
 Data Structure
Data Structure Networking
Networking RDBMS
RDBMS Operating System
Operating System Java
Java MS Excel
MS Excel iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C Programming
C Programming C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP
- Selected Reading
- UPSC IAS Exams Notes
- Developer's Best Practices
- Questions and Answers
- Effective Resume Writing
- HR Interview Questions
- Computer Glossary
- Who is Who
Generalization, Specialization and Aggregation in ER Model
Generalization
Generalization is a process of generalizing an entity which contains generalized attributes or properties of generalized entities. The entity that is created will contain the common features. Generalization is a Bottom up process.
We can have three sub entities as Car, Truck, Motorcycle and these three entities can be generalized into one general super class as Vehicle.
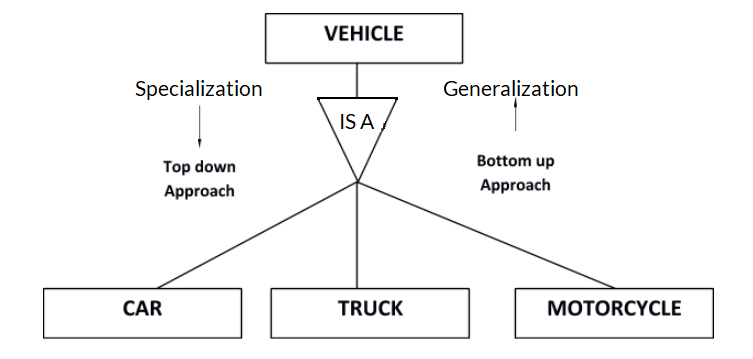
It is a form of abstraction that specifies two or more entities (sub class) having common characters that can be generalized into one single entity (super class) at higher level hiding all the differences.
Specialization
Specialization is a process of identifying subsets of an entity that shares different characteristics. It breaks an entity into multiple entities from higher level (super class) to lower level (sub class). The breaking of higher level entity is based on some distinguishing characteristics of the entities in super class.
It is a top down approach in which we first define the super class and then sub class and then their attributes and relationships.
Aggregation
Aggregation represents relationship between a whole object and its component. Using aggregation we can express relationship among relationships. Aggregation shows ‘has-a’ or ‘is-part-of’ relationship between entities where one represents the ‘whole’ and other ‘part’.
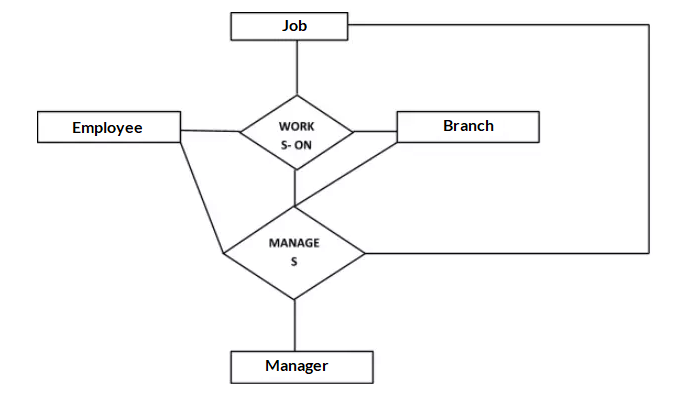
Consider a ternary relationship Works_On between Employee, Branch and Manager. Now the best way to model this situation is to use aggregation, So, the relationship-set, Works_On is a higher level entity-set. Such an entity-set is treated in the same manner as any other entity-set. We can create a binary relationship, Manager, between Works_On and Manager to represent who manages what tasks.

21K+ Views
