnet
- Stemming & Lemmatization
- Natural Language Toolkit - Word Replacement
- Synonym & Antonym Replacement
- Corpus Readers and Custom Corpora
- Basics of Part-of-Speech (POS) Tagging
- Natural Language Toolkit - Unigram Tagger
- Natural Language Toolkit - Combining Taggers
- Natural Language Toolkit - More NLTK Taggers
- Natural Language Toolkit - Parsing
- Chunking & Information Extraction
- Natural Language Toolkit - Transforming Chunks
- Natural Language Toolkit - Transforming Trees
- Natural Language Toolkit - Text Classification
- Natural Language Toolkit Resources
- Natural Language Toolkit - Quick Guide
- Natural Language Toolkit - Useful Resources
- Natural Language Toolkit - Discussion
Chunking & Information Extraction
What is Chunking?
Chunking, one of the important processes in natural language processing, is used to identify parts of speech (POS) and short phrases. In other simple words, with chunking, we can get the structure of the sentence. It is also called partial parsing.
Chunk patterns and chinks
Chunk patterns are the patterns of part-of-speech (POS) tags that define what kind of words made up a chunk. We can define chunk patterns with the help of modified regular expressions.
Moreover, we can also define patterns for what kind of words should not be in a chunk and these unchunked words are known as chinks.
Implementation example
In the example below, along with the result of parsing the sentence the book has many chapters, there is a grammar for noun phrases that combines both a chunk and a chink pattern −
import nltk
sentence = [
("the", "DT"),
("book", "NN"),
("has","VBZ"),
("many","JJ"),
("chapters","NNS")
]
chunker = nltk.RegexpParser(
r'''
NP:{<DT><NN.*><.*>*<NN.*>}
}<VB.*>{
'''
)
chunker.parse(sentence)
Output = chunker.parse(sentence)
Output.draw()
Output
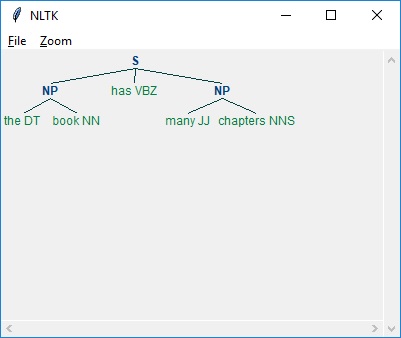
As seen above, the pattern for specifying a chunk is to use curly braces as follows −
{<DT><NN>}
And to specify a chink, we can flip the braces such as follows −
}<VB>{.
Now, for a particular phrase type, these rules can be combined into a grammar.
Information Extraction
We have gone through taggers as well as parsers that can be used to build information extraction engine. Let us see a basic information extraction pipeline −
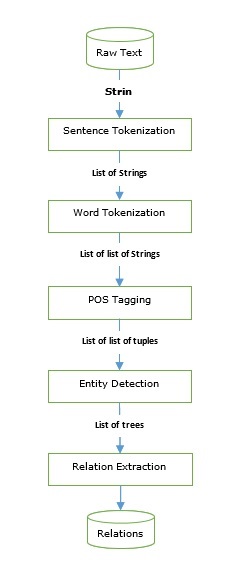
Information extraction has many applications including −
- Business intelligence
- Resume harvesting
- Media analysis
- Sentiment detection
- Patent search
- Email scanning
Named-entity recognition (NER)
Named-entity recognition (NER) is actually a way of extracting some of most common entities like names, organizations, location, etc. Let us see an example that took all the preprocessing steps such as sentence tokenization, POS tagging, chunking, NER, and follows the pipeline provided in the figure above.
Example
Import nltk file = open ( # provide here the absolute path for the file of text for which we want NER ) data_text = file.read() sentences = nltk.sent_tokenize(data_text) tokenized_sentences = [nltk.word_tokenize(sentence) for sentence in sentences] tagged_sentences = [nltk.pos_tag(sentence) for sentence in tokenized_sentences] for sent in tagged_sentences: print nltk.ne_chunk(sent)
Some of the modified Named-entity recognition (NER) can also be used to extract entities such as product names, bio-medical entities, brand name and much more.
Relation extraction
Relation extraction, another commonly used information extraction operation, is the process of extracting the different relationships between various entities. There can be different relationships like inheritance, synonyms, analogous, etc., whose definition depends on the information need. For example, suppose if we want to look for write of a book then the authorship would be a relation between the author name and book name.
Example
In the following example, we use the same IE pipeline, as shown in the above diagram, that we used till Named-entity relation (NER) and extend it with a relation pattern based on the NER tags.
import nltk
import re
IN = re.compile(r'.*\bin\b(?!\b.+ing)')
for doc in nltk.corpus.ieer.parsed_docs('NYT_19980315'):
for rel in nltk.sem.extract_rels('ORG', 'LOC', doc, corpus = 'ieer',
pattern = IN):
print(nltk.sem.rtuple(rel))
Output
[ORG: 'WHYY'] 'in' [LOC: 'Philadelphia'] [ORG: 'McGlashan & Sarrail'] 'firm in' [LOC: 'San Mateo'] [ORG: 'Freedom Forum'] 'in' [LOC: 'Arlington'] [ORG: 'Brookings Institution'] ', the research group in' [LOC: 'Washington'] [ORG: 'Idealab'] ', a self-described business incubator based in' [LOC: 'Los Angeles'] [ORG: 'Open Text'] ', based in' [LOC: 'Waterloo'] [ORG: 'WGBH'] 'in' [LOC: 'Boston'] [ORG: 'Bastille Opera'] 'in' [LOC: 'Paris'] [ORG: 'Omnicom'] 'in' [LOC: 'New York'] [ORG: 'DDB Needham'] 'in' [LOC: 'New York'] [ORG: 'Kaplan Thaler Group'] 'in' [LOC: 'New York'] [ORG: 'BBDO South'] 'in' [LOC: 'Atlanta'] [ORG: 'Georgia-Pacific'] 'in' [LOC: 'Atlanta']
In the above code, we have used an inbuilt corpus named ieer. In this corpus, the sentences are tagged till Named-entity relation (NER). Here we only need to specify the relation pattern that we want and the kind of NER we want the relation to define. In our example, we defined relationship between an organization and a location. We extracted all the combinations of these patterns.
