- Impala - Home
- Impala - Overview
- Impala - Environment
- Impala - Architecture
- Impala - Shell
- Impala - Query Language Basics
- Table Specific Statements
- Impala - Create Table Statement
- Impala - Insert Statement
- Impala - Select Statement
- Impala - Describe Statement
- Impala - Alter Table
- Impala - Drop a Table
- Impala - Truncate a Table
- Impala - Show Tables
- Impala - Create View
- Impala - Alter View
- Impala - Drop a View
- Impala - Clauses
- Impala - Order By Clause
- Impala - Group By Clause
- Impala - Having Clause
- Impala - Limit Clause
- Impala - Offset Clause
- Impala - Union Clause
- Impala - With Clause
- Impala - Distinct Operator
- Impala Useful Resources
- Impala - Quick Guide
- Impala - Useful Resources
- Impala - Discussion
Impala - Architecture
Impala is an MPP (Massive Parallel Processing) query execution engine that runs on a number of systems in the Hadoop cluster. Unlike traditional storage systems, impala is decoupled from its storage engine. It has three main components namely, Impala daemon (Impalad), Impala Statestore, and Impala metadata or metastore.
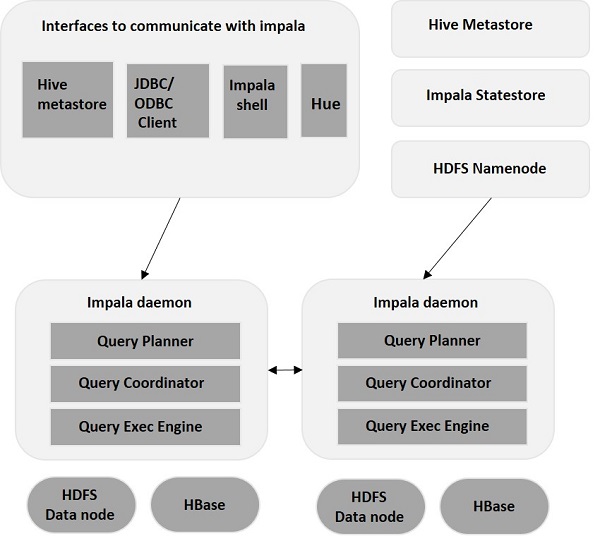
Impala daemon(Impalad)
Impala daemon (also known as impalad) runs on each node where Impala is installed. It accepts the queries from various interfaces like impala shell, hue browser, etc. and processes them.
Whenever a query is submitted to an impalad on a particular node, that node serves as a coordinator node for that query. Multiple queries are served by Impalad running on other nodes as well. After accepting the query, Impalad reads and writes to data files and parallelizes the queries by distributing the work to the other Impala nodes in the Impala cluster. When queries are processing on various Impalad instances, all of them return the result to the central coordinating node.
Depending on the requirement, queries can be submitted to a dedicated Impalad or in a load balanced manner to another Impalad in your cluster.
Impala State Store
Impala has another important component called Impala State store, which is responsible for checking the health of each Impalad and then relaying each Impala daemon health to the other daemons frequently. This can run on same node where Impala server or other node within the cluster is running.
The name of the Impala State store daemon process is State stored. Impalad reports its health status to the Impala State store daemon, i.e., State stored.
In the event of a node failure due to any reason, Statestore updates all other nodes about this failure and once such a notification is available to the other impalad, no other Impala daemon assigns any further queries to the affected node.
Impala Metadata & Meta Store
Impala metadata & meta store is another important component. Impala uses traditional MySQL or PostgreSQL databases to store table definitions. The important details such as table & column information & table definitions are stored in a centralized database known as a meta store.
Each Impala node caches all of the metadata locally. When dealing with an extremely large amount of data and/or many partitions, getting table specific metadata could take a significant amount of time. So, a locally stored metadata cache helps in providing such information instantly.
When a table definition or table data is updated, other Impala daemons must update their metadata cache by retrieving the latest metadata before issuing a new query against the table in question.
Query Processing Interfaces
To process queries, Impala provides three interfaces as listed below.
Impala-shell − After setting up Impala using the Cloudera VM, you can start the Impala shell by typing the command impala-shell in the editor. We will discuss more about the Impala shell in coming chapters.
Hue interface − You can process Impala queries using the Hue browser. In the Hue browser, you have Impala query editor where you can type and execute the impala queries. To access this editor, first of all, you need to logging to the Hue browser.
ODBC/JDBC drivers − Just like other databases, Impala provides ODBC/JDBC drivers. Using these drivers, you can connect to impala through programming languages that supports these drivers and build applications that process queries in impala using those programming languages.
Query Execution Procedure
Whenever users pass a query using any of the interfaces provided, this is accepted by one of the Impalads in the cluster. This Impalad is treated as a coordinator for that particular query.
After receiving the query, the query coordinator verifies whether the query is appropriate, using the Table Schema from the Hive meta store. Later, it collects the information about the location of the data that is required to execute the query, from HDFS name node and sends this information to other impalads in order to execute the query.
All the other Impala daemons read the specified data block and processes the query. As soon all the daemons complete their tasks, the query coordinator collects the result back and delivers it to the user.
