
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
Improving model accuracy with cross validation technique
Introduction
Cross Validation (CV) is a way of training machine learning models in which multiple models are trained on a part of the data and then accessing their performance or testing them on a independent unseen set of data. In the Cross-validation technique, we generally split the original train data into different parts iteratively so that the algorithm trains and validates itself on each portion of the data none of them are left out in the process
In this article let us have a deep good understanding of the Cross-Validation technique and its significance in improving Model accuracy.
Cross Validation (CV)
Cross Validation is the go-to technique to improve accuracy in many cases however it is very useful when the data is limited. It prevents the model from overfitting as it uses the rotation scheme of sampling data and using the parts to train several models and choose the best model. The original data is sampled randomly and divided into different subsets of data. Then the model is tested on all the subsets leaving one that is used for assessing the model's performance or simply testing. In some cases, we can have several rounds of cross-validation and the mean of the final results is taken.
What is the Importance of Cross Validation?
Cross Validation is highly important in terms of improving the accuracy of the model. This fact is generally evident when the dataset is small. Let us for example take the probability of predicting an earthquake. For this case, we need data such as Latitude, Longitude, date of occurrence, Depth, Error in Depth, Location source, magnitude source, magnitude type, etc. To determine the probability of an earthquake occurring we need to train the model and as well as test it. Since the dataset is small, if all the data is used for training, the model will learn all the variations and even noise and overfit. There will be no data left for testing the model performance. In the real scenario, we may get variations of unseen data while using the prediction model, so it may not perform well in that case.
The solution to the problem is using Cross Validation, which is a random resampling technique of dividing the dataset into multiple subsets which are popularly known as k-fold cross-validation where k represents the number of subsets like 5,10, etc. In cross-validation, the model is trained on all the subsets except one which is used for testing. The testing set is completely unseen data that can be used to correctly evaluate the model.
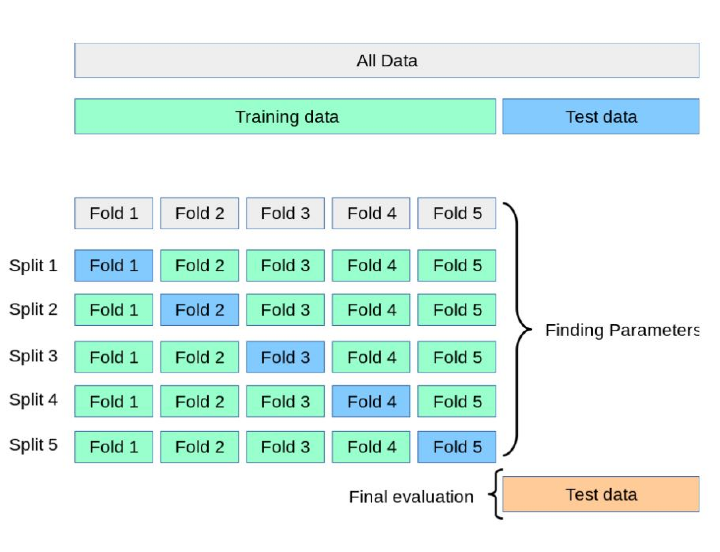
Types of Cross-Validation
They are of two types - exhaustive and non-exhaustive. In an exhaustive strategy, all techniques are applied to divide the dataset into training and testing subsets by applying all the combinations. However, in non-exhaustive innovative ways are not used to split the dataset.
Holdout
In this type of cross-validation, the initial dataset is only divided into two parts - the training subset and the testing subset. The model is trained on the training set and evaluated on the testing set. It is a kind of non-exhaustive approach. For example, the dataset can be split into a 70:30 ratio or 75:25, etc. Here the results may vary when each time it is trained since the combinations of data points vary. This method is generally used when the dataset is large or there is a time constraint to train the model fast and get the results as quickly as possible.
K-Fold
It is a better method as compared to holdout as it is a superior improvement over the holdout method. It is non-exhausting and does not depend on how the dataset is split for intro train and test subsets. The K in K-fold represents the number of folds or partitions of the dataset., For example 5-fold,10-fold, etc.
In K-fold, the model is trained on all K-1 subsets of data and is tested for performance on the kth subset. This process is continued till each of the folds is utilized as a validation set at least once. After K folds of iteration, the model the average of the model results is taken.
The K- fold model helps in reducing the bias and boosting accuracy since each dataset gets a chance to serve as both a training and testing set. However, the process of K-fold Cross Validation may a little time-consuming.
K-Fold Stratified Approach
In K-fold cross we may come across a problem since the method randomly samples the data with shuffling and splitting, and a dataset may become imbalanced. Let us understand it with an example.
If let us suppose we have to classify emails as Spam and Not spam. It might happen in K-Fold cross-validation that In one fold we may get more emails of the Spam category and less representation for Non-Spam and this may produce biased results which evaluation.
To tackle this issue a strategy named stratification is used where, where it is ensured that each split or subset has an equal number of both the classes ( or N classes in case of multiclass classification). This is the idea behind Stratified K-fold.
Implementation of Cross-Validation Technique
from sklearn import datasets
from sklearn.model_selection import KFold, cross_val_score
from sklearn.tree import DecisionTreeClassifier as DTC
x_train, y_train = datasets.load_iris(return_X_y=True)
model = DTC(random_state=1)
foldsK = KFold(n_splits = 10)
s = cross_val_score(model, x_train, y_train, cv = foldsK)
print("Scores CV", s)
print("Avg CV score: ", s.mean())
print("No of CV scores used in Avg: ", len(s))
Output
Scores CV [1. 1. 1. 0.93333333 0.93333333 0.86666667 1. 0.86666667 0.86666667 1. ] Avg CV score: 0.9466666666666667 No of CV scores used in Avg: 10
Conclusion
Cross Validation is a highly efficient and popular technique for training Machine Learning models. It gives a big boost to the overall performance and accuracy of the model just the way how its splits and uses the dataset efficiently. It is essential to apply this technique to each Machine Learning process to ensure a better model output with improved accuracy.

454 Views
